Crédit :CC0 Domaine public
Une équipe de chercheurs de l'UC Santa Cruz a récemment développé une nouvelle approche d'apprentissage automatique pour caractériser le bonheur, appelé CruzAffect. Leur approche, présenté dans un article pré-publié sur arXiv, peut être appliqué à différents modèles de classification de contenu affectif, comprenant à la fois des classificateurs traditionnels et des réseaux de neurones convolutifs d'apprentissage en profondeur (CNN).
Cette étude récente s'appuie sur des recherches antérieures qui ont exploré la façon dont les gens transmettent l'affect et le bonheur à la première personne. Dans une étude, les mêmes chercheurs ont découvert que les gens ont tendance à décrire des situations, comme "mon ami m'a acheté des fleurs", ou "J'ai un ticket de parking", d'où les autres humains peuvent facilement déduire leurs réactions affectives implicites. Ils ont conclu que la sémantique compositionnelle peut fournir des preuves solides du sentiment associé à un événement donné.

Crédit :Wu et al.
Dans une autre étude, les chercheurs ont essayé de fonder les descriptions linguistiques des événements sur les théories du bien-être et du bonheur. En analysant un corpus de micro-blogs privés extraits d'une application appelée Echo, ils ont examiné dans quelle mesure différents comptes rendus théoriques pouvaient expliquer la variance des scores de bonheur que les utilisateurs d'Echo ont attribués aux événements quotidiens de leur vie.
"Il est difficile de généraliser un événement affectif et de l'associer à des théories du bien-être, " Jiaqi Wu, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. « Dans nos recherches antérieures, nous avons remarqué qu'il n'y a pas une seule théorie qui puisse prédire le sentiment de tous les événements affectifs. Le but de nos travaux récents était d'identifier une sémantique compositionnelle spécifique qui caractérise le sentiment des événements et tente de modéliser le bonheur à un niveau de généralisation plus élevé. Cependant, trouver des caractéristiques génériques pour modéliser le bien-être reste un défi."
L'objectif principal de l'étude récente menée par Wu et ses collègues était d'étudier l'efficacité des méthodes traditionnelles d'apprentissage automatique riches en fonctionnalités et des méthodes d'apprentissage en profondeur pour la classification de contenu affectif. Pour y parvenir, ils ont identifié une série de caractéristiques qui caractérisent le bonheur dans le contenu affectif et les ont appliqués à un classificateur traditionnel, Forêt boostée par XGB, et un CNN.
"Notre projet, appelé CruzAffect, comprend le développement de deux modèles différents :une méthode d'apprentissage automatique traditionnelle (c'est-à-dire la forêt XGBoosted) et un CNN d'apprentissage en profondeur avec intégration de GloVe, " a déclaré Wu. "Nous utilisons des fonctionnalités syntaxiques, caractéristiques émotionnelles, et les caractéristiques du profil, et leurs performances sont stables pour différentes tâches de classification de contenu affectif."
Essentiellement, les chercheurs ont évalué les performances de deux modèles d'apprentissage automatique différents pour la classification de contenu affectif (forêt XGBoosted et CNN), qui ont tous deux analysé le contenu en fonction des caractéristiques qu'ils avaient précédemment identifiées. Ceux-ci inclus:
Ces caractéristiques ont permis aux chercheurs de découvrir des indicateurs essentiels d'implication sociale et de contrôle que différentes personnes pourraient exercer lors de moments heureux. Dans leur étude, ils ont entraîné à la fois le modèle XGBoosted et le modèle CNN avec un apprentissage supervisé sur un ensemble de données de 10, 000 extraits de texte étiquetés. Ils ont également entraîné les modèles à générer des pseudo-étiquettes pour 70, 000 extraits non étiquetés utilisant une approche semi-supervisée bootstappée, car cela leur a permis d'élargir leur ensemble de données. Tous ces extraits de texte ont été extraits de la base de données HappyDB.

CNN Architecture. Crédit :Wu et al.
"Les résultats significatifs de notre étude incluent les modèles syntaxiques intéressants qui se répètent dans différents domaines, " Wu a déclaré. " De tels modèles linguistiques sont susceptibles d'être associés aux théories du bien-être. Nous constatons également que les caractéristiques qui incluent des connaissances d'experts, tels que le dictionnaire LIWC peuvent améliorer les performances du modèle traditionnel ainsi que le modèle d'apprentissage en profondeur dans les tâches de classification de contenu affectif."
Les chercheurs ont évalué les modèles XGBoosted forest et CNN sur la classification binaire des labels d'agence et sociaux, ainsi que sur la prédiction multi-classe des étiquettes de concepts. Leurs évaluations ont donné des résultats prometteurs, suggérant que les caractéristiques identifiées par eux sont particulièrement efficaces pour classer le contenu affectif. Bien que le modèle basé sur CNN ait mieux fonctionné sur les tâches de classification multi-classes, le modèle d'apprentissage automatique traditionnel a obtenu des résultats comparables en utilisant les fonctionnalités qu'ils avaient précédemment identifiées.
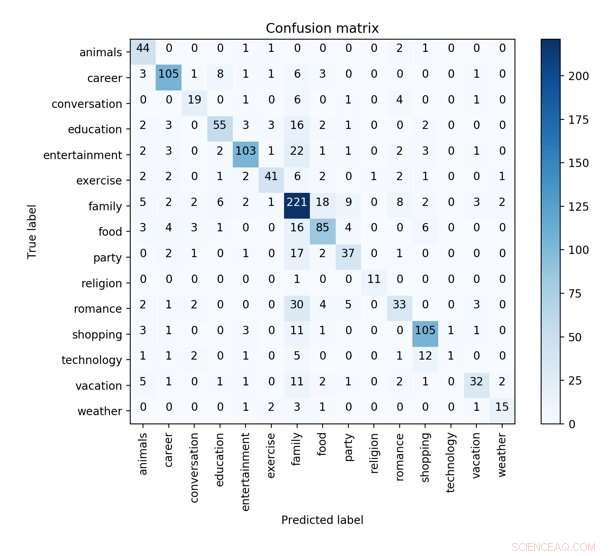
La matrice de confusion du meilleur modèle CNN avec syntaxe, caractéristiques émotionnelles et de profil dans une validation croisée 10 fois pour prédire la caractéristique des concepts. Crédit :Wu et al.
L'étude menée par Wu et ses collègues a révélé des thèmes généraux récurrents dans les descriptions des moments heureux par les gens. À l'avenir, leurs découvertes pourraient éclairer le développement de nouveaux modèles pour les tâches de classification affective, permettant aux chercheurs de prédire efficacement le bien-être et le bonheur en analysant le contenu d'extraits de texte.
« Je vais maintenant explorer l'analyse des événements affectifs interdomaines, et étudier un meilleur modèle pour fonder les descriptions linguistiques des événements vécus par les utilisateurs dans les théories du bien-être et du bonheur, " a déclaré Wu. " Après avoir compris la relation entre le contenu affectif et les théories du bien-être, nous pourrions être en mesure de collecter des événements affectifs généraux qui sont fortement liés au bien-être."

L'équipe de chercheurs qui a mené l'étude. Crédit :Wu et al.
© 2019 Réseau Science X