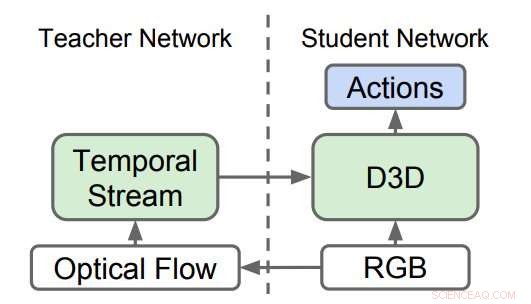
Réseaux 3D distillés (D3D). Les chercheurs ont formé un CNN 3D pour reconnaître les actions de la vidéo RVB tout en distillant les connaissances d'un réseau qui reconnaît les actions des séquences de flux optiques. Lors de l'inférence, seul D3D est utilisé. Crédit :Stroud et al.
Une équipe de chercheurs de Google, l'Université du Michigan et l'Université de Princeton ont récemment développé une nouvelle méthode de reconnaissance d'action vidéo. La reconnaissance d'actions vidéo consiste à identifier des actions particulières effectuées dans des séquences vidéo, comme ouvrir une porte, fermer une porte, etc.
Depuis des années, les chercheurs essaient d'apprendre aux ordinateurs à reconnaître les actions humaines et non humaines sur vidéo. La plupart des outils de reconnaissance d'action vidéo de pointe utilisent un ensemble de deux réseaux de neurones :le flux spatial et le flux temporel.
Dans ces approches, un réseau neuronal est entraîné à reconnaître des actions dans un flux d'images régulières en fonction de l'apparence (c'est-à-dire le « flux spatial ») et le second réseau est entraîné à reconnaître des actions dans un flux de données de mouvement (c'est-à-dire le « flux temporel »). Les résultats obtenus par ces deux réseaux sont ensuite combinés pour obtenir une reconnaissance d'action vidéo.
Bien que les résultats empiriques obtenus à l'aide d'approches « à deux volets » soient excellents, ces méthodes reposent sur deux réseaux distincts, plutôt qu'un seul. Le but de l'étude menée par les chercheurs de Google, l'Université du Michigan et de Princeton devait étudier les moyens d'améliorer cela, afin de remplacer les deux flux de la plupart des approches existantes par un réseau unique qui apprend directement à partir des données.
Dans les études les plus récentes, les flux spatiaux et temporels sont constitués de réseaux de neurones convolutifs (CNN) 3D, qui appliquent des filtres spatio-temporels au clip vidéo avant de tenter la classification. Théoriquement, ces filtres temporels appliqués devraient permettre au flux spatial d'apprendre des représentations de mouvement, par conséquent, le flux temporel devrait être inutile.
En pratique, cependant, les performances des outils de reconnaissance d'action vidéo s'améliorent lorsqu'un flux temporel entièrement séparé est inclus. Ceci suggère que le flux spatial seul est incapable de détecter certains des signaux capturés par le flux temporel.
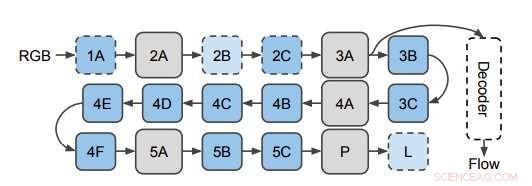
Le réseau utilisé pour prédire le flux optique à partir des caractéristiques 3D de CNN. Les chercheurs appliquent le décodeur aux couches cachées du CNN 3D (représenté ici à la couche 3A). Ce diagramme montre la structure de I3D/S3D-G, où les cases bleues représentent la convolution (lignes pointillées) ou les blocs Inception (lignes pleines), et les cases grises représentent les blocs de mise en commun. Les noms de calques sont les mêmes que ceux utilisés dans Inception. Crédit :Stroud et al.
Pour approfondir cette observation, les chercheurs ont cherché à savoir si le flux spatial de CNN 3-D pour la reconnaissance d'action vidéo manquait effectivement de représentations de mouvement. Ensuite, ils ont démontré que ces représentations de mouvement peuvent être améliorées par distillation, une technique de compression des connaissances d'un ensemble en un seul modèle.
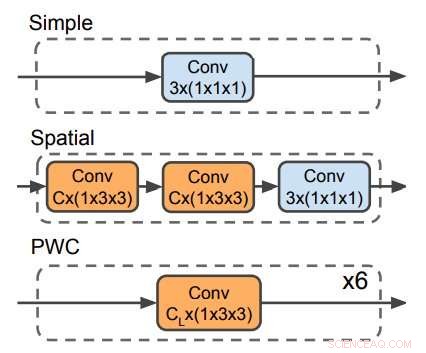
Trois décodeurs utilisés pour prédire le flux optique. Le décodeur PWC ressemble au réseau de prédiction de flux optique de PWC-net. Aucun décodeur n'utilise de filtres temporels. Crédit :Stroud et al.
Les chercheurs ont formé un réseau « d'enseignants » pour reconnaître les actions en fonction de l'entrée de mouvement. Puis, ils ont formé un deuxième réseau « étudiant », qui n'est alimenté que par le flux d'images régulières, avec un double objectif :bien réussir la tâche de reconnaissance d'action et imiter la sortie du réseau d'enseignants. Essentiellement, le réseau étudiant apprend à reconnaître en fonction à la fois de l'apparence et du mouvement, mieux que l'enseignant et ainsi que les modèles à deux volets plus grands et plus encombrants.
Récemment, un certain nombre d'études ont également testé une approche alternative pour la reconnaissance d'actions vidéo, ce qui implique la formation d'un réseau unique avec deux objectifs différents :bien performer à la tâche de reconnaissance d'action et prédire directement les signaux de mouvement de bas niveau (c'est-à-dire le flux optique) dans la vidéo. Les chercheurs ont découvert que leur méthode de distillation surpassait cette approche. Cela suggère qu'il est moins important pour un réseau de reconnaître efficacement le flux optique de bas niveau dans une vidéo que de reproduire les connaissances de haut niveau que le réseau d'enseignants a apprises sur la reconnaissance des actions du mouvement.
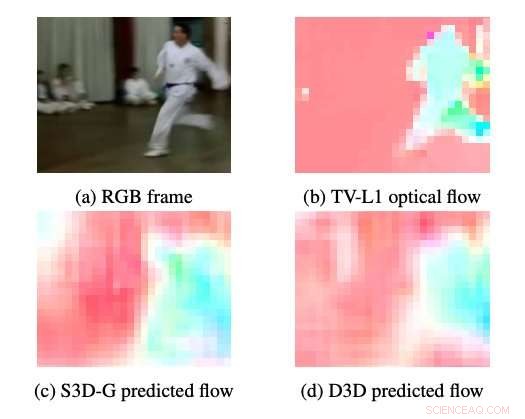
Exemples de flux optiques produits par S3DG et D3D (sans réglage fin) à l'aide du décodeur PWC appliqué à la couche 3A. La couleur et la saturation de chaque pixel correspondent à l'angle et à l'amplitude du mouvement, respectivement. Le flux optique TV-L1 est affiché en 28×28px, la résolution de sortie du décodeur. Crédit :Stroud et al.
Les chercheurs ont prouvé qu'il est possible de former un réseau de neurones à flux unique aussi performant que des approches à deux flux. Leurs résultats suggèrent que les performances des méthodes de pointe actuelles pour la reconnaissance d'actions vidéo pourraient être atteintes en utilisant environ 1/3 du calcul. Cela faciliterait l'exécution de ces modèles sur des appareils soumis à des contraintes de calcul, comme les smartphones, et à plus grande échelle (par exemple pour identifier des actions, comme les « slam dunks », dans les vidéos YouTube).
Globalement, cette étude récente met en évidence certaines des lacunes des méthodes de reconnaissance d'action vidéo existantes, proposer une nouvelle approche qui consiste à former un enseignant et un réseau d'étudiants. La recherche future, cependant, pourrait essayer d'atteindre des performances de pointe sans avoir besoin d'un réseau d'enseignants, en alimentant les données de formation directement au réseau des étudiants.
© 2019 Réseau Science X














