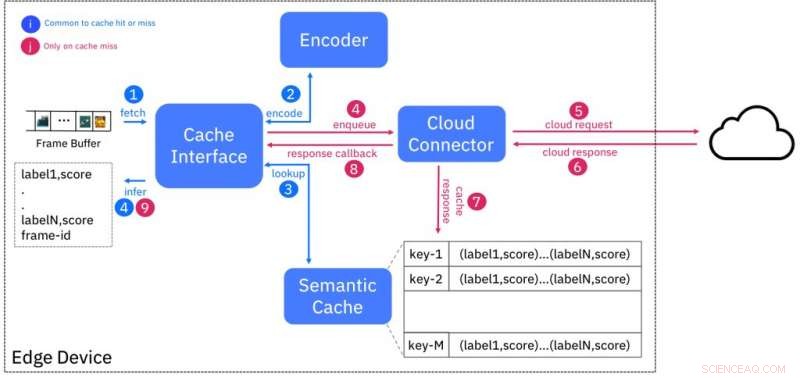
Schéma fonctionnel du service de cache sémantique. Crédit :IBM
La disponibilité de la haute résolution, capteurs bon marché a augmenté de façon exponentielle la quantité de données produites, qui pourrait submerger l'Internet existant. Cela a conduit à la nécessité d'une capacité de calcul pour traiter les données à proximité de l'endroit où elles sont générées, aux bords du réseau, au lieu de l'envoyer aux centres de données cloud. Informatique de pointe, comme cela est connu, réduit non seulement la pression sur la bande passante, mais réduit également la latence d'obtention de renseignements à partir de données brutes. Cependant, la disponibilité des ressources à la périphérie est limitée en raison du manque d'économies d'échelle qui rendent l'infrastructure cloud rentable à gérer et à offrir.
Le potentiel de l'edge computing n'est nulle part plus évident qu'avec l'analyse vidéo. Les caméras vidéo haute définition (1080p) sont de plus en plus courantes dans des domaines tels que la surveillance et, en fonction de la fréquence d'images et de la compression des données, peut produire 4 à 12 mégabits de données par seconde. Les nouvelles caméras à résolution 4K produisent des données brutes de l'ordre du gigabit par seconde. L'exigence d'informations en temps réel sur ces flux vidéo conduit à l'utilisation de techniques d'IA telles que les réseaux de neurones profonds pour des tâches telles que la classification, détection et extraction d'objets, et la détection d'anomalies.
Dans notre article de conférence Hot Edge 2018 "Shadow Puppets:Cloud-level Accurate AI Inference at the Speed and Economy of Edge, " notre équipe d'IBM Research – Irlande a évalué expérimentalement les performances d'une telle charge de travail d'IA, classement d'objets, en utilisant des services hébergés dans le cloud disponibles dans le commerce. Le meilleur résultat que nous ayons pu obtenir était une sortie de classification de 2 images par seconde, ce qui est bien en deçà du taux de production vidéo standard de 24 images par seconde. L'exécution d'une expérience similaire sur un périphérique périphérique représentatif (NVIDIA Jetson TK1) a permis d'atteindre les exigences de latence, mais a utilisé la plupart des ressources disponibles sur le périphérique dans ce processus.
Nous brisons cette dualité en proposant le Cache Sémantique, une approche qui combine la faible latence des déploiements de périphérie avec les ressources quasi infinies disponibles dans le cloud. Nous utilisons la technique bien connue de la mise en cache pour masquer la latence en exécutant l'inférence de l'IA pour une entrée particulière (par exemple, une image vidéo) dans le cloud et en stockant les résultats à la périphérie contre une "empreinte digitale", ou un code de hachage, sur la base des caractéristiques extraites de l'entrée.
Ce schéma est conçu de telle sorte que les entrées étant sémantiquement similaires (par exemple, appartenant à la même classe) aient des empreintes digitales « proches » les unes des autres, selon une certaine mesure de distance. La figure 1 montre la conception du cache. L'encodeur crée l'empreinte digitale d'une image vidéo d'entrée et recherche dans le cache des empreintes digitales à une distance spécifique. S'il y a correspondance, alors les résultats de l'inférence sont fournis à partir du cache, évitant ainsi d'avoir à interroger le service d'IA exécuté dans le cloud.
Nous trouvons les empreintes digitales analogues aux marionnettes d'ombre, projections bidimensionnelles de figures sur un écran créé par une lumière en arrière-plan. Quiconque a utilisé ses doigts pour créer des marionnettes d'ombre attestera que l'absence de détail dans ces figures ne restreint pas leur capacité à être la base d'une bonne narration. Les empreintes digitales sont des projections de l'entrée réelle qui peuvent être utilisées pour des applications d'IA riches même en l'absence de détails originaux.
Nous avons développé une implémentation complète de preuve de concept du cache sémantique, suivant une approche de conception « as a service », et exposer le service aux utilisateurs de périphérique/passerelle de périphérie via une interface REST. Nos évaluations sur une gamme de périphériques divers (Raspberry Pi 3 / NVIDIA Jetson TK1/TX1/TX2) ont démontré que la latence d'inférence a été réduite de 3 fois et l'utilisation de la bande passante d'au moins 50 % par rapport à un cloud. seule solution.
L'évaluation précoce d'un premier prototype de mise en œuvre de notre approche démontre son potentiel. Nous poursuivons la maturation de l'approche initiale, donner la priorité à l'expérimentation de techniques de codage alternatives pour une meilleure précision, tout en étendant l'évaluation à d'autres ensembles de données et tâches d'IA.
Nous envisageons cette technologie pour avoir des applications dans le commerce de détail, maintenance prédictive des installations industrielles, et vidéosurveillance, entre autres. Par exemple, le cache sémantique pourrait être utilisé pour stocker les empreintes digitales des images de produits aux caisses. Cela peut être utilisé pour éviter les pertes de magasins dues à un vol ou à une erreur de numérisation. Notre approche sert d'exemple de basculement transparent entre les services cloud et de périphérie pour fournir les meilleures solutions d'IA à la périphérie.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.