Les filaments proposés de matière noire entourant Jupiter pourraient faire partie des mystérieux 95 pour cent de l'énergie-masse de l'univers. Crédit :NASA/JPL-Caltech
La plupart de l'univers est sombre, avec de la matière noire et de l'énergie noire comprenant plus de 95 pour cent de sa masse-énergie. Pourtant, nous savons peu de choses sur la matière noire et l'énergie. Pour trouver des réponses, les scientifiques mènent d'énormes expériences de physique des hautes énergies. L'analyse des résultats exige un calcul haute performance, parfois équilibré avec les tendances industrielles.
Après quatre années de calcul pour l'expérience CMS Large Hadron Collider au CERN près de Genève, Suisse – partie des travaux qui ont révélé le boson de Higgs – Oliver Gutsche, un scientifique du Laboratoire national de l'accélérateur Fermi du ministère de l'Énergie (DOE), tourné vers la recherche de la matière noire. "Le boson de Higgs avait été prédit, et nous savions approximativement où chercher, " dit-il. " Avec la matière noire, nous ne savons pas ce que nous recherchons."
Pour en savoir plus sur la matière noire, Gutsche a besoin de plus de données. Une fois ces informations disponibles, les physiciens doivent l'exploiter. Ils explorent des outils informatiques pour le travail, y compris le logiciel open source Apache Spark.
A la recherche de la matière noire, les physiciens étudient les résultats des collisions de particules. "C'est trivial à paralléliser, " décomposer le travail en morceaux pour obtenir des réponses plus rapidement, Gutsche explique. "Deux PC peuvent traiter chacun une collision, " ce qui signifie que les chercheurs peuvent utiliser une grille informatique pour analyser les données.
Une grande partie du travail en physique des hautes énergies, bien que, dépend du logiciel que les scientifiques développent. « Si nos étudiants diplômés et post-doctorants ne connaissent que nos outils propriétaires, alors ils auront des problèmes s'ils vont à l'industrie, " lorsque ce logiciel n'est pas disponible, note Gutsche. "Alors j'ai commencé à me renseigner sur Spark."
Spark est un outil de réduction de données conçu pour les fichiers texte non structurés. Cela crée un défi :accéder aux données de physique des hautes énergies, qui sont dans un format orienté objet. Les chercheurs en informatique du Fermilab, Saba Sehrish et Jim Kowalkowski, s'attaquent à la tâche.
Spark a offert une promesse dès le début, avec des fonctionnalités particulièrement intéressantes, dit Sehrish. "L'un était en mémoire, traitement distribué à grande échelle" via des interfaces de haut niveau, ce qui le rend facile à utiliser. "Vous ne voulez pas que les scientifiques s'inquiètent de la façon de distribuer les données et d'écrire du code parallèle, " dit-elle. Spark s'occupe de ça.
Autre atout attractif :Spark est une plateforme de recherche soutenue au National Energy Research Scientific Computing Center (NERSC), une installation utilisateur du DOE Office of Science au Lawrence Berkeley National Laboratory du DOE. "Cela nous donne une équipe de support qui peut le régler, " dit Kowalkowski. Des informaticiens comme Sehrish et Kowalkowski peuvent ajouter des capacités, mais faire fonctionner le code sous-jacent aussi efficacement que possible nécessite des spécialistes de Spark, dont certains travaillent au NERSC.
Kowalkowski résume les fonctionnalités souhaitables de Spark comme « mise à l'échelle automatisée, parallélisme automatisé et un modèle de programmation raisonnable."
En bref, Lui et Sehrish veulent construire un système permettant aux chercheurs d'exécuter une analyse qui fonctionne extrêmement bien sur des machines à grande échelle sans complications et via une interface utilisateur simple.
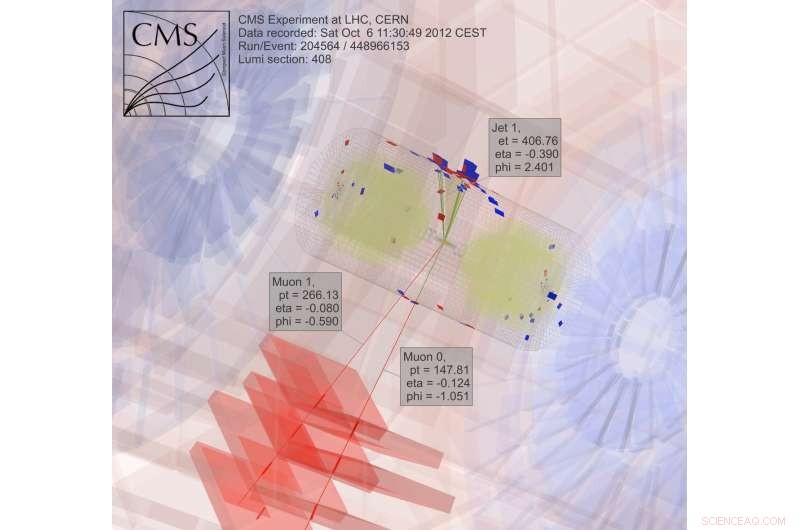
Pour rechercher la matière noire, les scientifiques collectent et analysent les résultats des collisions de particules, un processus extrêmement intensif en calcul. Crédit :CMS CERN
Simple d'utilisation, bien que, ne suffit pas lorsqu'il s'agit de données issues de la physique des hautes énergies. Spark semble satisfaire à la fois les objectifs de facilité d'utilisation et de performances dans une certaine mesure. Les chercheurs étudient encore certains aspects de ses performances pour des applications de physique des hautes énergies, mais les informaticiens ne peuvent pas tout avoir. "Il y a un compromis, " Sehrish déclare. " Lorsque vous recherchez plus de performances, vous n'obtenez pas la facilité d'utilisation."
Les scientifiques du Fermilab ont choisi Spark comme premier choix pour explorer la science du big data, et la matière noire n'est que la première application testée. "Nous avons besoin de plusieurs cas d'utilisation réels pour comprendre la faisabilité d'utiliser Spark pour une tâche d'analyse, " dit Sehrish. Avec des scientifiques comme Gutsche au Fermilab, la matière noire était un bon point de départ. Sehrish et Kowalkowski veulent simplifier la vie des scientifiques chargés de l'analyse. "Nous travaillons avec des scientifiques pour comprendre leurs données et travailler avec leurs analyses, " Sehrish dit. « Ensuite, nous pouvons les aider à mieux organiser les ensembles de données, mieux organiser les tâches d'analyse."
Comme première étape de ce processus, Sehrish et Kowalkowski doivent obtenir des données d'expériences de physique des hautes énergies dans Spark. Remarques Kowalkowski, "Vous avez des pétaoctets de données dans des formats expérimentaux spécifiques que vous devez transformer en quelque chose d'utile pour une autre plate-forme."
Les données de départ pour la mise en œuvre de la matière noire sont formatées pour des plates-formes de calcul à haut débit, mais Spark ne gère pas cette configuration. Le logiciel doit donc lire le format de données d'origine et le convertir en quelque chose qui fonctionne bien avec Spark.
En faisant cela, Sehrish explique, « vous devez considérer chaque décision à chaque étape, parce que la façon dont vous structurez les données, la façon dont vous le lisez en mémoire et concevez et implémentez des opérations pour des performances élevées est tout liée. "
Chacune de ces étapes de gestion des données affecte les performances de Spark. Bien qu'il soit trop tôt pour dire combien de performances peuvent être extraites de Spark lors de l'analyse des données de matière noire, Sehrish et Kowalkowski voient que Spark peut fournir un code convivial qui permet aux chercheurs en physique des hautes énergies de lancer un travail sur des centaines de milliers de cœurs. "Spark est bon à cet égard, ", déclare Sehrish. "Nous avons également constaté une bonne mise à l'échelle - ne gaspillant pas de ressources informatiques alors que nous augmentons la taille de l'ensemble de données et le nombre de nœuds."
Personne ne sait si ce sera une approche viable avant de déterminer les performances maximales de Spark pour ces applications. "La clé principale, " dit Kowalkowski, "c'est que nous ne sommes pas encore convaincus que c'est la technologie pour aller de l'avant."
En réalité, Spark lui-même change. Son utilisation extensive de l'open source crée un cycle de développement constant et rapide. Ainsi, Sehrish et Kowalkowski doivent maintenir leur code à jour avec les nouvelles capacités de Spark.
"Le cycle constant de croissance avec Spark est le coût de travailler avec une technologie haut de gamme et quelque chose avec beaucoup d'intérêts de développement, " dit Sehrish.
Cela pourrait prendre quelques années avant que Sehrish et Kowalkowski ne prennent une décision sur Spark. La conversion de logiciels créés pour le calcul à haut débit en de bons outils de calcul hautes performances faciles à utiliser nécessite un réglage fin et un travail d'équipe entre scientifiques expérimentaux et informaticiens. Ou, tu pourrais dire, il faut plus qu'un coup dans le noir.