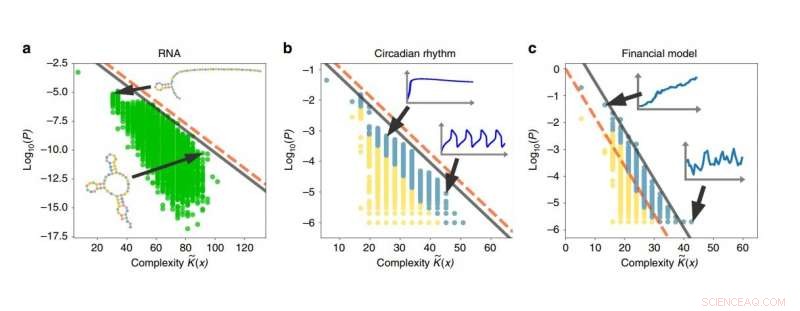
Exemples de biais de simplicité dans les séquences d'ARN, rythmes circadiens, et modèles financiers. Plus la complexité d'une sortie est élevée, plus la probabilité que la sortie soit générée est faible. Crédit :Dingle, et al. Publié dans Communication Nature
Les chercheurs ont découvert que les cartes entrées-sorties, qui sont largement utilisés dans la science et l'ingénierie pour modéliser des systèmes allant de la physique à la finance, sont fortement orientés vers la production de sorties simples. Les résultats sont surprenants, comme naïvement, il n'y a aucune raison de penser qu'un résultat devrait être plus probable qu'un autre.
Les chercheurs, Kamaludin Dingle, Chico Q. Camargo, et Ard A. Louis, à l'Université d'Oxford et à la Gulf University for Science and Technology, ont publié un article sur leurs résultats dans un récent numéro de Communication Nature .
« La plus grande importance de notre travail est notre prédiction selon laquelle le biais de simplicité - que les sorties simples sont exponentiellement plus susceptibles d'être générées que les sorties complexes - est valable pour une grande variété de systèmes en science et en ingénierie, " dit Louis Phys.org . "Le biais de simplicité implique que, pour un système composé de nombreuses parties différentes en interaction, disons, un circuit avec de nombreux composants, un réseau avec de nombreuses réactions chimiques, etc.—la plupart des combinaisons de paramètres et d'entrées devraient aboutir à un comportement simple."
Le travail s'inspire du domaine de la théorie algorithmique de l'information (AIT), qui traite des liens entre l'informatique et la théorie de l'information. Un résultat important de l'AIT est le théorème de codage. D'après ce théorème, lorsqu'une machine de Turing universelle (un appareil informatique abstrait qui peut calculer n'importe quelle fonction) reçoit une entrée aléatoire, les sorties simples ont une probabilité exponentiellement plus élevée d'être générées que les sorties complexes. Comme l'expliquent les chercheurs, ce résultat est complètement en contradiction avec l'attente naïve selon laquelle toutes les sorties sont également probables.
Malgré ces découvertes intrigantes, jusqu'à présent, le théorème de codage a rarement été appliqué à des systèmes du monde réel. C'est parce que le théorème n'a été formulé que de manière très abstraite, et l'un de ses composants clés, une mesure de la complexité appelée complexité de Kolmogorov, est incalculable.
"Le théorème de codage de Solomonoff et Levin est un résultat remarquable qui devrait vraiment être beaucoup plus connu, " a déclaré Louis. " Il prédit que les sorties à faible complexité sont exponentiellement plus susceptibles d'être générées par une machine de Turing universelle (UTM) que les sorties à haute complexité. Puisque tout ce qui est calculable peut être calculé sur un UTM, c'est une prédiction assez étonnante!
"Toutefois, le théorème de codage est resté obscur car les UTM sont plutôt abstraits, car il ne peut être prouvé que dans la limite asymptotique des grandes complexités, et parce que la mesure de Kolmogorov utilisée pour déterminer la complexité est fondamentalement incalculable. Notre travail contourne ces problèmes en utilisant une version légèrement plus faible du théorème de codage qui est beaucoup plus facile à appliquer."
Dans le neuf, version plus faible du théorème de codage, les chercheurs ont remplacé la complexité de Kolmogorov par une complexité d'approximation, qui est calculable, tout en préservant la préférence exponentielle pour la simplicité. Le théorème de codage le plus faible peut être facilement appliqué pour faire des prédictions concernant des systèmes pratiques.
"Nous utilisons le langage des cartes d'entrées-sorties, ce qui peut sembler assez abstrait, " dit Louis. " Cependant, de nombreux systèmes étudiés en science et en ingénierie convertissent une sorte d'entrée en une sorte de sortie grâce à un algorithme. Par exemple, l'information codée dans l'ADN d'un organisme (son génotype) pourrait être vue comme entrée, tandis que les caractéristiques et le comportement de l'organisme (son phénotype) pourraient être considérés comme le résultat. Dans un ensemble d'équations différentielles, l'entrée est les paramètres des équations, et la sortie est la solution de ces équations, étant donné certaines conditions aux limites.
"Nous soutenons que si vous choisissez au hasard des paramètres d'entrée, alors de tels systèmes sont exponentiellement plus susceptibles de produire des sorties simples que des sorties complexes. Étant donné que cette prédiction est valable pour un large éventail de cartes, nous faisons une revendication large. Mais c'est une de ses forces. Notre dérivation ne nécessite pas de savoir grand-chose sur le fonctionnement réel de la carte (ou de l'algorithme) en question.
"La principale signification de notre travail est donc que notre version la plus faible du théorème de codage maintient approximativement le biais exponentiel vers la simplicité du théorème de codage d'origine, mais est beaucoup plus facile à appliquer dans la pratique."
Une conséquence des résultats est qu'il est possible de prédire la probabilité d'un résultat particulier en fonction de sa complexité. Bien qu'une sortie simple soit exponentiellement plus susceptible d'apparaître qu'une sortie complexe, les chercheurs notent que cela ne signifie pas nécessairement que les sorties simples sont plus susceptibles d'apparaître que les sorties complexes en général, car il peut y avoir beaucoup plus de sorties complexes que de simples dans l'ensemble.
Pour illustrer quelques applications, les chercheurs ont utilisé le théorème de codage modifié pour analyser des systèmes de séquences d'ARN, rythmes circadiens, et les marchés financiers, et a montré que tous ces systèmes présentent le biais de simplicité. À l'avenir, ils prévoient également d'appliquer les résultats à des algorithmes informatiques, évolution biologique, et les systèmes chaotiques. Cependant, pour une explication plus intuitive de ce que signifie le biais de simplicité, les chercheurs décrivent un scénario impliquant nos parents primates :
"Considérez le problème bien connu des singes qui tapent sur une machine à écrire, " dit Louis. " Si les singes tapent de manière vraiment aléatoire, et la machine à écrire a N clés, alors la probabilité d'obtenir une séquence particulière de longueur k est juste 1/ N k , puisqu'il y a un 1/ N chance d'obtenir la bonne frappe à chacun des k pas. Ainsi chaque séquence de longueur k est tout aussi probable ou improbable.
"Considérons maintenant le cas où les singes tapent dans un programme informatique. Ils peuvent alors par accident taper un programme court qui génère une sortie longue. Par exemple, il existe un code de 133 caractères dans le langage de programmation C qui génère correctement les 15 premiers, 000 chiffres de . Donc au lieu de 1/ N 15, 000 , quelle est la probabilité pour les singes d'obtenir ce droit sur une machine à écrire, les chances sont beaucoup plus faibles, seulement 1/ N 133 , que les singes génèrent π sur l'ordinateur.
Il s'avère que la plupart des nombres n'ont pas de programmes courts qui les génèrent, donc le mieux que les singes sur l'ordinateur puissent faire pour ces nombres est de taper un programme comme 'print number, ' ce qui est proche de la probabilité qu'ils réussissent de toute façon sur une machine à écrire. Mais pour des sorties simples, la probabilité est beaucoup plus élevée que pour la machine à écrire. Par définition, les sorties simples sont définies comme celles qui ont des programmes courts les décrivant, et les sorties complexes sont celles qui ne peuvent être décrites que par des programmes longs. Donc est, par définition, un nombre de faible complexité, et par conséquent, il est beaucoup plus susceptible d'être généré par des singes tapant dans un programme informatique que de nombreux autres nombres qui ne sont pas simples.
"Ce que fait le théorème de codage, c'est de rendre quantitative cette histoire intuitive. Les programmes courts sont plus susceptibles d'être saisis au hasard, et puisque les probabilités de longueur k les programmes sont également à l'échelle 1/ N k , Les sorties simples sont exponentiellement beaucoup plus susceptibles d'apparaître que les sorties complexes. Notre contribution est de démontrer comment calculer facilement la relation exponentielle entre probabilité et complexité pour de nombreux systèmes pratiques. Ce qui est bien, c'est que vous n'avez pas besoin d'en savoir beaucoup sur la carte (ou de manière équivalente sur l'algorithme) pour déterminer si une sortie est susceptible d'apparaître ou non. En bonne première approximation, plus une sortie est compressible, plus il est probable qu'il apparaisse sur des entrées aléatoires."
© 2018 Phys.org