Crédit « Théâtre D'opéra Spatial » :Jason Allen / Midjourney
Un prix d'art à la Colorado State Fair a été décerné le mois dernier à une œuvre qui, à l'insu des juges, a été générée par un système d'intelligence artificielle (IA).
Les médias sociaux ont également vu une explosion d'images étranges générées par l'IA à partir de descriptions textuelles, telles que "le visage d'un shiba inu mélangé au côté d'une miche de pain sur un banc de cuisine, l'art numérique".

Ou peut-être "Une loutre de mer dans le style de 'Jeune fille à la perle' de Johannes Vermeer":

"Une loutre de mer dans le style de la "Fille à la perle" de Johannes Vermeer." Crédit :OpenAI
Vous vous demandez peut-être ce qui se passe ici. En tant que personne qui étudie les collaborations créatives entre les humains et l'IA, je peux vous dire que derrière les gros titres et les mèmes, une révolution fondamentale est en cours, avec de profondes implications sociales, artistiques, économiques et technologiques.
Comment nous en sommes arrivés là
On pourrait dire que cette révolution a commencé en juin 2020, lorsqu'une entreprise appelée OpenAI a réalisé une grande percée dans l'IA avec la création de GPT-3, un système qui peut traiter et générer du langage de manière beaucoup plus complexe que les efforts précédents. Vous pouvez avoir des conversations avec lui sur n'importe quel sujet, lui demander d'écrire un article de recherche ou une histoire, résumer un texte, écrire une blague et effectuer presque toutes les tâches linguistiques imaginables.
En 2021, certains développeurs de GPT-3 se sont tournés vers les images. Ils ont formé un modèle sur des milliards de paires d'images et de descriptions textuelles, puis l'ont utilisé pour générer de nouvelles images à partir de nouvelles descriptions. Ils ont appelé ce système DALL-E, et en juillet 2022, ils ont publié une nouvelle version bien améliorée, DALL-E 2.

Une image générée par DALL-E à partir de l'invite "Mind in Bloom" combinant les styles de Salvador Dali, Henri Matisse et Brett Whiteley". Crédit :Rodolfo Ocampo / DALL-E
Comme GPT-3, DALL-E 2 a été une percée majeure. Il peut générer des images très détaillées à partir d'entrées de texte de forme libre, y compris des informations sur le style et d'autres concepts abstraits.
Par exemple, ici je lui ai demandé d'illustrer la phrase "Mind in Bloom" combinant les styles de Salvador Dalí, Henri Matisse et Brett Whiteley.
Les concurrents entrent en scène
Depuis le lancement de DALL-E 2, quelques concurrents ont fait leur apparition. L'un est le DALL-E Mini gratuit mais de qualité inférieure (développé indépendamment et maintenant renommé Craiyon), qui était une source populaire de contenu meme.
À peu près à la même époque, une petite entreprise appelée Midjourney a publié un modèle qui correspondait plus étroitement aux capacités de DALL-E 2. Bien qu'encore un peu moins performant que DALL-E 2, Midjourney s'est prêté à des explorations artistiques intéressantes. C'est avec Midjourney que Jason Allen a créé l'œuvre d'art qui a remporté le concours Colorado State Art Fair.
Google a également un modèle de texte en image, appelé Imagen, qui produit soi-disant de bien meilleurs résultats que DALL-E et d'autres. Cependant, Imagen n'a pas encore été publié pour une utilisation plus large, il est donc difficile d'évaluer les affirmations de Google.
En juillet 2022, OpenAI a commencé à capitaliser sur l'intérêt pour DALL-E, annonçant qu'un million d'utilisateurs bénéficieraient d'un accès payant.
Cependant, en août 2022, un nouveau concurrent est arrivé :Stable Diffusion.
Stable Diffusion rivalise non seulement avec DALL-E 2 dans ses capacités, mais plus important encore, il est open source. N'importe qui peut utiliser, adapter et modifier le code à sa guise.
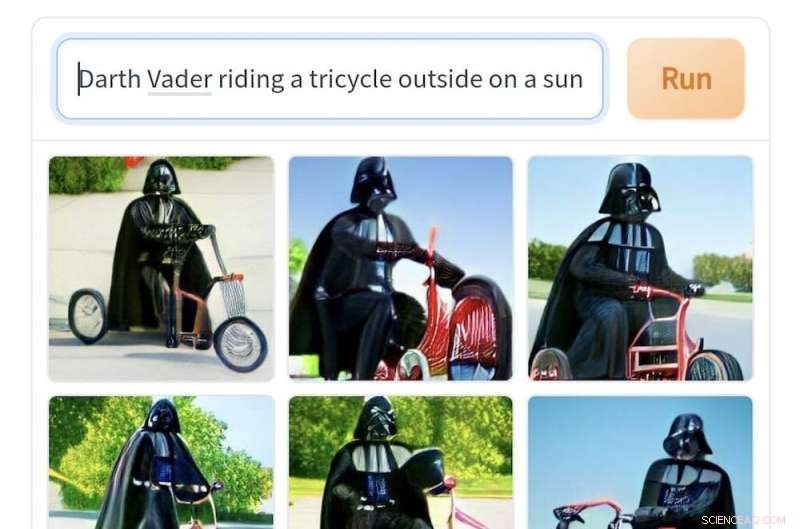
Images générées par Craiyon à partir de l'invite "Darth Vader chevauchant un tricycle dehors par une journée ensoleillée". 1 crédit :Craiyon
Déjà, dans les semaines qui ont suivi la sortie de Stable Diffusion, les gens ont poussé le code aux limites de ce qu'il peut faire.
Pour prendre un exemple :les gens ont rapidement réalisé que, parce qu'une vidéo est une séquence d'images, ils pouvaient modifier le code de Stable Diffusion pour générer de la vidéo à partir de texte.
@StableDiffusion Img2Img x #ebsynth x @koe_recast TEST#stablediffusion #AIart pic.twitter.com/aZgZZBRjWM
– Scott Lighthiser (@LighthiserScott) 7 septembre 2022
Un autre outil fascinant construit avec le code de Stable Diffusion est Diffuse the Rest, qui vous permet de dessiner un croquis simple, de fournir une invite de texte et de générer une image à partir de celui-ci.
La fin de la créativité ?
Qu'est-ce que cela signifie que vous pouvez générer n'importe quel type de contenu visuel, image ou vidéo, avec quelques lignes de texte et un clic sur un bouton ? Et si vous pouviez générer un script de film avec GPT-3 et une animation de film avec DALL-E 2 ?
Et à plus long terme, qu'est-ce que cela signifiera lorsque les algorithmes des médias sociaux non seulement organisent le contenu de votre flux, mais le génèrent ? Et quand cette tendance rencontrera le métaverse dans quelques années, et que des mondes de réalité virtuelle seront générés en temps réel, rien que pour vous ?
Ce sont toutes des questions importantes à considérer.
Certains pensent qu'à court terme, cela signifie que la créativité humaine et l'art sont profondément menacés.
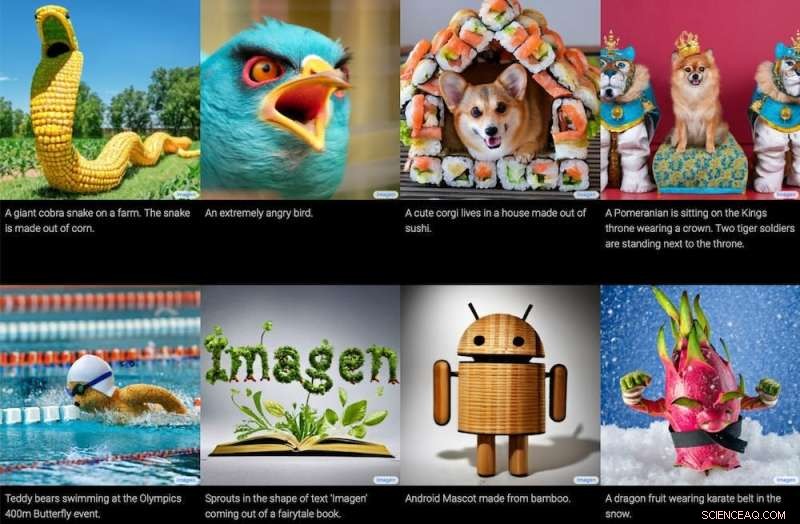
Images generated by the Imagen text-to-image model, together with the text that produced them. Google / Imagen
Perhaps in a world where anyone can generate any images, graphic designers as we know them today will be redundant. However, history shows human creativity finds a way. The electronic synthesizer did not kill music, and photography did not kill painting. Instead, they catalyzed new art forms.
I believe something similar will happen with AI generation. People are experimenting with including models like Stable Diffusion as a part of their creative process.
Or using DALL-E 2 to generate fashion-design prototypes:
Want to use @StableDiffusion right from #Photoshop? Now you can!https://t.co/gqFWpABQLY pic.twitter.com/LbgSWZz31L
— Christian Cantrell (@cantrell) September 8, 2022
A new type of artist is even emerging in what some call "promptology," or "prompt engineering". The art is not in crafting pixels by hand, but in crafting the words that prompt the computer to generate the image:a kind of AI whispering.
Collaborating with AI
The impacts of AI technologies will be multidimensional:we cannot reduce them to good or bad on a single axis.
New artforms will arise, as will new avenues for creative expression. However, I believe there are risks as well.
We live in an attention economy that thrives on extracting screen time from users; in an economy where automation drives corporate profit but not necessarily higher wages, and where art is commodified as content; in a social context where it is increasingly hard to distinguish real from fake; in sociotechnical structures that too easily encode biases in the AI models we train. In these circumstances, AI can easily do harm.
How can we steer these new AI technologies in a direction that benefits people? I believe one way to do this is to design AI that collaborates with, rather than replaces, humans.
Cet article est republié de The Conversation sous une licence Creative Commons. Lire l'article d'origine. AI system makes image generator models like DALL-E 2 more creative