Centre de données du CERN. Crédit :Robert Hradil, Monika Majer/ProStudio22.ch
Le 29 juin 2017, le DC du CERN a franchi le cap des 200 pétaoctets de données archivées en permanence dans ses bibliothèques de bandes. D'où viennent ces données ? Les particules entrent en collision dans les détecteurs du Grand collisionneur de hadrons (LHC) environ 1 milliard de fois par seconde, générer environ un pétaoctet de données de collision par seconde. Cependant, de telles quantités de données sont impossibles à enregistrer pour les systèmes informatiques actuels et elles sont donc filtrées par les expériences, en ne gardant que les plus "intéressants". Les données LHC filtrées sont ensuite agrégées dans le Centre de données du CERN (DC), où la reconstruction initiale des données est effectuée, et où une copie est archivée dans un stockage sur bande à long terme. Même après la réduction drastique des données effectuée par les expériences, le DC du CERN traite en moyenne un pétaoctet de données par jour. C'est ainsi que la barre des 200 pétaoctets de données archivées en permanence dans ses librairies de bandes a été franchie le 29 juin.
Les quatre grandes expériences LHC ont produit des volumes de données sans précédent au cours des deux dernières années. Cela est dû en grande partie aux performances et à la disponibilité exceptionnelles du LHC lui-même. En effet, en 2016, les attentes étaient initialement d'environ 5 millions de secondes de prise de données, alors que le total final était d'environ 7,5 millions de secondes, une augmentation très bienvenue de 50 %. 2017 suit une tendance similaire.
Plus loin, la luminosité étant plus élevée qu'en 2016, de nombreuses collisions se chevauchent et les événements sont plus complexes, nécessitant une reconstruction et une analyse de plus en plus sophistiquées. Cela a un fort impact sur les besoins informatiques. Par conséquent, des records sont battus dans de nombreux aspects de l'acquisition de données, débits et volumes de données, avec des niveaux d'utilisation exceptionnels pour les ressources de calcul et de stockage.
Pour relever ces défis, l'infrastructure informatique en général, et notamment les systèmes de stockage, a subi des mises à niveau et une consolidation majeures au cours des deux années de Long Shutdown 1. Ces mises à niveau ont permis au centre de données de faire face aux 73 pétaoctets de données reçues en 2016 (dont 49 étaient des données du LHC) et au flux de données livré jusqu'à présent en 2017. Ces mises à niveau ont également permis au système CERN Advanced STORage (CASTOR) de franchir le cap des 200 pétaoctets de données archivées en permanence. Ces données archivées en permanence représentent une fraction importante de la quantité totale de données reçues dans le centre de données du CERN, le reste étant des données temporaires qui sont périodiquement nettoyées.
Une autre conséquence des volumes de données plus importants est une demande accrue de transfert de données et donc un besoin d'une capacité de réseau plus élevée. Depuis début février, un troisième circuit de fibre optique de 100 Gb/s (gigabit par seconde) relie le DC du CERN à son extension distante hébergée au Wigner Research Center for Physics (RCP) en Hongrie, 1800km de distance. La bande passante et la redondance supplémentaires fournies par cette troisième liaison permettent au CERN de bénéficier de manière fiable de la puissance de calcul et du stockage de l'extension distante. Un incontournable dans un contexte de besoins informatiques croissants !
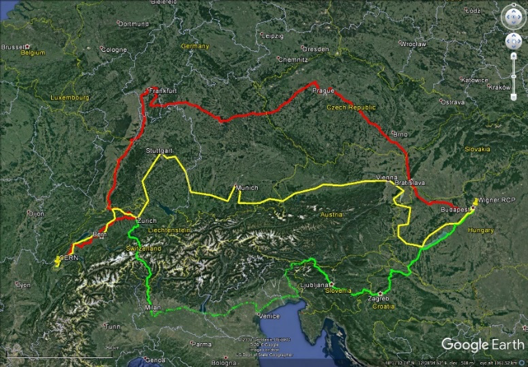
Cette carte montre les routes des trois liaisons fibre 100 Gbit/s entre le CERN et le RCP de Wigner. Les itinéraires ont été choisis avec soin pour garantir que nous maintenons la connectivité en cas d'incident. (Image :Google)