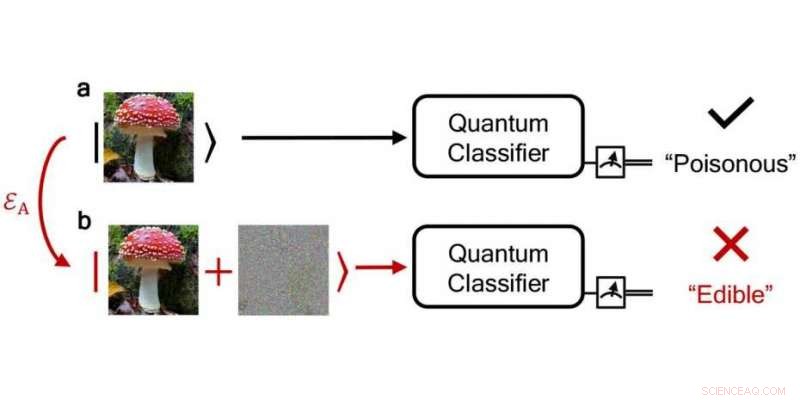
Un algorithme de classification quantique fiable classe correctement un champignon toxique comme « toxique » alors qu'un champignon bruyant, un perturbé le classe à tort comme « comestible ». Crédit :npj Quantum Information / DS3Lab ETH Zurich
Quiconque cueille des champignons sait qu'il vaut mieux séparer les vénéneux et les non vénéneux. Dans de tels "problèmes de classification, " qui nécessitent de distinguer certains objets les uns des autres et d'affecter les objets recherchés à certaines classes au moyen de caractéristiques, les ordinateurs fournissent déjà un soutien utile.
Les méthodes d'apprentissage automatique intelligentes peuvent reconnaître des modèles ou des objets et les sélectionner automatiquement dans des ensembles de données. Par exemple, ils pourraient choisir ces images dans une base de données de photos qui montrent des champignons non toxiques. En particulier avec des ensembles de données très volumineux et complexes, L'apprentissage automatique peut fournir des résultats précieux que les humains ne seraient pas en mesure de déterminer sans beaucoup de temps et d'efforts. Cependant, pour certaines tâches de calcul, même les ordinateurs les plus rapides disponibles aujourd'hui atteignent leurs limites. C'est là qu'entre en jeu la grande promesse des ordinateurs quantiques :un jour, ils pourraient effectuer des calculs ultra-rapides que les ordinateurs classiques ne peuvent pas résoudre en un temps utile.
La raison de cette « suprématie quantique » réside dans la physique :les ordinateurs quantiques calculent et traitent l'information en exploitant certains états et interactions qui se produisent au sein d'atomes ou de molécules ou entre particules élémentaires.
Le fait que les états quantiques puissent se superposer et s'entremêler crée une base qui permet aux ordinateurs quantiques d'accéder à un ensemble fondamentalement plus riche de logique de traitement. Par exemple, contrairement aux ordinateurs classiques, les ordinateurs quantiques ne calculent pas avec des codes binaires ou des bits, qui traitent les informations uniquement comme 0 ou 1, mais avec des bits quantiques ou qubits, qui correspondent aux états quantiques des particules. La différence cruciale est que les qubits peuvent réaliser non seulement un état - 0 ou 1 - par étape de calcul, mais aussi une superposition des deux. Ces méthodes plus générales de traitement de l'information permettent à leur tour une accélération de calcul drastique dans certains problèmes.
Traduire la sagesse classique dans le domaine quantique
Ces avantages de vitesse de l'informatique quantique sont également une opportunité pour les applications d'apprentissage automatique. les ordinateurs quantiques pourraient calculer les énormes quantités de données dont les méthodes d'apprentissage automatique ont besoin pour améliorer la précision de leurs résultats beaucoup plus rapidement que les ordinateurs classiques.
Cependant, pour vraiment exploiter le potentiel de l'informatique quantique, il est nécessaire d'adapter les méthodes classiques d'apprentissage automatique aux particularités des ordinateurs quantiques. Par exemple, algorithmes, c'est à dire., les règles mathématiques qui décrivent comment un ordinateur classique résout un certain problème, doit être formulé différemment pour les ordinateurs quantiques. Développer des algorithmes quantiques qui fonctionnent bien pour l'apprentissage automatique n'est pas tout à fait anodin, car il y a encore quelques obstacles à surmonter en cours de route.
D'un côté, cela est dû au matériel quantique. A l'ETH Zurich, les chercheurs disposent actuellement d'ordinateurs quantiques qui fonctionnent avec jusqu'à 17 qubits (voir « L'ETH Zurich et le PSI ont trouvé Quantum Computing Hub » du 3 mai 2021). Cependant, si les ordinateurs quantiques doivent un jour réaliser leur plein potentiel, ils peuvent avoir besoin de milliers voire de centaines de milliers de qubits.
Le bruit quantique et l'inévitabilité des erreurs
Un défi auquel les ordinateurs quantiques sont confrontés concerne leur vulnérabilité à l'erreur. Les ordinateurs quantiques d'aujourd'hui fonctionnent avec un niveau de bruit très élevé, car les erreurs ou les perturbations sont connues dans le jargon technique. Pour la Société américaine de physique, ce bruit est « l'obstacle majeur à la mise à l'échelle des ordinateurs quantiques ». Il n'existe aucune solution complète pour corriger et atténuer les erreurs. Aucun moyen n'a encore été trouvé pour produire du matériel quantique sans erreur, et les ordinateurs quantiques avec 50 à 100 qubits sont trop petits pour mettre en œuvre des logiciels ou des algorithmes de correction.
Dans une certaine mesure, les erreurs en informatique quantique sont en principe inévitables, parce que les états quantiques sur lesquels reposent les étapes de calcul concrètes ne peuvent être distingués et quantifiés qu'avec des probabilités. Que peut-on réaliser, d'autre part, sont des procédures qui limitent l'étendue du bruit et des perturbations à un point tel que les calculs fournissent néanmoins des résultats fiables. Les informaticiens qualifient une méthode de calcul fiable de « robuste, " et dans ce contexte, parlent également de la "tolérance aux erreurs" nécessaire.
C'est ce que le groupe de recherche dirigé par Ce Zhang, professeur d'informatique à l'ETH et membre de l'ETH AI Center, a récemment exploré, en quelque sorte "accidentellement" lors d'un effort pour raisonner sur la robustesse des distributions classiques dans le but de construire de meilleurs systèmes et plates-formes d'apprentissage automatique. Avec le professeur Nana Liu de l'Université Jiao Tong de Shanghai et le professeur Bo Li de l'Université de l'Illinois à Urbana, ils ont développé une nouvelle approche qui prouve les conditions de robustesse de certains modèles d'apprentissage automatique quantique, pour laquelle le calcul quantique est garanti fiable et le résultat correct. Les chercheurs ont publié leur approche, qui est l'un des premiers du genre, dans la revue scientifique Informations quantiques npj .
Protection contre les erreurs et les pirates
"Quand nous avons réalisé que les algorithmes quantiques, comme les algorithmes classiques, sont sujets aux erreurs et aux perturbations, nous nous sommes demandé comment estimer ces sources d'erreurs et de perturbations pour certaines tâches de machine learning, et comment nous pouvons garantir la robustesse et la fiabilité de la méthode choisie, " dit Zhikuan Zhao, un post-doctorat dans le groupe de Ce Zhang. « Si nous savons cela, nous pouvons faire confiance aux résultats des calculs, même s'ils sont bruyants."
Les chercheurs ont étudié cette question en utilisant des algorithmes de classification quantique comme exemple - après tout, les erreurs dans les tâches de classification sont délicates car elles peuvent affecter le monde réel, par exemple si les champignons vénéneux étaient classés comme non toxiques. Peut-être le plus important, en utilisant la théorie des tests d'hypothèses quantiques - inspirée des travaux récents d'autres chercheurs dans l'application des tests d'hypothèses dans le cadre classique - qui permet de distinguer les états quantiques, les chercheurs de l'ETH ont déterminé un seuil au-dessus duquel les attributions de l'algorithme de classification quantique sont garanties d'être correctes et ses prédictions robustes.
Avec leur méthode de robustesse, les chercheurs peuvent même vérifier si la classification d'une erreur, une entrée bruitée donne le même résultat qu'une entrée propre, entrée silencieuse. De leurs découvertes, les chercheurs ont également développé un schéma de protection qui peut être utilisé pour spécifier la tolérance aux erreurs d'un calcul, indépendamment du fait qu'une erreur a une cause naturelle ou est le résultat d'une manipulation d'une attaque de piratage. Leur concept de robustesse fonctionne à la fois pour les attaques de piratage et les erreurs naturelles.
"La méthode peut également être appliquée à une classe plus large d'algorithmes quantiques, " dit Maurice Weber, un doctorant avec Ce Zhang et le premier auteur de la publication. Étant donné que l'impact de l'erreur dans l'informatique quantique augmente à mesure que la taille du système augmente, lui et Zhao mènent actuellement des recherches sur ce problème. "Nous sommes optimistes que nos conditions de robustesse s'avéreront utiles, par exemple, en conjonction avec des algorithmes quantiques conçus pour mieux comprendre la structure électronique des molécules."