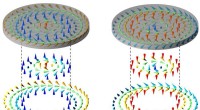
Détecter les erreurs dans les données est une chose, mais leur correction est encore possible au niveau de l'informatique quantique. Crédits :Shutterstock/andriano cz
La puissance de calcul a augmenté de façon exponentielle au cours de plusieurs décennies, alors pourquoi le prochain bond en avant tant promis des ordinateurs quantiques met-il si longtemps à arriver ?
L'une des raisons est que l'information dans un système quantique est sensible au bruit induisant des erreurs, contrairement à l'information classique. Ce bruit est partout et inévitable, résultant des oscillations microscopiques des atomes et des électrons dans toute la matière. Nous devons donc inventer de nouvelles façons de traiter les erreurs quantiques.
Lorsque vous passez un appel téléphonique dans un réseau encombré, ou gratter un CD, la technologie peut encore fonctionner :les conversations restent compréhensibles et la musique continue de jouer.
En effet, ces appareils utilisent des codes de correction d'erreur :même si des erreurs corrompent le flux de données brutes, les informations logiques importantes peuvent encore être reconstituées. Et ceux-ci peuvent être adaptés pour l'informatique quantique.
Un temps sur lequel vous pouvez compter
Pour voir comment cela fonctionne pour le codage classique, considérer la solution utilisée par les premiers navigateurs.
Ils savaient que la longitude pouvait être calculée à partir de l'élévation du Soleil tant que l'heure au port d'attache était connue - d'où l'impératif naval de construire avec précision, horloges stables.
Idéalement, une horloge suffirait, mais que se passe-t-il si quelque chose ne va pas ? Deux horloges c'est mieux, tant qu'ils sont tous les deux d'accord. Mais s'ils ne sont pas d'accord, qui est juste ? Avec trois horloges, un vote majoritaire permet au chronométreur de détecter et de réinitialiser un garde-temps égaré.
Pour les données binaires, représenté par des 0 et des 1, la répétition protège l'information :un bit logique "0" est représenté sur trois bits physiques par 000, tandis que "1" est représenté par 111.
Supposons que pendant la transmission de données de "0", le dernier bit physique a été accidentellement inversé, de sorte que le message reçu est 001. Le destinataire verrait immédiatement qu'une erreur a corrompu les données.
Plus loin, en votant à la majorité, elle devinerait qu'une erreur affectait le troisième bit physique, et décoder correctement le bit logique :"0". Tant que les erreurs sont rares, le code de répétition permettra aux données logiques d'être transmises de manière fiable sur un bruit, canal sujet aux erreurs.
Inconnues connues
Une ride quantique dans cette image est qu'elle implique une "mesure". Le récepteur sait exactement quels bits physiques il a reçus (001 dans l'exemple, dessus), ce qui implique qu'elle devait les mesurer (c'est-à-dire regarde-les).
Mais la mécanique quantique nous dit que l'acte de mesure change fondamentalement l'état d'un système quantique. La simple mesure des bits quantiques (qubits) change le message.
Ainsi, un récepteur quantique n'est pas autorisé à mesurer les qubits directement, mais elle doit encore déterminer si des erreurs se sont produites, et où.
Pour résoudre ce problème, nous revenons au code de répétition à titre indicatif. Au lieu de regarder les valeurs des bits, le récepteur pourrait à la place poser les deux questions suivantes :
S'il n'y avait pas d'erreurs, la réponse à ces deux questions serait "oui", que le message soit 000 ou 111.
Mais si le dernier bit a subi une erreur (réception 001 ou 110), la réponse à Q1 serait "oui" mais Q2 serait "non". De cette réponse, le destinataire peut en déduire l'existence d'une erreur et sa localisation.
De la même manière, une erreur sur le premier bit sera révélée par le motif Q1="Non", Q2="Oui". Une erreur sur le bit du milieu sera révélée par Q1=Q2="Non". Ainsi, toute erreur unique sera déterminée de manière unique par ces réponses, et peut être réparé.
Sachant quel bit physique a subi une erreur, elle le réparerait en retournant délibérément ce bit, pour inverser l'effet de l'erreur d'origine. Cela peut se produire sans connaître l'état du foret endommagé.
Notez que répondre à ces questions ne nécessite qu'une connaissance comparative des bits reçus. Cela ne dépend pas de leur valeur particulière, ni les informations logiques codées.
Ce principe capture l'essence des codes de correction d'erreur quantique. Cela nous permet à la fois d'identifier les erreurs et d'éviter d'endommager les informations quantiques.
Plutôt que de mesurer la valeur des qubits physiques individuels, une série de questions comparatives sont posées :« Les qubits du groupe A sont-ils les mêmes les uns que les autres ? », « Les qubits du groupe B sont-ils les mêmes ? » etc. Les réponses à ces questions donnent des indices sur la localisation des erreurs, mais sans révéler le message lui-même.
Ces réponses sont ensuite utilisées pour déduire et corriger les erreurs probables.
L'information quantique logique est codée dans une autre combinaison de qubits, que nous ne mesurons que lorsque nous voulons vraiment découvrir l'état quantique logique.
Cette démarche est active, et coûteux en temps de calcul pour les grands ensembles de données. Pour certaines applications, il est nécessaire. Mais si les ingénieurs des années 40 avaient dû faire face à une lutte similaire pour développer les premiers ordinateurs, Je soupçonne que l'ordinateur portable sur lequel j'écris ceci n'aurait jamais été construit.
Stabilité magnétique
Au lieu, ils ont eu de la chance, car la nature elle-même effectue gratuitement la correction d'erreurs classique. Les aimants sont incroyablement stables, ils sont donc utilisés pour stocker de grandes quantités d'informations sur des disques durs sans pratiquement aucune correction d'erreur active.
Les aimants ne sont que des collections de nombreux atomes magnétiques qui ont tendance à aligner leurs axes magnétiques les uns avec les autres, ils pointent donc tous vers le "nord".
Si un rayon cosmique frappe spontanément l'orientation magnétique d'un atome, ses voisins atomiques exercent une force magnétique qui le réaligne avec la direction majoritaire. Ainsi, un aimant peut être considéré comme un morceau de matière que l'erreur se corrige passivement, par un vote à la majorité locale.
Malheureusement pour les ordinateurs quantiques, nous ne connaissons pas un tel état passivement stable de la matière quantique. En réalité, nous avons des preuves mathématiques qu'une telle matière ne peut pas exister dans un univers à deux dimensions, alors qu'il peut dans un univers à quatre dimensions.
Jusque là, nous ne savons pas si la matière quantique passivement stable existe dans notre propre univers tridimensionnel.
Nous savons qu'avec suffisamment de compétences et de ressources, nous pouvons corriger activement les erreurs quantiques.
Mais construire une mémoire quantique est un défi permanent. Il n'y a rien de tel qu'un "aimant quantique" pour stocker facilement des informations quantiques pour nous. Nous devons concevoir et construire un tel système à partir de zéro, presque littéralement atome par atome.
L'une des premières tâches majeures d'un ordinateur quantique est d'effectuer une correction d'erreur quantique sur lui-même. Bien que cela paraisse prosaïque, ce sera le premier exemple dans notre univers connu de matière véritablement quantique.
Cet article a été initialement publié sur The Conversation. Lire l'article original.