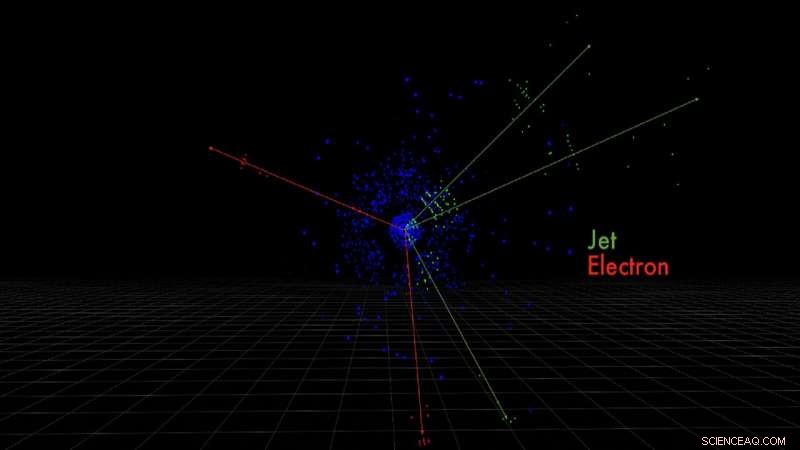
Ce sont les pixels détecteurs d'électrons et de jets de quarks produits par une collision de protons simulée, mesurée par le détecteur ATLAS. Crédit : Taylor Childers
Alors que la physique des hautes énergies et la cosmologie semblent des mondes à part en termes d'échelle, les physiciens et les cosmologues d'Argonne utilisent des méthodes d'apprentissage automatique similaires pour résoudre les problèmes de classification des particules subatomiques et des galaxies.
La physique des hautes énergies et la cosmologie semblent des mondes à part en termes d'échelle, mais les composants invisibles qui composent le champ de l'un informent la composition et la dynamique de l'autre :les étoiles qui s'effondrent, nébuleuses stellaires et, peut-être, matière noire.
Depuis des décennies, les techniques par lesquelles les chercheurs des deux domaines étudiaient leurs domaines semblaient presque incompatibles, également. La physique des hautes énergies s'est appuyée sur des accélérateurs et des détecteurs pour tirer des enseignements des interactions énergétiques des particules, tandis que les cosmologistes regardaient à travers toutes sortes de télescopes pour dévoiler les secrets de l'univers.
Bien que ni l'un ni l'autre n'aient renoncé à l'équipement fondamental de leur domaine particulier, Les physiciens et cosmologistes du laboratoire national d'Argonne du département américain de l'Énergie (DOE) s'attaquent à des problèmes complexes à plusieurs échelles en utilisant diverses formes d'une technique d'intelligence artificielle appelée apprentissage automatique.
Déjà utilisé dans de nombreux domaines, L'apprentissage automatique peut aider à identifier des modèles cachés en apprenant à partir des données d'entrée et en améliorant progressivement les prédictions concernant les nouvelles données. Il peut être appliqué à des tâches de classification visuelle ou à la reproduction rapide de calculs compliqués et coûteux en temps de calcul.
Avec le potentiel de transformer radicalement la façon dont la science est conduite, ces techniques d'IA nous aideront à mieux comprendre la répartition des galaxies dans l'univers ou à mieux visualiser la formation de nouvelles particules à partir desquelles nous pourrions déduire une nouvelle physique.
"Au cours des décennies, nous avons développé des algorithmes traditionnels qui reconstituent les signatures des différentes particules qui nous intéressent, " a déclaré Taylor Childers, physicien des particules et informaticien à l'Argonne Leadership Computing Facility (ALCF), une installation utilisateur du DOE Office of Science.
"Il a fallu beaucoup de temps pour les développer et ils sont très précis, " ajouta-t-il. " Mais en même temps, il serait intéressant de savoir si les techniques de classification d'images issues de l'apprentissage automatique qui ont été utilisées avec succès par Google et Facebook peuvent simplifier ou raccourcir le développement d'algorithmes qui identifient les signatures de particules dans nos détecteurs 3D."
Childers travaille avec des physiciens des hautes énergies d'Argonne, qui sont tous membres de la collaboration expérimentale ATLAS au Grand collisionneur de hadrons (LHC) du CERN, le plus grand et le plus puissant collisionneur de particules au monde. Vous cherchez à résoudre un large éventail de problèmes de physique, le détecteur ATLAS mesure huit étages et 150 pieds de long à un point situé autour de l'anneau du collisionneur de 17 milles de circonférence du LHC, où il mesure les produits des protons entrant en collision à des vitesses proches de la vitesse de la lumière.
Selon le site Web d'ATLAS, "plus d'un milliard d'interactions de particules ont lieu dans le détecteur ATLAS chaque seconde, un débit de données équivalent à 20 conversations téléphoniques simultanées tenues par chaque personne sur la terre."
Bien que seul un petit pourcentage de ces collisions soient jugés dignes d'étude (environ un million par seconde), cela fournit toujours une montagne de données aux scientifiques à étudier.
Ces collisions de particules à grande vitesse créent de nouvelles particules dans leur sillage, comme les électrons ou les gerbes de quarks, chacun laissant une signature unique dans le détecteur. Ce sont ces signatures que Childers aimerait identifier grâce à l'apprentissage automatique.
L'un des défis consiste à capturer ces signatures énergétiques sous forme d'images dans un espace 3D complexe. Une photo, par exemple, est essentiellement une représentation 2-D de données 3-D avec des positions verticales et horizontales. Les données de pixels, les couleurs de l'image, sont orientés spatialement et contiennent des informations spatiales codées - par exemple, les yeux d'un chat sont à côté du nez, et les oreilles sont en haut à gauche et à droite.
« Donc, leur orientation spatiale est importante. Il en va de même pour les images que nous prenons au LHC. Lorsqu'une particule traverse notre détecteur, il laisse une signature énergétique dans des motifs spatiaux spécifiques aux différentes particules, " expliqua Childers.
Ajoutez à cela la quantité de données encodées non seulement dans les signatures, mais l'espace 3-D autour d'eux. Où les exemples traditionnels d'apprentissage automatique pour la reconnaissance d'images - ces chats, encore une fois - traiter des centaines de milliers de pixels, Les images d'ATLAS contiennent des centaines de millions de pixels détecteurs.
Alors l'idée, il a dit, est de traiter les images du détecteur comme des images traditionnelles. À l'aide d'une technique d'apprentissage automatique appelée réseaux de neurones convolutifs, qui apprennent comment les données sont spatialement liées, ils peuvent extraire l'espace 3D pour identifier plus facilement des caractéristiques de particules spécifiques.

L'image montre un anneau d'Einstein (au milieu à droite) formé par la lentille gravitationnelle d'une galaxie en formation d'étoiles (bleu) par une galaxie rouge lumineuse massive (orange). Ce système a été découvert pour la première fois par le Sloan Digital Sky Survey en 2007; les images proviennent du télescope spatial Hubble. Crédit :NASA
Childers espère que ces algorithmes d'apprentissage automatique remplaceront à terme les algorithmes traditionnels fabriqués à la main, réduisant considérablement le temps nécessaire pour traiter des quantités similaires de données et améliorant la précision des résultats mesurés.
« Nous pouvons également remplacer le développement d'une décennie nécessaire pour les nouveaux détecteurs et le réduire par de nouveaux modèles de formation pour les futurs détecteurs, " il a dit.
Un espace plus grand
Les cosmologistes d'Argonne utilisent des méthodes d'apprentissage automatique similaires pour résoudre les problèmes de classification, mais à une échelle beaucoup plus grande.
"Le problème avec la cosmologie est que les objets que nous regardons sont compliqués et flous, " a déclaré Salman Habib, Directeur de division de la division Computational Science d'Argonne et directeur adjoint par intérim de sa division Physique des hautes énergies. "Donc, décrire les données d'une manière plus simple devient très difficile."
Lui et ses collègues utilisent des superordinateurs à Argonne et d'autres laboratoires nationaux du DOE pour reconstruire les détails de l'univers, galaxie par galaxie. Ils créent des catalogues de galaxies simulées très détaillés qui peuvent être utilisés pour la comparaison avec des données réelles prises à partir de télescopes d'enquête, comme le grand télescope d'enquête synoptique, un partenariat entre le DOE et la National Science Foundation.
Mais pour rendre ces atouts précieux pour les chercheurs, ils doivent être aussi proches que possible de la réalité.
Algorithmes d'apprentissage automatique, Habib a dit, sont très doués pour sélectionner des caractéristiques qui peuvent être facilement caractérisées par la géométrie, comme ces chats. Encore, similaire à l'avertissement sur les rétroviseurs du véhicule, les objets dans les cieux ne sont pas toujours tels qu'ils apparaissent.
Prenez le phénomène de lentille gravitationnelle forte; la distorsion d'une source lumineuse de fond - une galaxie ou un amas de galaxies - par une masse intermédiaire. La déviation des trajectoires des rayons lumineux de la source due à la gravité conduit à une distorsion de la forme de la source de fond, position et orientation; cette distorsion renseigne sur la répartition de masse de l'objet intervenant. La situation d'observation réelle n'est pas si simple, toutefois.
Une goutte complètement ronde qui est lentille, par exemple, peut sembler étiré dans un sens ou dans un autre, pendant un tour, un objet en forme de disque sans lentille peut sembler elliptique s'il est vu partiellement sur le bord.
"Alors, comment savez-vous si l'objet que vous regardez n'est pas un objet rond qui a été tourné, ou celui qui a été pris en compte ?", a demandé Habib. « Ce sont le genre de choses délicates que l'apprentissage automatique doit être capable de comprendre. »
Pour faire ça, les chercheurs créent un échantillon d'apprentissage de millions d'objets d'aspect réaliste, dont la moitié sont lentilles. Les algorithmes d'apprentissage automatique tentent ensuite d'apprendre les différences entre les objets avec et sans lentille. Les résultats sont vérifiés par rapport à un ensemble connu d'objets synthétiques à lentilles et sans lentilles.
Mais les résultats ne disent que la moitié de l'histoire :à quel point les algorithmes fonctionnent bien sur les données de test. Pour améliorer encore leur précision pour les données réelles, les chercheurs mélangent un certain pourcentage de données synthétiques avec des données précédemment observées et exécutent les algorithmes, de nouveau, comparant à quel point ils ont choisi des objets à lentille dans l'échantillon d'apprentissage par rapport aux données combinées.
"À la fin, vous pourriez trouver qu'il fait assez bien, mais peut-être pas aussi bien que tu le souhaites, " a expliqué Habib. " Vous pourriez dire 'OK, cette information à elle seule ne sera pas suffisante, J'ai besoin d'en ramasser plus.' C'est un processus assez long et complexe."
Deux objectifs principaux de la cosmologie moderne, il a dit, sont de comprendre pourquoi l'expansion de l'univers s'accélère et quelle est la nature de la matière noire. La matière noire est environ cinq fois plus abondante que la matière normale, mais son origine ultime reste mystérieuse. Afin de se rapprocher à distance d'une réponse, la science doit être très délibérée, tres précis.
« Au stade actuel, Je ne pense pas que nous puissions résoudre tous nos problèmes avec des applications d'apprentissage automatique, " a admis Habib. " Mais je dirais que l'apprentissage automatique sera très important pour tous les aspects de la cosmologie de précision dans un avenir proche. "
Au fur et à mesure que les techniques d'apprentissage automatique sont développées et affinées, leur utilité à la fois pour la physique des hautes énergies et la cosmologie ne manquera pas de croître de façon exponentielle, offrant l'espoir de nouvelles découvertes ou de nouvelles interprétations qui modifient notre compréhension du monde à de multiples échelles.