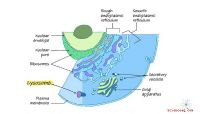
Le code génétique est un «langage» presque universel qui code les directions des cellules. La langue utilise des nucléotides d'ADN, disposés en "codons" de trois, pour stocker les plans pour les chaînes d'acides aminés. Ces chaînes à leur tour forment des protéines, qui comprennent ou régulent tous les autres processus biologiques dans chaque être vivant sur la planète. Le code utilisé pour stocker cette information est presque universel, ce qui implique que tous les êtres vivants qui existent aujourd'hui partagent un ancêtre commun.
Dernier ancêtre commun
Le fait que tous les organismes plus ou moins partager un code génétique implique fortement que tous les organismes partagent un ancêtre commun éloigné. Selon le Centre national d'information sur la biotechnologie, des modèles informatiques ont suggéré que le code génétique que tous les organismes utilisent n'est pas la seule façon dont un code génétique pourrait fonctionner avec les mêmes composants. En fait, certains peuvent même mieux résister aux erreurs, ce qui signifie qu'il est théoriquement possible de faire un «meilleur» code génétique. Le fait que malgré cela, tous les organismes sur Terre utilisent le même code génétique suggère que la vie sur Terre est apparue une fois, et que tous les organismes vivants descendent de la même source.
"Presque" Universel?
Des exceptions au code génétique "universel" existent. Cependant, aucune des exceptions n'est plus que des changements mineurs. Par exemple, les mitochondries humaines utilisent trois codons, qui codent normalement pour les acides aminés, comme des codons «stop», indiquant à la machinerie cellulaire qu'une chaîne d'acides aminés est effectuée. Tous les vertébrés partagent ce changement, ce qui implique fortement que cela s'est produit tôt dans l'évolution des vertébrés. D'autres modifications mineures du code génétique de la méduse et de la gelée en peigne (Cndaria et Ctenophora) ne sont pas trouvées chez les autres animaux. Cela suggère que ce groupe a développé ce changement peu de temps après sa séparation des autres groupes d'animaux. Cependant, on pense que toutes les variations sont finalement dérivées du code standard.
Hypothèse stéréochimique
Il existe une autre hypothèse pour expliquer l'universalité du code génétique. Cette idée, appelée hypothèse stérochimique, soutient que l'arrangement du code génétique provient de contraintes chimiques. Cela signifie que le code génétique est universel car c'est le meilleur moyen d'établir un code génétique dans des conditions terrestres. La preuve de cette idée n'est pas concluante. Bien que certaines données appuient cette idée, les modifications apportées au code génétique, à la fois naturel et artificiel, suggèrent que d'autres codes génétiques pourraient aussi bien fonctionner. Plus important encore, l'hypothèse stéréochimique n'est pas mutuellement exclusive à l'idée que le code génétique est universel en raison de la descendance commune; Les deux concepts pourraient contribuer. Selon un article publié par la biologiste de Princeton, Dawn Brooks et ses collègues dans la revue "Molecular and Biological Evolution", le fait que tous les organismes sont descendus. d'un ancêtre commun signifie que les chercheurs peuvent extrapoler certaines caractéristiques de cet ancêtre commun. En se basant sur les gènes les plus «anciens» dans les organismes vivants, communs à tous les êtres vivants modernes, les chercheurs peuvent discerner quelles protéines et quels acides aminés étaient les plus communs quand existait le dernier ancêtre commun de tous les êtres vivants. Parmi les 22 acides aminés "standard" - ceux trouvés dans le code génétique universel - environ une demi-douzaine apparaissent très rarement dans les protéines du dernier ancêtre commun, impliquant que ces acides aminés étaient très rares ou ils ont été ajoutés à la génétique code plus tard.