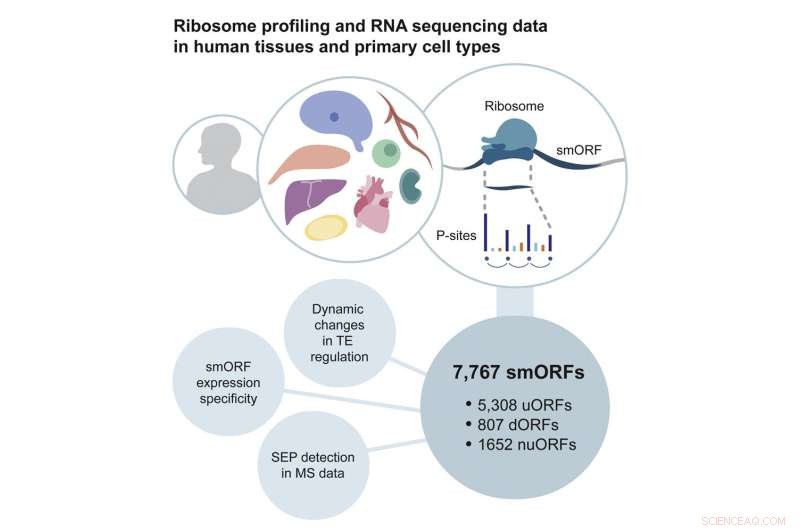
Résumé graphique. Crédit :Cellule moléculaire (2022). DOI :10.1016/j.molcel.2022.06.023
À l'aide d'une nouvelle technique innovante, les scientifiques de la Duke-NUS Medical School et leurs collaborateurs ont identifié des milliers de séquences d'ADN jusque-là inconnues dans le génome humain qui codent pour des microprotéines et des peptides potentiellement critiques pour la santé et la maladie humaines.
"Une grande partie de ce que nous comprenons des 2 % connus du génome qui code pour les protéines provient de la recherche de longs brins de séquences de nucléotides codant pour des protéines, ou de longs cadres de lecture ouverts", a expliqué la biologiste informatique Dr Sonia Chothani, chercheuse chez Programme des troubles cardiovasculaires et métaboliques (CVMD) de Duke-NUS et premier auteur de l'étude. "Récemment, cependant, les scientifiques ont découvert de petits cadres de lecture ouverts (smORF) qui peuvent également être traduits de l'ARN en petits peptides, qui jouent un rôle dans la réparation de l'ADN, la formation musculaire et la régulation génétique."
Les scientifiques ont essayé d'identifier les smORF et les petits peptides qu'ils codent, car la perturbation de ces smORF peut provoquer des maladies. Cependant, les approches actuellement disponibles sont très limitées.
"Une grande partie des ensembles de données actuels ne fournissent pas d'informations suffisamment détaillées pour identifier les smORF dans l'ARN", a ajouté le Dr Chothani. "La majorité provient également d'analyses de cellules humaines immortalisées qui se sont propagées, parfois pendant des décennies, pour étudier la physiologie, la fonction et la maladie des cellules. Cependant, ces lignées cellulaires ne sont pas toujours des représentations précises de la physiologie humaine."
Publication dans Molecular Cell , Chothani et ses collègues à Singapour, en Allemagne, au Royaume-Uni et en Australie décrivent une méthodologie qu'ils ont développée pour résoudre ces problèmes. Ils ont examiné les ensembles de données de profilage des ribosomes actuellement disponibles pour les courts brins d'ARN avec des sections périodiques à trois bases, couvrant plus de 60 % de la longueur de l'ARN. Ils ont ensuite effectué leur propre séquençage d'ARN et profilage des ribosomes pour générer une ressource de données combinée de six types de cellules et de cinq types de tissus, tels que du cœur et du cerveau, provenant de centaines de patients.
Les analyses de ces données ont identifié près de 8 000 smORF. Fait intéressant, ils étaient très spécifiques aux tissus dans lesquels ils ont été trouvés, ce qui signifie que ces smORF peuvent remplir une fonction spécifique à leur environnement. L'équipe a également identifié 603 microprotéines codées par certains de ces smORF.
"Le génome est jonché de smORF", a déclaré le professeur adjoint Owen Rackham, auteur principal de l'étude du programme CVMD. "Notre carte complète et spatialement résolue des smORF humains met en évidence les composants fonctionnels négligés du génome, identifie de nouveaux acteurs de la santé et de la maladie et fournit une ressource à la communauté scientifique en tant que plate-forme pour accélérer les découvertes."
Le professeur Patrick Casey, vice-doyen principal de la recherche à Duke-NUS, a déclaré :« Avec l'évolution du système de santé non seulement pour traiter les maladies mais aussi pour les prévenir, l'identification de nouvelles cibles potentielles pour la recherche sur les maladies et le développement de médicaments pourrait ouvrir la voie à de nouvelles solutions. Cette recherche du Dr Chothani et de son équipe, publiée en tant que ressource pour la communauté scientifique, apporte des informations importantes sur le terrain." Trouver les plus petits gènes pourrait apporter des avantages démesurés