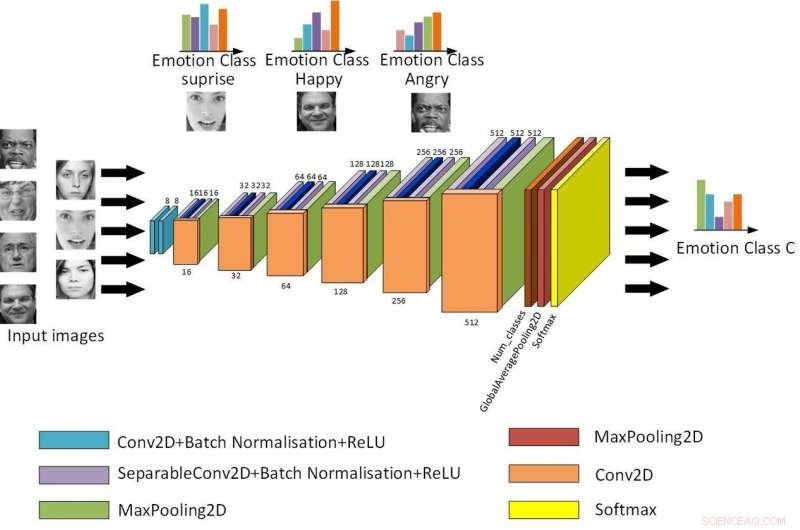
La structure de base du Light-CNN. Crédit :Jie &Yongsheng.
Deux chercheurs de l'Université d'énergie électrique de Shanghai ont récemment développé et évalué de nouveaux modèles de réseaux neuronaux pour la reconnaissance des expressions faciales (FER) dans la nature. Leur étude, publié dans la revue Neurocomputing d'Elsevier, présente trois modèles de réseaux de neurones convolutifs (CNN) :un Light-CNN, un CNN à double branche et un CNN pré-formé.
"En raison du manque d'informations sur les visages non frontaux, FER à l'état sauvage est un point difficile en vision par ordinateur, " Qian Yongsheng, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. « Les méthodes existantes de reconnaissance des expressions faciales naturelles basées sur les réseaux de neurones à convolution profonde (CNN) présentent plusieurs problèmes, y compris sur-ajustement, complexité de calcul élevée, fonctionnalité unique et échantillons limités."
Bien que de nombreux chercheurs aient développé des approches CNN pour le FER, jusque là, très peu d'entre eux ont essayé de déterminer quel type de réseau est le mieux adapté à cette tâche particulière. Conscient de cette lacune dans la littérature, Yongsheng et son collègue Shao Jie ont développé trois CNN différents pour FER et ont effectué une série d'évaluations pour identifier leurs forces et leurs faiblesses.
"Notre premier modèle est un CNN léger peu profond qui introduit un module séparable en profondeur avec le module réseau résiduel, réduire les paramètres du réseau en changeant la méthode de convolution, " a déclaré Yongsheng. " Le second est un CNN à double succursale, qui combine des caractéristiques globales et des caractéristiques de texture locales, en essayant d'obtenir des caractéristiques plus riches et de compenser le manque d'invariance de rotation de la convolution. Le troisième CNN pré-entraîné utilise des poids entraînés dans la même grande base de données distribuée pour se recycler sur sa propre petite base de données, réduction du temps de formation et amélioration du taux de reconnaissance."
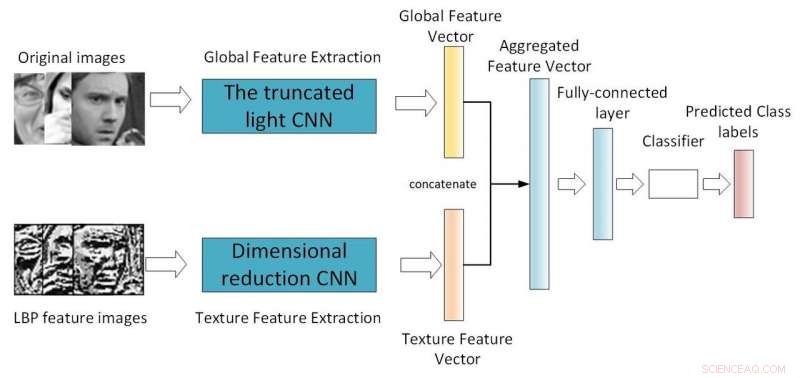
Cadre du CNN bi-branche. Crédit :Jie &Yongsheng.
Les chercheurs ont effectué des évaluations approfondies de leurs modèles CNN sur trois ensembles de données couramment utilisés pour le FER :le CK+ public, jeux de données multi-vues BU-3DEF et FER2013. Bien que les trois modèles CNN présentent des différences de performances, ils ont tous obtenu des résultats prometteurs, surpassant plusieurs approches de pointe pour FER.
"Maintenant, les trois modèles CNN sont utilisés séparément, " Yongsheng a expliqué. " Le réseau peu profond est plus approprié pour le matériel embarqué. Le CNN pré-formé peut obtenir de meilleurs résultats, mais nécessite des poids pré-entraînés. Le réseau à deux branches n'est pas très efficace. Bien sûr, on pourrait aussi essayer d'utiliser les trois modèles ensemble."
Dans leurs évaluations, les chercheurs ont observé qu'en combinant le module réseau résiduel et le module séparable en profondeur, comme ils l'ont fait pour leur premier modèle CNN, les paramètres du réseau pourraient être réduits. Cela pourrait finalement résoudre certaines des lacunes du matériel informatique. En outre, ils ont découvert que le modèle CNN pré-entraîné transférait une grande base de données vers sa propre base de données et pouvait donc être entraîné avec des échantillons limités.
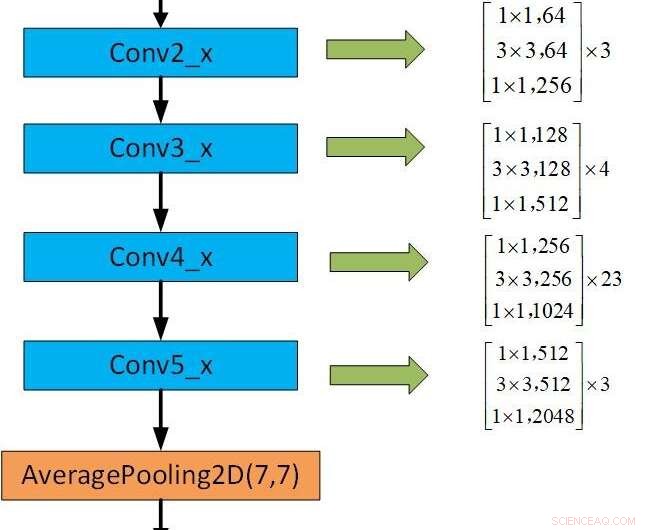
Le cadre du préformé CNN. Crédit :Jie &Yongsheng.
Les trois CNN pour FER proposés par Yongsheng et Jie pourraient avoir de nombreuses applications, par exemple, aider au développement de robots capables d'identifier les expressions faciales des humains avec lesquels ils interagissent. Les chercheurs prévoient maintenant d'apporter des ajustements supplémentaires à leurs modèles, afin d'améliorer encore leurs performances.
« Dans notre futur travail, nous allons essayer d'ajouter différentes fonctionnalités manuelles traditionnelles pour rejoindre le CNN à double branche et changer le mode de fusion, " a déclaré Yongsheng. " Nous utiliserons également des paramètres de réseau de formation à base de données croisées pour obtenir de meilleures capacités de généralisation et adopter une approche d'apprentissage par transfert en profondeur plus efficace. "
© 2019 Réseau Science X