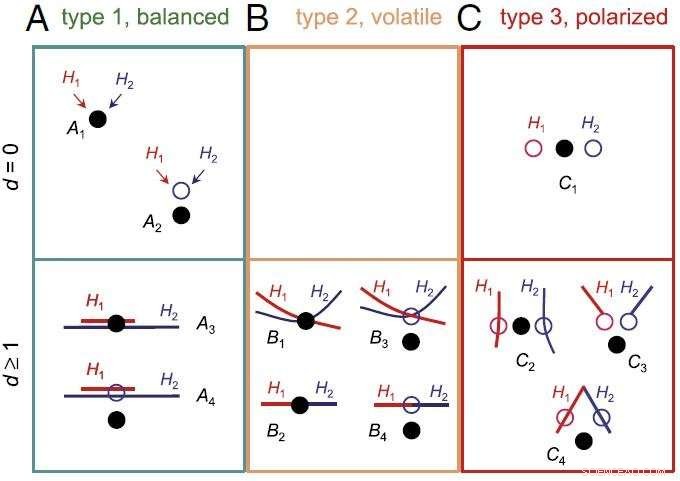
Classification des problèmes bayésiens de sélection de modèles impliquant deux modèles également justes ou également faux. Crédit :ZHU Tianqi
Des scientifiques de l'University College London (UCL) et de l'Academy of Mathematics and Systems Science, Académie chinoise des sciences (CAS, AMSS), ont signalé des progrès dans la compréhension des problèmes associés à la sélection de modèles bayésiens. La recherche suggère que la méthode bayésienne a tendance à produire des probabilités postérieures très élevées pour les arbres évolutifs estimés même si les arbres sont clairement faux, et propose une explication possible de ce phénomène.
La comparaison de modèles est largement utilisée dans diverses branches des sciences dans lesquelles les hypothèses scientifiques sont formulées sous forme de modèles statistiques et testées à l'aide de données observées. Cependant, la comparaison de modèles est une question épineuse à la fois en statistique classique et en statistique bayésienne.
Dans les statistiques classiques, deux modèles imbriqués sont comparés. Le framework ne fonctionne pas lorsque les modèles comparés ne sont pas imbriqués. En revanche, La statistique bayésienne compare différents modèles en calculant leurs probabilités postérieures, ce qui indique notre confiance ou notre croyance dans le modèle.
Non seulement les deux méthodologies découlent de philosophies radicalement différentes, ils peuvent également produire des conclusions opposées dans l'analyse des mêmes données. La sélection de modèles bayésiens est connue pour converger vers le vrai modèle si le vrai modèle est inclus parmi les modèles considérés.
C'est-à-dire, quand les scientifiques collectent plus de données, la probabilité a posteriori du bon modèle augmentera et approchera de 100 %, et ils seront ainsi de plus en plus certains quel est le vrai modèle.
Cependant, si tous les modèles considérés sont faux, le comportement de la méthode bayésienne est inconnu.
Les scientifiques ont caractérisé les problèmes de sélection de modèles bayésiens, et les a classés en trois types, dont chacun montre un comportement différent.
Dans le cas le plus scientifiquement intéressant, c'est à dire., lorsque les modèles comparés sont distincts et presque également faux, La sélection de modèles bayésiens montre un comportement polarisé problématique :elle a tendance à prendre en charge un modèle avec toute sa force dans certains ensembles de données, mais prend en charge un autre modèle dans d'autres ensembles de données.
Le résultat peut être résumé en utilisant l'analogie suivante :supposons que le monde soit gris, mais nous demandons à un sage s'il est noir ou blanc. Il jette un regard profond sur le monde et dit qu'il est noir, en toute confiance. Mais la prochaine fois que nous posons la même question, il dit qu'il est blanc, encore une fois en toute confiance.
Cette étude a été motivée par des problèmes de phylogénétique moléculaire, qui est la science de l'élaboration des relations entre les espèces à l'aide de données génétiques, représentés par des arbres évolutifs.
Ces différents arbres opposent des modèles statistiques dans l'analyse bayésienne des données. Les biologistes évolutionnistes ont longtemps observé que la méthode tend à produire des probabilités postérieures très élevées pour les arbres évolutionnaires estimés (très souvent 100 pour cent), même si les arbres ont clairement tort.
Nos résultats fournissent une explication possible à ce comportement désagréable. Les implications des résultats pour l'utilisation de la sélection de modèles bayésiens dans le test d'hypothèses scientifiques opposées en général doivent encore être explorées.