Crédit :Angewandte Chemie
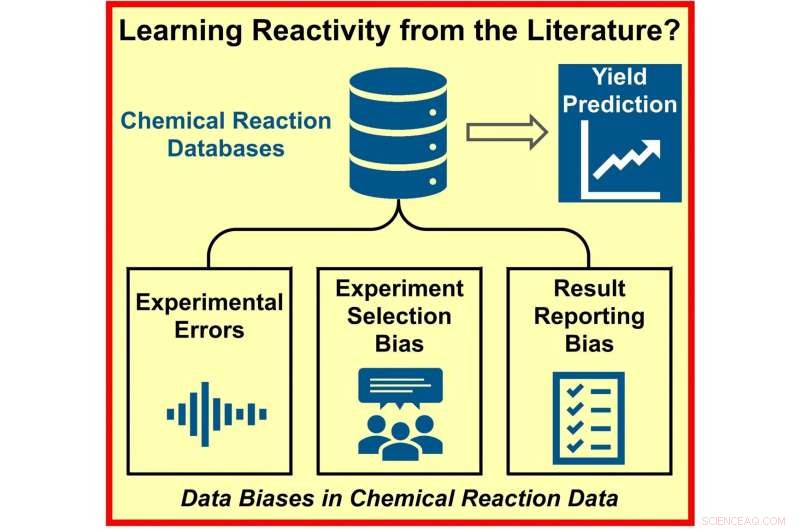
Des bases de données contenant d'énormes quantités de données expérimentales sont à la disposition des chercheurs dans une grande variété de disciplines chimiques. Cependant, une équipe de chercheurs a découvert que les données disponibles ne permettent pas de prédire les rendements de nouvelles synthèses utilisant l'intelligence artificielle (IA) et l'apprentissage automatique. Leur étude publiée dans la revue Angewandte Chemie International Edition suggère que cela est en grande partie dû à la tendance des scientifiques à ne pas signaler les expériences ratées.
Bien que les modèles basés sur l'IA aient été particulièrement efficaces pour prédire les structures moléculaires et les propriétés des matériaux, ils renvoient des prédictions plutôt inexactes pour les informations relatives aux rendements des produits en synthèse, comme l'ont découvert Frank Glorius et son équipe de chercheurs de la Westfälische Wilhelms-Universität Münster, en Allemagne. .
Les chercheurs attribuent cet échec aux données utilisées pour entraîner les systèmes d'IA. "Il est intéressant de noter que la prédiction des rendements de réaction (réactivité) est beaucoup plus difficile que la prédiction des propriétés moléculaires. Les réactifs, les réactifs, les quantités, les conditions, l'exécution expérimentale déterminent tous le rendement et, par conséquent, le problème de la prédiction du rendement devient très data -intensif », explique Glorius. Ainsi, malgré les énormes quantités de littérature et de résultats disponibles, les chercheurs se sont rendu compte que les données ne sont pas adaptées pour des prédictions précises du rendement attendu.
Le problème n'est pas seulement dû à un manque d'expériences. En revanche, l'équipe a identifié trois causes possibles de données biaisées. Premièrement, les résultats des synthèses chimiques peuvent être faussés en raison d'une erreur expérimentale. Deuxièmement, lorsque les chimistes planifient leurs expériences, ils peuvent, consciemment ou inconsciemment, introduire un biais basé sur l'expérience personnelle et le recours à des méthodes bien établies. Enfin, étant donné que seules les réactions avec un résultat positif sont censées contribuer au progrès, les échecs sont signalés moins fréquemment.
Pour savoir lequel de ces trois facteurs avait la plus grande influence, Glorius et l'équipe ont délibérément modifié les ensembles de données pour quatre réactions organiques différentes, couramment utilisées (et donc riches en données). Ils ont artificiellement augmenté l'erreur expérimentale, réduit la taille des ensembles d'échantillonnage de données ou supprimé les résultats négatifs des données. Leurs investigations ont montré que l'erreur expérimentale avait la plus petite influence sur le modèle, tandis que la contribution apportée par l'absence de résultats négatifs était fondamentale.
Le groupe espère que ces découvertes encourageront les scientifiques à toujours signaler les expériences ratées ainsi que leurs succès. Cela améliorerait la disponibilité des données pour la formation de l'IA, contribuant finalement à accélérer la planification et à rendre l'expérimentation plus efficace. Glorius ajoute que "l'apprentissage automatique en chimie (moléculaire) augmentera considérablement l'efficacité et moins de réactions devront être exécutées pour atteindre un certain objectif, par exemple, une optimisation. Cela responsabilisera les chimistes et les aidera à créer des processus chimiques - et le monde — plus durable. Les chimistes utilisent l'énergie lumineuse pour produire de petits anneaux moléculaires