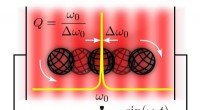
Exemple d'agent d'apprentissage dans un jeu vidéo :le personnage est contrôlé par un joueur humain. Les yeux sont les agents. Le joueur est censé guider les agents de manière à ce qu'ils exécutent une tâche, par exemple sans heurter d'abord un obstacle. La formation est basée sur un processus d'apprentissage automatique; tout ce que le joueur fait est de décrire les exigences approximatives. Crédit : RUB, Institut de Neuroinformatique
Les processus qui sous-tendent l'intelligence artificielle aujourd'hui sont en fait assez stupides. Des chercheurs de Bochum tentent de les rendre plus intelligents.
Changement radical, révolution, mégatendance, peut-être même un risque :l'intelligence artificielle a pénétré tous les segments industriels et occupe les médias. Les chercheurs du RUB Institute for Neural Computation l'étudient depuis 25 ans. Leur principe directeur est :pour que les machines soient vraiment intelligentes, les nouvelles approches doivent d'abord rendre le machine learning plus efficace et plus flexible.
« Il existe deux types d'apprentissage automatique qui réussissent aujourd'hui :les réseaux de neurones profonds, également connu sous le nom de Deep Learning, ainsi que l'apprentissage par renforcement, " explique le professeur Laurenz Wiskott, Chaire de théorie des systèmes neuronaux.
Les réseaux de neurones sont capables de prendre des décisions complexes. Ils sont fréquemment utilisés dans les applications de reconnaissance d'images. "Ils peuvent, par exemple, dire à partir de photos si le sujet est un homme ou une femme, " dit Wiskott.
L'architecture de tels réseaux s'inspire des réseaux de cellules nerveuses, ou des neurones, dans notre cerveau. Les neurones reçoivent des signaux via plusieurs canaux d'entrée, puis décident s'ils transmettent ou non le signal sous forme d'impulsion électrique aux neurones suivants.
Les réseaux de neurones reçoivent également plusieurs signaux d'entrée, par exemple des pixels. Dans un premier temps, de nombreux neurones artificiels calculent un signal de sortie à partir de plusieurs signaux d'entrée en multipliant simplement les entrées par des poids différents mais constants, puis en les additionnant. Chacune de ces opérations arithmétiques aboutit à une valeur qui – pour rester sur l'exemple homme/femme – contribue un peu à la décision pour le féminin ou le masculin. "Le résultat est légèrement modifié, cependant, en mettant les résultats négatifs à zéro. Cette, trop, est copié à partir des cellules nerveuses et est essentiel pour la performance des réseaux de neurones, " explique Laurenz Wiskott.
La même chose se reproduit dans la couche suivante, jusqu'à ce que le réseau prenne une décision dans la phase finale. Plus il y a d'étapes dans le processus, plus il est puissant - les réseaux de neurones avec plus de 100 étapes ne sont pas rares. Les réseaux de neurones résolvent souvent les tâches de discrimination mieux que les humains.
L'effet d'apprentissage de tels réseaux repose sur le choix des bons facteurs de pondération, qui sont initialement choisis au hasard. « Pour former un tel réseau, les signaux d'entrée ainsi que ce que devrait être la décision finale sont spécifiés dès le départ, " élabore Laurenz Wiskott. Ainsi, le réseau est en mesure d'ajuster progressivement les facteurs de pondération pour finalement prendre la bonne décision avec la plus grande probabilité.
Apprentissage par renforcement, d'autre part, s'inspire de la psychologie. Ici, chaque décision prise par l'algorithme – les experts l'appellent l'agent – est soit récompensée, soit punie. "Imaginez une grille avec l'agent au milieu, " illustre Laurenz Wiskott. " Son objectif est d'atteindre la case en haut à gauche par le chemin le plus court possible - mais il ne le sait pas. " La seule chose que veut l'agent est d'obtenir autant de récompenses que possible, sinon c'est nul. En premier, il se déplacera au hasard sur le plateau, et chaque pas qui n'atteint pas le but sera puni. Seul le pas vers le but donne lieu à une récompense.

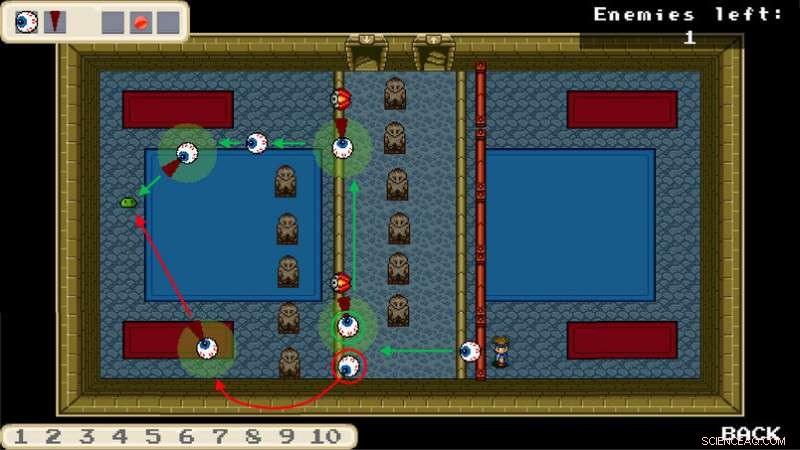
Quelle route le robot doit-il emprunter ? Cette décision est basée sur d'innombrables opérations arithmétiques. Crédit :Roberto Schirdewahn
Pour apprendre, l'agent attribue une valeur à chaque champ indiquant le nombre d'étapes restantes entre cette position et son objectif. Initialement, ces valeurs sont aléatoires. Plus l'agent gagne en expérience sur son plateau, mieux il pourra adapter ces valeurs aux conditions de la vie réelle. Après de nombreuses courses, il est capable de trouver le chemin le plus rapide vers son objectif et, par conséquent, à la récompense.
"Le problème avec ces processus d'apprentissage automatique est qu'ils sont assez stupides, " explique Laurenz Wiskott. " Les techniques sous-jacentes remontent aux années 1980. La seule raison de leur succès actuel est qu'aujourd'hui nous avons plus de capacité de calcul et plus de données à notre disposition. il est possible d'exécuter rapidement d'innombrables fois les processus d'apprentissage pratiquement inefficaces et d'alimenter les réseaux de neurones avec une pléthore d'images et de descriptions d'images afin de les former.
"Ce que nous voulons savoir, c'est :comment pouvons-nous éviter tout ce temps, formation absurde? Et surtout :comment pouvons-nous rendre l'apprentissage automatique plus flexible ?" comme le dit succinctement Wiskott. L'intelligence artificielle peut être supérieure à l'homme dans exactement la tâche pour laquelle elle a été formée, mais il ne peut pas généraliser ou transférer ses connaissances à des tâches connexes.
C'est pourquoi les chercheurs de l'Institute for Neural Computation se concentrent sur de nouvelles stratégies qui aident les machines à découvrir des structures de manière autonome. "À cette fin, nous déployons le principe de l'apprentissage non supervisé, " explique Laurenz Wiskott. Alors que les réseaux de neurones profonds et l'apprentissage par renforcement sont basés sur la présentation du résultat souhaité ou sur la récompense ou la punition de chaque étape, les chercheurs laissent les algorithmes d'apprentissage en grande partie seuls avec leur contribution.
"Une tâche pourrait être, par exemple, former des grappes, " explique Wiskott. A cet effet, l'ordinateur est chargé de regrouper des données similaires. En ce qui concerne les points dans un espace à trois dimensions, cela signifierait regrouper des points dont les coordonnées sont proches les unes des autres. Si la distance entre les coordonnées est plus grande, ils seraient répartis dans différents groupes.
"Pour en revenir à l'exemple des photos de personnes, on pourrait regarder le résultat après le regroupement et trouverait probablement que l'ordinateur a constitué un groupe avec des photos d'hommes et un groupe avec des photos de femmes, " précise Laurenz Wiskott. " Un avantage majeur est qu'il suffit au départ de prendre des photos, plutôt qu'une légende d'image contenant la solution de l'énigme à des fins de formation, comme c'était."
Le principe de lenteur
De plus, cette méthode offre plus de flexibilité, parce que cette formation de cluster est applicable non seulement pour les images de personnes, mais aussi pour ceux des voitures, les plantes, maisons ou autres objets.
Une autre approche poursuivie par Wiskott est le principe de lenteur. Ici, ce ne sont pas les photos qui constituent le signal d'entrée, mais des images animées :si toutes les caractéristiques sont extraites d'une vidéo qui évolue très lentement, des structures émergent qui aident à construire une représentation abstraite de l'environnement. "Ici, trop, il s'agit de préstructurer les données d'entrée, " souligne Laurenz Wiskott. Finalement, les chercheurs combinent ces approches de manière modulaire avec les méthodes d'apprentissage supervisé, afin de créer des applications plus souples mais néanmoins très précises.
"Une flexibilité accrue entraîne naturellement une perte de performance, " admet le chercheur. Mais à terme, la flexibilité est indispensable si nous voulons développer des robots capables de gérer de nouvelles situations."