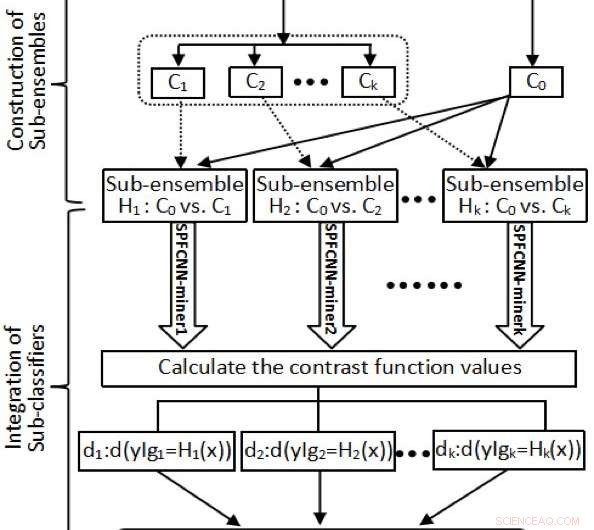
L'organigramme si MLF. Crédit :Zhao et al.
Des chercheurs de l'Université de Chongqing en Chine ont récemment développé un classificateur de méta-apprentissage sensible aux coûts qui peut être utilisé lorsque les données de formation disponibles sont de grande dimension ou limitées. Leur classificateur, appelé SPFCNN-Miner, a été présenté dans un article publié dans Elsevier's Systèmes informatiques de la future génération .
Bien que les classificateurs d'apprentissage automatique se soient avérés efficaces dans une variété de tâches, pour obtenir des résultats optimaux, ils nécessitent souvent une grande quantité de données d'entraînement. Lorsque les données sont de grande dimension, limité ou déséquilibré, la plupart des méthodes de classification sont incapables d'obtenir une performance satisfaisante. Dans leur étude, l'équipe de chercheurs de l'université de Chongqing a entrepris de mieux comprendre ces défis liés aux données et de développer un classificateur capable de les surmonter.
« Nous avons utilisé des réseaux siamois qui conviennent à l'apprentissage par petits coups où peu de données sont disponibles pour apprendre des données de grande dimension et limitées, et appliquer l'idée de combiner des approches « peu profondes » et « en profondeur » pour concevoir des réseaux siamois parallèles qui peuvent mieux extraire des caractéristiques simples ou complexes à partir d'une variété d'ensembles de données, " Linchang Zhao, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Les principaux objectifs de notre étude étaient de résoudre le problème de déséquilibre des classes de données et d'obtenir les meilleurs résultats de classification possibles sur de tels ensembles de données."
Zhao et ses collègues ont développé un réseau neuronal siamois parallèle entièrement connecté (SPFCNN) et l'ont appliqué aux problèmes de distribution de données déséquilibrées en classe. Pour transformer leur SPFCNN insensible aux coûts en une approche sensible aux coûts, ils ont utilisé une technique appelée « apprentissage sensible aux coûts ».
D'abord, les chercheurs ont divisé le groupe majoritaire dans un ensemble de données basé sur les caractéristiques transformées du produit interne. Cela garantissait que la taille de chaque sous-groupe dans un groupe majoritaire était proche de celle du groupe minoritaire. En outre, ils ont structuré des sous-ensembles en utilisant le groupe minoritaire vs chaque partition obtenue.
"Prochain, nous avons appliqué n SPFCNN-mineurs à tous les sous-ensembles, chaque point d'échantillonnage X
L'approche conçue par Zhao et ses collègues présente de nombreux avantages qui la distinguent des autres classificateurs. D'abord, leur fonction méta-apprenant (MLF) peut être utilisée pour partitionner le groupe majoritaire dans un ensemble de données basé sur les caractéristiques transformées du produit interne, ce qui se traduit par des données transformées contenant des informations relatives aux distances et aux angles entre les éléments des groupes minoritaires et majoritaires.
« Les angles entre le groupe majoritaire et le groupe minoritaire peuvent être considérés comme l'expression de lieux liés et représentent alors la direction liée du groupe majoritaire au groupe minoritaire, " expliqua Zhao.
Un autre avantage du nouveau classificateur SPFCNN-Miner est que, comme les autres réseaux siamois, il peut extraire efficacement les caractéristiques de plus haut niveau d'une petite quantité d'échantillons pour un apprentissage en quelques coups. De plus, Les réseaux siamois parallèles sont conçus pour apprendre de manière adaptative des caractéristiques simples ou complexes à partir de différentes dimensions d'attributs de données.
Zhao et ses collègues ont évalué leur approche dans une série de tests informatiques, en utilisant à la fois des versions insensibles aux coûts et sensibles aux coûts du classificateur SPFCNN. Ils ont constaté que l'approche sensible aux coûts surpassait tous les classificateurs avec lesquels ils l'avaient comparée.
« Les résultats expérimentaux montrent que notre SPFCNN est une approche compétitive et est capable d'améliorer les performances de classification de manière plus significative par rapport aux approches comparatives, " a déclaré Zhao. " Nous avons constaté que les performances de notre modèle ne s'amélioraient pas à mesure que la taille de l'échantillon augmentait, mais a été fortement affectée par le taux de déséquilibre. Les performances obtenues en intégrant l'apprentissage sensible aux coûts dans notre modèle sont plus stables."
L'étude menée par Zhao et ses collègues introduit une nouvelle méthode qui pourrait être utilisée par les chercheurs pour améliorer les performances des classificateurs lorsque les données sont limitées ou déséquilibrées. En outre, leurs résultats suggèrent qu'équilibrer le nombre d'échantillons positifs et négatifs peut être plus efficace que de générer un plus grand nombre d'échantillons artificiels. Par exemple, leur approche peut intégrer différents coûts de classification erronée au fur et à mesure qu'elle achève une tâche de classification, ce qui la rend plus robuste que les autres techniques utilisées pour résoudre les problèmes liés aux données déséquilibrées.
"À l'avenir, nous prévoyons d'utiliser des techniques telles que les matrices de marche aléatoire, partage du poids circulant et codage de Huffman pour compresser notre modèle, et la technologie faiblement connectée ou la méthode d'élagage-quantification en parallèle seront utilisées pour alléger le modèle SPFCNN proposé, " dit Zhao.
© 2019 Réseau Science X