Crédit :Université des sciences de Tokyo
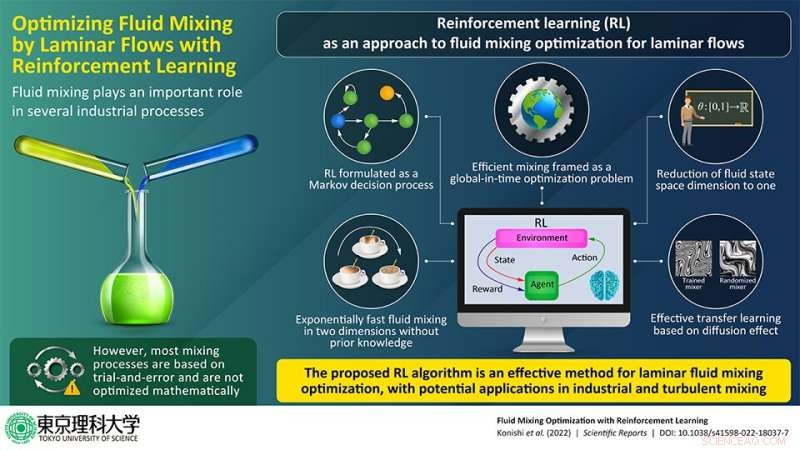
Le mélange de fluides est une partie importante de plusieurs processus industriels et réactions chimiques. Cependant, le processus repose souvent sur des expériences basées sur des essais et des erreurs au lieu d'une optimisation mathématique. Bien que le mélange turbulent soit efficace, il ne peut pas toujours être soutenu et peut endommager les matériaux impliqués. Pour résoudre ce problème, des chercheurs japonais ont maintenant proposé une approche d'optimisation du mélange de fluides pour les écoulements laminaires utilisant l'apprentissage automatique, qui peut également être étendue au mélange turbulent.
Le mélange de fluides est un composant critique dans de nombreux processus industriels et chimiques. Le mélange pharmaceutique et les réactions chimiques, par exemple, peuvent nécessiter un mélange fluide homogène. Réaliser ce mélange plus rapidement et avec moins d'énergie réduirait considérablement les coûts associés. En réalité, cependant, la plupart des processus de mélange ne sont pas optimisés mathématiquement et reposent plutôt sur des méthodes empiriques basées sur des essais et des erreurs. Le mélange turbulent, qui utilise la turbulence pour mélanger les fluides, est une option mais est problématique car il est difficile à maintenir (comme dans les micro-mélangeurs) ou endommage les matériaux mélangés (comme dans les bioréacteurs et les mélangeurs alimentaires).
Peut-on plutôt obtenir un mélange optimisé pour les flux laminaires ? Pour répondre à cette question, une équipe de chercheurs du Japon, dans une nouvelle étude, s'est tournée vers l'apprentissage automatique. Dans leur étude publiée dans Scientific Reports , l'équipe a eu recours à une approche appelée "apprentissage par renforcement" (RL), dans laquelle des agents intelligents prennent des mesures dans un environnement pour maximiser la récompense cumulative (par opposition à une récompense instantanée).
"Étant donné que RL maximise la récompense cumulative, qui est globale dans le temps, on peut s'attendre à ce qu'elle convienne pour résoudre le problème du mélange efficace des fluides, qui est également un problème d'optimisation global dans le temps", explique le professeur associé Masanobu Inubushi. , l'auteur correspondant de l'étude. "Personnellement, j'ai la conviction qu'il est important de trouver le bon algorithme pour le bon problème plutôt que d'appliquer aveuglément un algorithme d'apprentissage automatique. Heureusement, dans cette étude, nous avons réussi à relier les deux domaines (mélange de fluides et apprentissage par renforcement) après compte tenu de leurs caractéristiques physiques et mathématiques." Le travail comprenait des contributions de Mikito Konishi, un étudiant diplômé, et du professeur Susumu Goto, tous deux de l'Université d'Osaka.
Un obstacle majeur attendait l'équipe, cependant. Bien que RL soit adapté aux problèmes d'optimisation globale, il n'est pas particulièrement bien adapté aux systèmes impliquant des espaces d'états de grande dimension, c'est-à-dire des systèmes nécessitant un grand nombre de variables pour leur description. Malheureusement, le mélange de fluides n'était qu'un tel système.
Pour résoudre ce problème, l'équipe a adopté une approche utilisée dans la formulation d'un autre problème d'optimisation, qui leur a permis de réduire à un la dimension de l'espace d'état pour l'écoulement de fluide. En termes simples, le mouvement fluide peut désormais être décrit à l'aide d'un seul paramètre.
L'algorithme RL est généralement formulé en termes de processus de décision de Markov (MDP), un cadre mathématique pour la prise de décision dans des situations où les résultats sont en partie aléatoires et en partie contrôlés par le décideur. En utilisant cette approche, l'équipe a montré que RL était efficace pour optimiser le mélange des fluides.
"Nous avons testé notre algorithme basé sur RL pour le problème de mélange de fluides bidimensionnel et avons constaté que l'algorithme identifiait un contrôle de flux efficace, qui aboutissait à un mélange exponentiellement rapide sans aucune connaissance préalable", explique le Dr Inubushi. "Le mécanisme sous-jacent à ce mélange efficace a été expliqué en examinant le flux autour des points fixes du point de vue de la théorie des systèmes dynamiques."
Un autre avantage significatif de la méthode RL était un apprentissage par transfert efficace (application des connaissances acquises à un problème différent mais connexe) du mélangeur formé. Dans le contexte du mélange de fluides, cela impliquait qu'un mélangeur entraîné à un certain nombre de Péclet (le rapport du taux d'advection au taux de diffusion dans le processus de mélange) pouvait être utilisé pour résoudre un problème de mélange à un autre nombre de Péclet. Cela a considérablement réduit le temps et le coût de la formation de l'algorithme RL.
Bien que ces résultats soient encourageants, le Dr Inubishi souligne qu'il s'agit encore de la première étape. "Il reste encore de nombreux problèmes à résoudre, tels que l'application de la méthode à des problèmes de mélange de fluides plus réalistes et l'amélioration des algorithmes RL et de leurs méthodes de mise en œuvre", déclare-t-il.
S'il est certainement vrai que le mélange de fluides bidimensionnel n'est pas représentatif des problèmes de mélange réels dans le monde réel, cette étude fournit un point de départ utile. De plus, bien qu'il se concentre sur le mélange dans des flux laminaires, le procédé est également extensible au mélange turbulent. It is, therefore, versatile and has potential for major applications across various industries employing fluid mixing. Using a supercomputer to find the best way to mix two fluids