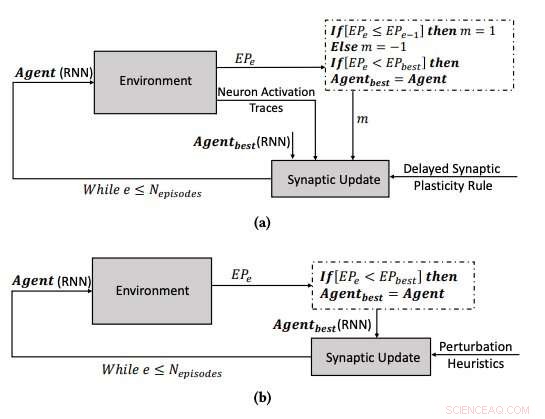
(a) Le processus d'apprentissage utilisant la plasticité synaptique retardée, et (b) le processus d'apprentissage en optimisant les paramètres des RNN à l'aide de l'algorithme d'escalade. Crédit :Yaman et al.
Le cerveau humain change continuellement au fil du temps, former de nouvelles connexions synaptiques basées sur des expériences et des informations apprises au cours d'une vie. Au cours des dernières années, Les chercheurs en intelligence artificielle (IA) ont essayé de reproduire cette capacité fascinante, connu sous le nom de "plasticité, ' dans les réseaux de neurones artificiels (ANN).
Des chercheurs de l'Université de technologie d'Eindhoven (Tu/e) et de l'Université de Trente ont récemment proposé une nouvelle approche inspirée des mécanismes biologiques qui pourraient améliorer l'apprentissage dans les RNA. Leur étude, décrit dans un article prépublié sur arXiv, a été financé par le programme de recherche et d'innovation Horizon 2020 de l'Union européenne.
"L'une des propriétés fascinantes des réseaux de neurones biologiques (BNN) est leur plasticité, qui leur permet d'apprendre en changeant leur configuration en fonction de l'expérience, " Anil Yaman, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Selon la compréhension physiologique actuelle, ces changements sont effectués sur des synapses individuelles en fonction des interactions locales des neurones. Cependant, l'émergence d'un comportement d'apprentissage global cohérent à partir de ces interactions individuelles n'est pas très bien comprise."
Inspiré par la plasticité des BNNs et son processus évolutif, Yaman et ses collègues voulaient imiter des mécanismes d'apprentissage biologiquement plausibles dans des systèmes artificiels. Pour modéliser la plasticité dans les RNAs, les chercheurs utilisent généralement ce qu'on appelle les règles d'apprentissage Hebbian, qui sont des règles qui mettent à jour les synapses en fonction des activations neuronales et des signaux de renforcement reçus de l'environnement.

Plusieurs exécutions indépendantes des processus d'apprentissage en utilisant diverses règles de plasticité synaptique retardée évoluées (la meilleure règle DSP est indiquée en vert). Crédit :Yaman et al.
Lorsque les signaux de renforcement ne sont pas disponibles immédiatement après chaque sortie réseau, cependant, certains problèmes peuvent survenir, ce qui rend plus difficile pour le réseau d'associer les activations neuronales pertinentes au signal de renforcement. Pour surmonter ce problème, connu sous le nom de « problème de récompense distale », " les chercheurs ont étendu les règles de plasticité de Hebbian afin qu'elles permettent l'apprentissage dans les cas de récompense distaux. Leur approche, appelée plasticité synaptique retardée (DSP), utilise ce qu'on appelle des traces d'activation des neurones (NAT) pour fournir un stockage supplémentaire dans chaque synapse, ainsi que pour garder une trace des activations de neurones pendant que le réseau effectue une certaine tâche.
"Les règles de plasticité synaptique sont basées sur les activations locales des neurones et un signal de renforcement, " expliqua Yaman. " Cependant, dans la plupart des problèmes d'apprentissage, les signaux de renforcement sont reçus après un certain temps plutôt qu'immédiatement après chaque action du réseau. Dans ce cas, il devient problématique d'associer les signaux de renforcement aux activations des neurones. Dans ce travail, nous avons proposé d'utiliser ce que nous avons appelé des "traces d'activation des neurones, ' pour stocker les statistiques d'activations de neurones dans chaque synapse et informer les règles de plasticité synaptique sur la façon d'effectuer des changements synaptiques retardés."
L'un des aspects les plus significatifs de l'approche conçue par Yaman et ses collègues est qu'elle ne suppose pas d'informations globales sur le problème que le réseau de neurones va résoudre. Par ailleurs, elle ne dépend pas de l'architecture spécifique de l'ANN et elle est donc hautement généralisable.
"En termes pratiques, notre étude peut jeter les bases de nouveaux schémas d'apprentissage qui peuvent être utilisés dans un certain nombre d'applications de réseaux neuronaux, comme la robotique et les véhicules autonomes, et en général dans tous les cas où un agent doit effectuer un comportement adaptatif en l'absence d'une récompense immédiate obtenue de ses actions, " Giovanni Iacca, un autre chercheur impliqué dans l'étude, a déclaré TechXplore. "Par exemple, en IA pour les jeux vidéo, une action au pas de temps actuel peut ne pas nécessairement conduire à une récompense pour le moment, mais seulement après un certain temps; un agent affichant des publicités personnalisées pourrait obtenir une "récompense" du comportement de l'utilisateur seulement après un certain temps, etc.)."
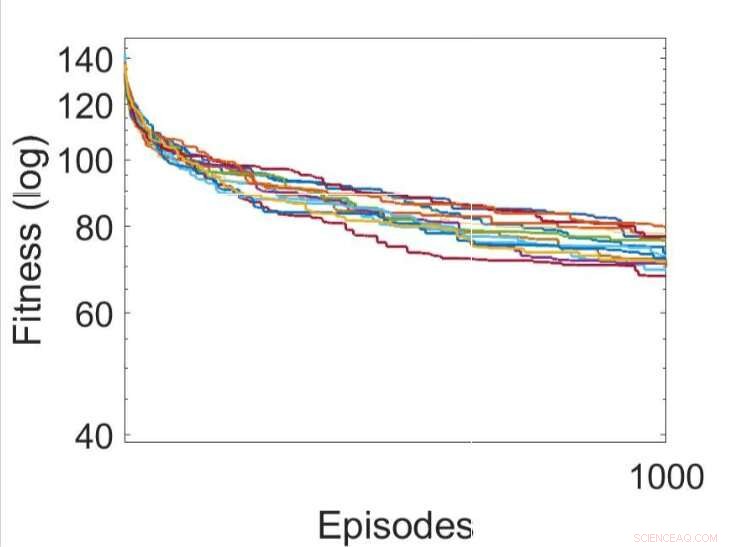
Plusieurs exécutions indépendantes des processus d'apprentissage en optimisant les paramètres des RNN à l'aide de l'algorithme d'escalade. Crédit :Yaman et al.
Les chercheurs ont testé leurs règles de plasticité Hebbian nouvellement adaptées dans une simulation d'un environnement de labyrinthe triple T. Dans cet environnement, un agent contrôlé par un simple réseau de neurones récurrents (RNN) doit apprendre à trouver une parmi huit positions possibles, à partir d'une configuration réseau aléatoire.
Yaman, Iacca et leurs collègues ont comparé les performances obtenues en utilisant leur approche avec celles obtenues lorsqu'un agent a été formé à l'aide d'un algorithme de recherche locale itératif analogue, appelé escalade (HC). La principale différence entre l'algorithme d'escalade HC et leur approche est que le premier n'utilise aucune connaissance du domaine (c'est-à-dire des activations locales de neurones), tandis que ce dernier le fait.
Les résultats recueillis par les chercheurs suggèrent que les mises à jour synaptiques effectuées par leurs règles DSP conduisent à un entraînement plus efficace et finalement à de meilleures performances que l'algorithme HC. À l'avenir, leur approche pourrait aider à améliorer l'apprentissage à long terme dans les RNA, permettant aux systèmes artificiels de construire efficacement de nouvelles connexions basées sur leurs expériences.
"Nous nous intéressons principalement à la compréhension du comportement émergent et de la dynamique d'apprentissage des réseaux de neurones artificiels, et développer un modèle cohérent pour expliquer comment la plasticité synaptique se produit dans différents scénarios d'apprentissage, " a déclaré Yaman. "Je pense qu'il existe de vastes possibilités de recherches futures dans ce domaine, par exemple, il sera intéressant d'adapter l'approche proposée à des problèmes complexes à grande échelle (ainsi que des réseaux profonds) et de réaliser des mécanismes d'apprentissage d'inspiration biologique qui nécessitent le moins de supervision (ou pas du tout)."
© 2019 Réseau Science X