
Winterfell. Crédit :mauRÍCIO santos (Unsplash, domaine public)
Des chercheurs de la Vrije Universiteit Amsterdam et du cluster des sciences humaines de l'Académie royale néerlandaise ont évalué quatre outils de pointe pour reconnaître les noms dans le texte, d'évaluer et d'améliorer leurs performances sur la fiction populaire. Ils trouvent des solutions pour augmenter la capacité des outils à reconnaître les noms dans un roman d'une précision de 7 % à 90 %.
Les outils de traitement du langage naturel (NLP) sont couramment utilisés dans de nombreuses applications quotidiennes telles que Siri et Google, mais l'efficacité de ces technologies n'est pas bien comprise. Des chercheurs de la Vrije Universiteit Amsterdam et du cluster des sciences humaines de l'Académie royale néerlandaise ont effectué une évaluation approfondie de quatre outils de reconnaissance de nom différents sur 40 romans populaires, dont A Game of Thrones. leurs analyses, Publié dans PeerJ Informatique , mettre en évidence les types de noms et de textes qui sont particulièrement difficiles à identifier pour ces outils ainsi que des solutions pour atténuer cela. En outre, ils ont extrait les réseaux sociaux des romans pour explorer les différences dans la structure de l'histoire. Ces informations peuvent aider à rendre ces technologies plus robustes contre les différences de genre, et peut aider, par exemple, à rendre cette technologie plus utile aux journalistes souhaitant analyser de grands ensembles de données tels que les Panama Papers.
De nombreux outils de PNL sont basés sur l'apprentissage automatique; C'est, un programme informatique est formé pour identifier des modèles dans le texte sur la base d'exemples précédemment fournis. Pour reconnaître les noms dans le texte, il s'est par exemple nourri de nombreux articles de journaux dont les humains ont méticuleusement marqué les noms. Le programme est ensuite chargé d'« apprendre » à quoi ressemble un nom en fonction du contexte (par exemple, il étant précédé de Mr) ou la forme du mot (comme les noms commencent généralement par une majuscule en anglais). Maintenant, le problème lors de l'application d'un tel système formé sur les journaux aux romans, est que les auteurs de romans ont beaucoup plus de liberté dans leur récit que les journalistes qui doivent s'en tenir aux faits. Les auteurs de fiction peuvent créer leurs propres noms, comme Tywin ou R'hllor, ou utilisez des noms de caractères descriptifs directement du dictionnaire tels que Grey Worm. Ces noms ne se comportent pas comme des noms "normaux", ainsi les systèmes PNL ont du mal à les reconnaître dans un texte.
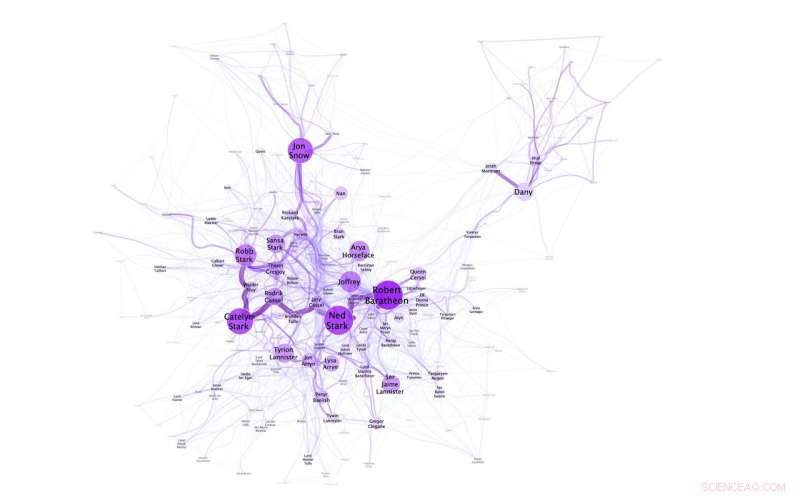
Visualisation du réseau montrant que Dany/Daenerys n'est pas proche des autres personnages principaux de "A Game of Thrones". Crédit :N. M. Dekker, CC BY-SA 4.0
Les expériences réalisées par Niels Dekker (Trifork B.V.), Tobias Kuhn (Vrije Universiteit Amsterdam) et Marieke van Erp (KNAW Humanities Cluster) soulignent également la flexibilité du langage et la manière dont les noms sont contextualisés dans les histoires. Il est par exemple possible de désigner Daenerys Targaryen comme Daenerys et elle, mais elle est aussi connue sous le nom de Dany, Daenerys Stormborn, Mère des dragons, Khaleesi, l'Imbrûlé et Mhysa. Le réseau social créé pour A Game of Thrones, illustre par exemple que Dany est utilisé par ses amis, et son nom complet Daenerys uniquement par ses ennemis (en son absence).
Les recherches décrites dans cette publication montrent qu'une plus grande attention devrait être accordée aux performances des outils de PNL et qu'il reste encore du travail à faire avant que le « texte » puisse être pleinement compris par les ordinateurs.














