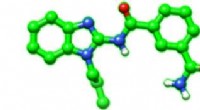
Un exemple de la façon dont le bras du robot utilise des questions d'enquête pour déterminer les préférences de la personne qui l'utilise. Dans ce cas, la personne préfère la trajectoire #1 (T1) à la trajectoire #2. Crédit :Andy Palan et Gleb Shevchuk
Dit d'optimiser la vitesse tout en dévalant une piste dans un jeu informatique, une voiture pousse la pédale jusqu'au métal… et se met à tourner en un petit cercle serré. Rien dans les instructions n'a dit à la voiture de rouler tout droit, et donc il a improvisé.
Cet exemple, amusant dans un jeu informatique mais pas tellement dans la vie, fait partie de ceux qui ont motivé les chercheurs de l'Université de Stanford à créer une meilleure façon de définir des objectifs pour les systèmes autonomes.
Dorsa Sadigh, professeur assistant d'informatique et de génie électrique, et son laboratoire ont combiné deux manières différentes de définir des objectifs pour les robots en un seul processus, qui a fonctionné mieux que l'une ou l'autre de ses parties seules dans les simulations et les expériences dans le monde réel. Les chercheurs ont présenté les travaux le 24 juin au Robotique :science et systèmes conférence.
"À l'avenir, Je m'attends à ce qu'il y ait plus de systèmes autonomes dans le monde et ils vont avoir besoin d'un concept de ce qui est bon et de ce qui est mauvais, " a déclaré Andy Palan, étudiant diplômé en informatique et co-auteur principal de l'article. "C'est essentiel, si nous voulons déployer ces systèmes autonomes à l'avenir, que nous ayons raison."
Le nouveau système de l'équipe pour fournir des instructions aux robots, connu sous le nom de fonctions de récompense, combine des démonstrations, dans lequel les humains montrent au robot ce qu'il doit faire, et sondages sur les préférences des utilisateurs, dans lequel les gens répondent à des questions sur la façon dont ils veulent que le robot se comporte.
« Les démonstrations sont informatives mais elles peuvent être bruyantes. En revanche, les préférences fournissent, au plus, une petite information, mais sont bien plus précis, " a déclaré Sadigh. "Notre objectif est d'obtenir le meilleur des deux mondes, et combiner plus intelligemment les données provenant de ces deux sources pour mieux connaître la fonction de récompense préférée des humains. »
Démonstrations et sondages
Dans des travaux antérieurs, Sadigh s'était concentré sur les seules enquêtes sur les préférences. Ceux-ci demandent aux gens de comparer des scénarios, comme deux trajectoires pour une voiture autonome. Cette méthode est efficace, mais cela peut prendre jusqu'à trois minutes pour générer la question suivante, ce qui est encore lent pour créer des instructions pour des systèmes complexes comme une voiture.
Pour accélérer cela, le groupe a ensuite développé un moyen de produire plusieurs questions à la fois, qui pouvaient être répondues en succession rapide par une seule personne ou réparties entre plusieurs personnes. Cette mise à jour a accéléré le processus de 15 à 50 fois par rapport à la production de questions une par une.
Le nouveau système de combinaison commence par une personne démontrant un comportement au robot. Cela peut donner aux robots autonomes beaucoup d'informations, mais le robot a souvent du mal à déterminer quelles parties de la démonstration sont importantes. Les gens ne veulent pas toujours qu'un robot se comporte exactement comme l'humain qui l'a entraîné.
"On ne peut pas toujours faire des démonstrations, et même quand on peut, nous ne pouvons souvent pas compter sur les informations que les gens donnent, " a déclaré Erdem Biyik, un étudiant diplômé en génie électrique qui a dirigé les travaux d'élaboration des sondages à questions multiples. "Par exemple, des études antérieures ont montré que les gens veulent que les voitures autonomes conduisent moins agressivement qu'eux-mêmes."
C'est là qu'interviennent les sondages, donner au robot une façon de demander, par exemple, si l'utilisateur préfère qu'il déplace son bras vers le bas ou vers le plafond. Pour cette étude, le groupe a utilisé la méthode plus lente de la question unique, mais ils prévoient d'intégrer des enquêtes à questions multiples dans des travaux ultérieurs.
Dans les essais, l'équipe a découvert qu'il était plus rapide de combiner des démonstrations et des enquêtes que de simplement spécifier des préférences et, par rapport aux seules manifestations, environ 80 pour cent des personnes préféraient le comportement du robot lorsqu'il était entraîné avec le système combiné.
"C'est une étape pour mieux comprendre ce que les gens veulent ou attendent d'un robot, " a déclaré Sadigh. "Notre travail rend plus facile et plus efficace pour les humains d'interagir et d'enseigner aux robots, et je suis ravi d'aller plus loin dans ce travail, en particulier en étudiant comment les robots et les humains pourraient apprendre les uns des autres. »
Meilleur, plus rapide, plus intelligent
Les personnes qui ont utilisé la méthode combinée ont déclaré avoir de la difficulté à comprendre ce à quoi le système voulait en venir avec certaines de ses questions, qui leur demandait parfois de choisir entre deux scénarios qui semblaient identiques ou ne semblaient pas pertinents pour la tâche - un problème courant dans l'apprentissage basé sur les préférences. Les chercheurs espèrent combler cette lacune avec des enquêtes plus faciles qui fonctionnent également plus rapidement.
"Regardant vers l'avenir, ce n'est pas évident à 100% pour moi quelle est la bonne façon de créer des fonctions de récompense, mais de façon réaliste, vous allez avoir une sorte de combinaison qui peut résoudre des situations complexes avec une contribution humaine, " a déclaré Palan. " Être capable de concevoir des fonctions de récompense pour les systèmes autonomes est un grand, problème important qui n'a pas reçu toute l'attention qu'il mérite dans le monde universitaire."
L'équipe s'intéresse également à une variante de leur système, ce qui permettrait aux gens de créer simultanément des fonctions de récompense pour différents scénarios. Par exemple, une personne peut vouloir que sa voiture conduise de manière plus prudente dans une circulation lente et plus agressivement lorsque la circulation est faible.
Quand les démos échouent
Parfois, les démonstrations seules ne parviennent pas à transmettre le but d'une tâche. Par exemple, une démonstration dans cette étude a demandé aux gens d'apprendre au bras du robot à se déplacer jusqu'à ce qu'il pointe vers un endroit spécifique sur le sol, et de le faire en évitant un obstacle et sans dépasser une certaine hauteur.
Après qu'un humain ait fait marcher le robot pendant 30 minutes, le robot a essayé d'effectuer la tâche de manière autonome. Il pointait simplement vers le haut. C'était tellement concentré sur l'apprentissage de ne pas heurter l'obstacle, il a complètement raté l'objectif réel de la tâche - pointer vers l'endroit - et la préférence pour rester bas.
Codage manuel et piratage de récompenses
Une autre façon d'enseigner à un robot est d'écrire du code qui agit comme des instructions. Le défi est d'expliquer exactement ce que vous voulez qu'un robot fasse, surtout si la tâche est complexe. Un problème courant est connu sous le nom de "piratage de récompense, " où le robot trouve un moyen plus simple d'atteindre les objectifs spécifiés, comme la voiture qui tourne en rond pour atteindre l'objectif d'aller vite.
Biyik a expérimenté le piratage de récompenses lorsqu'il programmait un bras de robot pour saisir un cylindre et le maintenir en l'air.
"Je lui ai dit que la main doit être fermée, l'objet doit avoir une hauteur supérieure à X et la main doit être à la même hauteur, " a décrit Biyik. " Le robot a fait rouler l'objet cylindrique jusqu'au bord de la table, l'a frappé vers le haut et a ensuite fait un poing à côté de lui en l'air."