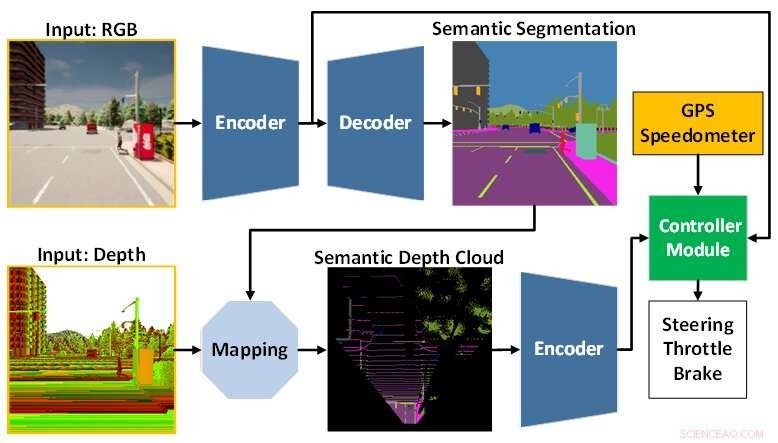
L'architecture du modèle AI est composée du module de perception (bleu) et du module contrôleur (vert). Le module de perception est chargé de percevoir l'environnement sur la base des données d'observation fournies par une caméra RGBD. Pendant ce temps, le module contrôleur est responsable du décodage des informations extraites pour estimer le degré de direction, d'accélération et de freinage. Crédit :Université de technologie de Toyohashi
Une équipe de recherche composée d'Oskar Natan, un Ph.D. étudiant, et son superviseur, le professeur Jun Miura, qui sont affiliés à l'Active Intelligent System Laboratory (AISL), Department of Computer Science Engineering, Toyohashi University of Technology, ont développé un modèle d'IA capable de gérer simultanément la perception et le contrôle pour une conduite autonome véhicule.
Le modèle d'IA perçoit l'environnement en effectuant plusieurs tâches de vision tout en conduisant le véhicule en suivant une séquence de points de route. De plus, le modèle AI peut conduire le véhicule en toute sécurité dans diverses conditions environnementales dans divers scénarios. Évalué dans le cadre de tâches de navigation point à point, le modèle d'IA atteint la meilleure maniabilité de certains modèles récents dans un environnement de simulation standard.
La conduite autonome est un système complexe composé de plusieurs sous-systèmes qui gèrent de multiples tâches de perception et de contrôle. Cependant, le déploiement de plusieurs modules spécifiques à une tâche est coûteux et inefficace, car de nombreuses configurations sont encore nécessaires pour former un système modulaire intégré.
De plus, le processus d'intégration peut entraîner une perte d'informations car de nombreux paramètres sont ajustés manuellement. Grâce à la recherche rapide sur l'apprentissage en profondeur, ce problème peut être résolu en formant un seul modèle d'IA avec des manières de bout en bout et multitâches. Ainsi, le modèle peut fournir des commandes de navigation uniquement basées sur les observations fournies par un ensemble de capteurs. Comme la configuration manuelle n'est plus nécessaire, le modèle peut gérer les informations tout seul.
Le défi qui reste pour un modèle de bout en bout est de savoir comment extraire les informations utiles pour que le contrôleur puisse estimer correctement les commandes de navigation. Cela peut être résolu en fournissant beaucoup de données au module de perception pour mieux percevoir l'environnement qui l'entoure. De plus, une technique de fusion de capteurs peut être utilisée pour améliorer les performances car elle fusionne différents capteurs pour capturer divers aspects des données.
Cependant, une énorme charge de calcul est inévitable car un modèle plus grand est nécessaire pour traiter plus de données. De plus, une technique de prétraitement des données est nécessaire car différents capteurs sont souvent livrés avec différentes modalités de données. De plus, l'apprentissage des déséquilibres pendant le processus de formation pourrait être un autre problème puisque le modèle effectue simultanément des tâches de perception et de contrôle.

Quelques records de conduite réalisés par le modèle AI. Colonnes (de gauche à droite) :image couleur, image de profondeur, résultat de la segmentation sémantique, carte à vol d'oiseau (BEV), commande de contrôle. La météo et l'heure pour chaque scène sont les suivantes :(1) midi clair, (2) coucher de soleil nuageux, (3) midi pluvieux, (4) coucher de soleil sous une pluie battante, (5) coucher de soleil humide. Crédit :Université de technologie de Toyohashi
Afin de répondre à ces défis, l'équipe propose un modèle d'IA formé avec des manières de bout en bout et multi-tâches. Le modèle est composé de deux modules principaux, à savoir les modules de perception et de contrôle. La phase de perception commence par le traitement des images RVB et des cartes de profondeur fournies par une seule caméra RGBD.
Ensuite, les informations extraites du module de perception ainsi que la mesure de la vitesse du véhicule et les coordonnées du point d'itinéraire sont décodées par le module contrôleur pour estimer les commandes de navigation. Afin de s'assurer que toutes les tâches peuvent être effectuées de la même manière, l'équipe utilise un algorithme appelé normalisation du gradient modifié (MGN) pour équilibrer le signal d'apprentissage pendant le processus de formation.
L'équipe considère l'apprentissage par imitation car il permet au modèle d'apprendre à partir d'un ensemble de données à grande échelle pour correspondre à une norme quasi humaine. De plus, l'équipe a conçu le modèle pour utiliser un plus petit nombre de paramètres que d'autres afin de réduire la charge de calcul et d'accélérer l'inférence sur un appareil aux ressources limitées.
Sur la base du résultat expérimental dans un simulateur de conduite autonome standard, CARLA, il est révélé que la fusion d'images RVB et de cartes de profondeur pour former une carte sémantique à vol d'oiseau (BEV) peut améliorer les performances globales. Comme le module de perception a une meilleure compréhension globale de la scène, le module de contrôleur peut exploiter des informations utiles pour estimer correctement les commandes de navigation. En outre, l'équipe déclare que le modèle proposé est préférable pour le déploiement car il offre une meilleure maniabilité avec moins de paramètres que les autres modèles.
La recherche a été publiée dans IEEE Transactions on Intelligent Vehicles , et l'équipe travaille actuellement sur des modifications et des améliorations du modèle afin de résoudre plusieurs problèmes lors de la conduite dans de mauvaises conditions d'éclairage, comme la nuit, sous de fortes pluies, etc. Par hypothèse, l'équipe pense que l'ajout d'un capteur qui n'est pas affecté par les changements de luminosité ou d'éclairage, tels que LiDAR, améliorera les capacités de compréhension de la scène du modèle et se traduira par une meilleure maniabilité. Une autre tâche future consiste à appliquer le modèle proposé à la conduite autonome dans le monde réel. Le nouveau modèle de base améliore la précision de l'interprétation des images de télédétection