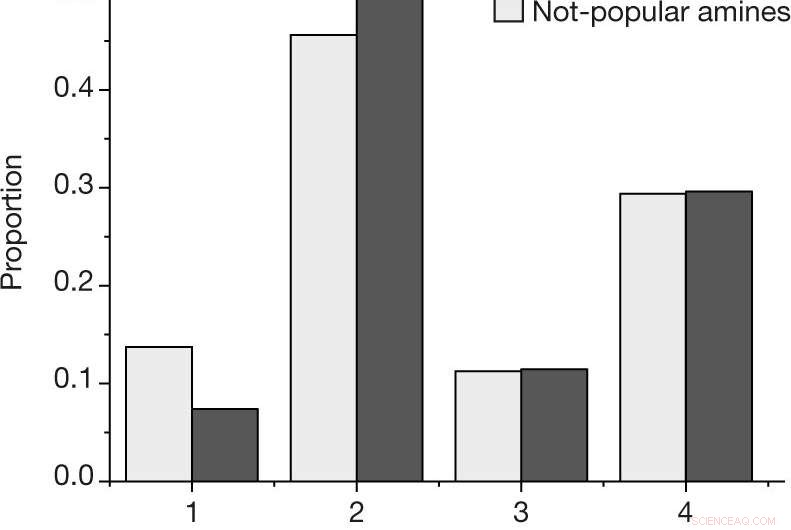
une, La proportion par résultat pour chaque réaction, en utilisant l'échelle de résultats décrite dans Méthodes, pour les amines populaires et non populaires dans l'ensemble de données sélectionné par l'homme. b, Probabilité estimée d'observer au moins une réaction réussie (résultat 4) ou un échec (résultat 1, 2 et 3) pour une amine donnée, pour les N = 27 amines populaires et N = 28 non populaires parmi l'ensemble de données sélectionné par l'homme. Les valeurs centrales indiquent la proportion observée de résultats. Les barres d'erreur indiquent une estimation bootstrap de l'écart type. Crédit: La nature (2019). DOI :10.1038/s41586-019-1540-5
Une équipe de scientifiques des matériaux du Haverford College a montré comment les biais humains dans les données peuvent avoir un impact sur les résultats des algorithmes d'apprentissage automatique utilisés pour prédire de nouveaux réactifs à utiliser dans la fabrication des produits souhaités. Dans leur article publié dans la revue La nature , le groupe décrit le test d'un algorithme d'apprentissage automatique avec différents types d'ensembles de données et ce qu'ils ont trouvé.
L'une des applications les plus connues des algorithmes d'apprentissage automatique est la reconnaissance faciale. Mais il y a des problèmes possibles avec de tels algorithmes. Un de ces problèmes survient lorsqu'un algorithme facial destiné à rechercher un individu parmi de nombreux visages a été formé en utilisant des personnes d'une seule race. Dans ce nouvel effort, les chercheurs se sont demandé si le biais, involontaire ou autre, pourraient apparaître dans les résultats des algorithmes d'apprentissage automatique utilisés dans les applications de chimie conçues pour rechercher de nouveaux produits.
De tels algorithmes utilisent des données décrivant les ingrédients des réactions qui aboutissent à la création d'un nouveau produit. Mais les données sur lesquelles le système est formé pourraient avoir un impact majeur sur les résultats. Les chercheurs notent qu'actuellement, ces données sont obtenues à partir d'efforts de recherche publiés, ce qui signifie qu'ils sont généralement générés par les humains. Ils notent que les données de ces efforts pourraient avoir été générées par les chercheurs eux-mêmes, ou par d'autres chercheurs travaillant sur des efforts séparés. Les données pourraient même provenir d'une seule personne se rapportant simplement de mémoire, ou sur proposition d'un professeur, ou un étudiant diplômé avec une idée lumineuse. Le point est, les données pourraient être biaisées en fonction de l'historique de la ressource.
Dans ce nouvel effort, les chercheurs ont voulu savoir si de tels biais pouvaient avoir un impact sur les résultats des algorithmes d'apprentissage automatique utilisés pour les applications de chimie. Découvrir, ils ont examiné un ensemble spécifique de matériaux appelés borates de vanadium à matrice amine. Lorsqu'ils sont synthétisés avec succès, des cristaux se forment - un moyen facile de déterminer si une réaction a réussi.
L'expérimentation a consisté à entraîner un algorithme de machine learning sur des données entourant la synthèse de borates de vanadium, puis programmer le système pour créer le sien. Certaines des données recueillies par les chercheurs étaient d'origine humaine, et une partie a été collectée au hasard. Ils rapportent que l'algorithme formé sur les données aléatoires a mieux réussi à trouver des moyens de synthétiser les borates de vanadium que lorsqu'il a utilisé des données générées par des humains. Ils prétendent que cela montre un biais clair dans les données créées par les humains.
© 2019 Réseau Science X