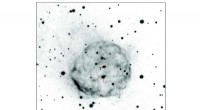
Une jeune étoile semblable au soleil encerclée par son disque planétaire de gaz et de poussière. Crédit :NASA/JPL-Caltech
Dans le cadre d'un effort d'identification de planètes lointaines propices à la vie, La NASA a mis en place un projet de crowdsourcing dans lequel des volontaires recherchent des images télescopiques à la recherche de disques de débris autour des étoiles, qui sont de bons indicateurs d'exoplanètes.
En utilisant les résultats de ce projet, des chercheurs du MIT ont maintenant formé un système d'apprentissage automatique pour rechercher lui-même les disques de débris. L'ampleur de la recherche exige l'automatisation :il existe près de 750 millions de sources lumineuses possibles dans les données accumulées grâce à la seule mission WISE (Wide-Field Infrared Survey Explorer) de la NASA.
Dans les essais, le système d'apprentissage automatique était d'accord avec les identifications humaines des disques de débris 97 pour cent du temps. Les chercheurs ont également entraîné leur système à évaluer les disques de débris en fonction de leur probabilité de contenir des exoplanètes détectables. Dans un article décrivant le nouveau travail dans la revue Astronomie et informatique , les chercheurs du MIT rapportent que leur système a identifié 367 objets célestes non examinés auparavant comme des candidats particulièrement prometteurs pour une étude plus approfondie.
Le travail représente une approche inhabituelle de l'apprentissage automatique, qui a été défendu par l'un des coauteurs de l'article, Victor Pankratius, chercheur principal à l'observatoire Haystack du MIT. Typiquement, un système d'apprentissage automatique passera au peigne fin une multitude de données de formation, rechercher des corrélations cohérentes entre les caractéristiques des données et une étiquette appliquée par un analyste humain - dans ce cas, étoiles entourées de disques de débris.
Mais Pankratius soutient que dans les sciences, les systèmes d'apprentissage automatique seraient plus utiles s'ils incorporaient explicitement un peu de compréhension scientifique, pour aider à guider leurs recherches de corrélations ou identifier les écarts par rapport à la norme qui pourraient présenter un intérêt scientifique.
"La vision principale est d'aller au-delà de ce sur quoi l'IA se concentre aujourd'hui, " dit Pankratius. " Aujourd'hui, nous collectons des données, et nous essayons de trouver des caractéristiques dans les données. Vous vous retrouvez avec des milliards et des milliards de fonctionnalités. Alors qu'est-ce que tu fais avec eux ? Ce que vous voulez savoir en tant que scientifique, ce n'est pas que l'ordinateur vous dise que certains pixels sont certaines caractéristiques. Vous voulez savoir 'Oh, c'est une chose physiquement pertinente, et voici les paramètres physiques de la chose.'"
Conception de la classe
Le nouvel article est né d'un séminaire du MIT que Pankratius a co-enseigné avec Sara Seager, la classe de 1941 professeur de la Terre, Atmosphérique, et sciences planétaires, qui est bien connue pour ses recherches sur les exoplanètes. Le séminaire, Astroinformatique pour les exoplanètes, introduit les étudiants aux techniques de science des données qui pourraient être utiles pour interpréter le flot de données générées par les nouveaux instruments astronomiques. Après avoir maîtrisé les techniques, les étudiants ont été invités à les appliquer à des questions astronomiques en suspens.
Pour son projet final, Tam Nguyen, un étudiant diplômé en aéronautique et astronautique, a choisi le problème de la formation d'un système d'apprentissage automatique pour identifier les disques de débris, et le nouveau document est une excroissance de ce travail. Nguyen est le premier auteur sur le papier, et elle est rejointe par Seager, Pancrace, et Laura Eckman, un baccalauréat spécialisé en génie électrique et en informatique.
Du projet de crowdsourcing de la NASA, les chercheurs avaient les coordonnées célestes des sources lumineuses que des volontaires humains avaient identifiées comme comportant des disques de débris. Les disques sont reconnaissables comme des ellipses de lumière avec des ellipses légèrement plus lumineuses en leur centre. Les chercheurs ont également utilisé les données astronomiques brutes générées par la mission WISE.
Pour préparer les données pour le système d'apprentissage automatique, Nguyen l'a découpé en petits morceaux, puis utilisé des techniques standard de traitement du signal pour filtrer les artefacts causés par les instruments d'imagerie ou par la lumière ambiante. Prochain, elle a identifié ces morceaux avec des sources lumineuses en leurs centres, et utilisé des algorithmes de segmentation d'image existants pour supprimer toute source de lumière supplémentaire. Ces types de procédures sont typiques de tout projet d'apprentissage automatique de vision par ordinateur.
Intuitions codées
Mais Nguyen a utilisé les principes de base de la physique pour affiner davantage les données. Pour une chose, elle a examiné la variation de l'intensité de la lumière émise par les sources lumineuses sur quatre bandes de fréquences différentes. Elle a également utilisé des mesures standard pour évaluer le poste, symétrie, et l'échelle des sources lumineuses, l'établissement de seuils d'inclusion dans son ensemble de données.
En plus des disques de débris étiquetés du projet de crowdsourcing de la NASA, les chercheurs avaient également une courte liste d'étoiles que les astronomes avaient identifiées comme hébergeant probablement des exoplanètes. A partir de ces informations, leur système a également déduit des caractéristiques des disques de débris qui étaient corrélées à la présence d'exoplanètes, sélectionner les 367 candidats pour une étude plus approfondie.
"Compte tenu des défis d'évolutivité liés au big data, tirer parti du crowdsourcing et de la science citoyenne pour développer des ensembles de données de formation pour les classificateurs d'apprentissage automatique pour les observations astronomiques et les objets associés est un moyen innovant de relever les défis non seulement en astronomie, mais également dans plusieurs domaines scientifiques à forte intensité de données, " dit Dan Crichton, qui dirige le Center for Data Science and Technology du Jet Propulsion Laboratory de la NAASA. « L'utilisation du pipeline de découverte assistée par ordinateur décrit pour automatiser l'extraction, classification, et le processus de validation sera utile pour systématiser la manière dont ces capacités peuvent être réunies. Le document fait un bon travail en discutant de l'efficacité de cette approche appliquée aux candidats disques de débris. Les leçons apprises seront importantes pour généraliser les techniques à d'autres applications de l'astronomie et à différentes disciplines. »
"L'équipe scientifique de Disk Detective a travaillé sur son propre projet d'apprentissage automatique, et maintenant que ce papier est sorti, nous allons devoir nous réunir et comparer les notes, " dit Marc Kuchner, un astrophysicien principal au Goddard Space Flight Center de la NASA et chef du projet de détection de disque de crowdsourcing connu sous le nom de Disk Detective. "Je suis vraiment content que Nguyen se penche là-dessus parce que je pense vraiment que ce type de coopération machine-humain va être crucial pour analyser les grands ensembles de données du futur."
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.