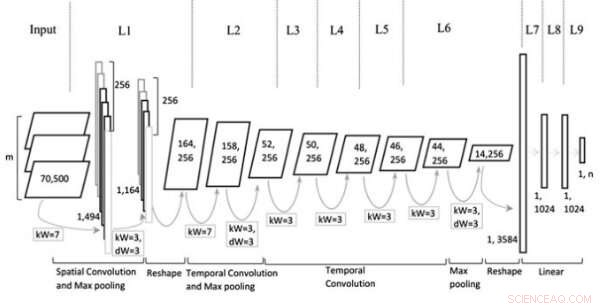
Architecture de modèle. Crédit :Jin et al, Revue Wiley Computational Intelligence.
Au cours de la dernière décennie, les réseaux de neurones convolutifs (CNN) se sont avérés très efficaces pour s'attaquer à une variété de tâches, y compris les tâches de traitement du langage naturel (NLP). La PNL implique l'utilisation de techniques informatiques pour analyser ou synthétiser le langage, à la fois sous forme écrite et orale. Les chercheurs ont appliqué avec succès les CNN à plusieurs tâches de PNL, y compris l'analyse sémantique, récupération de requête de recherche et classification de texte.
Typiquement, Les CNN formés pour les tâches de classification de texte traitent les phrases au niveau du mot, représentant des mots individuels comme des vecteurs. Bien que cette approche puisse sembler cohérente avec la façon dont les humains traitent le langage, des études récentes ont montré que les CNN qui traitent les phrases au niveau des caractères peuvent également obtenir des résultats remarquables.
Un avantage clé des analyses au niveau des caractères est qu'elles ne nécessitent pas de connaissance préalable des mots. Cela permet aux CNN de s'adapter plus facilement à différentes langues et d'acquérir des mots anormaux causés par une faute d'orthographe.
Des études antérieures suggèrent que différents niveaux d'incorporation de texte (c'est-à-dire mot-, ou -niveau document) sont plus efficaces pour différents types de tâches, mais il n'y a toujours pas d'indications claires sur la façon de choisir le bon encastrement ou quand passer à un autre. Avec ça en tête, une équipe de chercheurs de l'université polytechnique de Tianjin en Chine a récemment développé une nouvelle architecture CNN basée sur les types de représentation généralement utilisés dans les tâches de classification de texte.
"Nous proposons une nouvelle architecture de CNN basée sur de multiples représentations pour la classification de texte en construisant plusieurs plans afin que plus d'informations puissent être déversées dans les réseaux, telles que différentes parties de texte obtenues via un outil de reconnaissance d'entités nommées ou des outils de balisage de parties de discours, différents niveaux d'incorporation de texte ou de phrases contextuelles, ", ont écrit les chercheurs dans leur article.
Le modèle CNN multi-représentation (Mr-CNN) conçu par les chercheurs est basé sur l'hypothèse que toutes les parties du texte écrit (par exemple, les noms, verbes, etc.) jouent un rôle clé dans les tâches de classification et que différentes incorporations de texte sont plus efficaces à différentes fins. Leur modèle combine deux outils clés, le système de reconnaissance d'entités nommées (NER) de Stanford et le marqueur de partie du discours (POS). La première est une méthode pour marquer les rôles sémantiques des choses dans les textes (par exemple, personne, entreprise, etc.); ce dernier est une technique utilisée pour attribuer une partie des balises vocales à chaque bloc de texte (par exemple un nom ou un verbe).
Les chercheurs ont utilisé ces outils pour pré-traiter les phrases, obtenir plusieurs sous-ensembles de la phrase originale, dont chacun contient des types spécifiques de mots dans le texte. Ils ont ensuite utilisé les sous-ensembles et la phrase complète comme représentations multiples pour leur modèle Mr-CNN.
Lorsqu'il est évalué sur des tâches de classification de texte avec du texte provenant de divers ensembles de données à grande échelle et spécifiques à un domaine, le modèle Mr-CNN a atteint des performances remarquables, avec un maximum de 13 % d'amélioration du taux d'erreur sur un ensemble de données et une amélioration de 8 % sur un autre. Cela suggère que les représentations multiples du texte permettent au réseau de concentrer son attention de manière adaptative sur les informations les plus pertinentes, l'amélioration de ses capacités de classification.
"Divers à grande échelle, des ensembles de données spécifiques au domaine ont été utilisés pour valider l'architecture proposée, " les chercheurs ont écrit. " Les tâches analysées incluent la classification de documents d'ontologie, catégorisation d'événements biomédicaux, et analyse des sentiments, montrant que les CNN multi-représentations, qui apprennent à focaliser l'attention sur des représentations spécifiques du texte, peut obtenir des gains de performances supplémentaires par rapport aux modèles de réseau de neurones profonds de pointe."
Dans leurs futurs travaux, les chercheurs prévoient d'étudier si des fonctionnalités à granularité fine peuvent aider à empêcher le surapprentissage de l'ensemble de données d'entraînement. Ils souhaitent également explorer d'autres méthodes qui pourraient améliorer l'analyse de parties spécifiques de phrases, potentiellement améliorer encore les performances du modèle.
© 2019 Réseau Science X