Crédit :Massachusetts Institute of Technology
Pour tous les progrès que les chercheurs ont réalisés avec l'apprentissage automatique pour nous aider à faire des choses comme les chiffres cruciaux, conduire des voitures et détecter le cancer, nous pensons rarement à quel point il est énergivore de maintenir les centres de données massifs qui rendent un tel travail possible. En effet, une étude de 2017 a prédit que, d'ici 2025, Les appareils connectés à Internet utiliseraient 20 % de l'électricité mondiale.
L'inefficacité de l'apprentissage automatique est en partie fonction de la façon dont ces systèmes sont créés. Les réseaux de neurones sont généralement développés en générant un modèle initial, peaufiner quelques paramètres, l'essayer à nouveau, puis rincer et répéter. Mais cette approche signifie qu'un temps significatif, l'énergie et les ressources informatiques sont dépensées sur un projet avant que quiconque ne sache s'il fonctionnera réellement.
Jonathan Rosenfeld, étudiant diplômé du MIT, le compare aux scientifiques du XVIIe siècle cherchant à comprendre la gravité et le mouvement des planètes. Il dit que la façon dont nous développons les systèmes d'apprentissage automatique aujourd'hui - en l'absence de telles compréhensions - a un pouvoir prédictif limité et est donc très inefficace.
« Il n'y a toujours pas de moyen unifié de prédire les performances d'un réseau de neurones compte tenu de certains facteurs tels que la forme du modèle ou la quantité de données sur lesquelles il a été formé, " dit Rosenfeld, qui a récemment développé un nouveau cadre sur le sujet avec des collègues du laboratoire d'informatique et d'intelligence artificielle (CSAIL) du MIT. "Nous voulions explorer si nous pouvions faire avancer l'apprentissage automatique en essayant de comprendre les différentes relations qui affectent la précision d'un réseau."
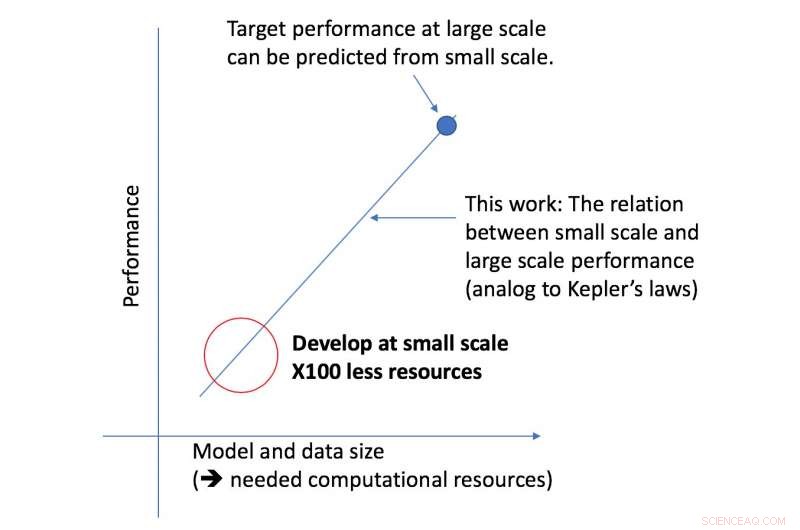
Le nouveau framework de l'équipe CSAIL examine un algorithme donné à plus petite échelle, et, en fonction de facteurs tels que sa forme, peut prédire ses performances à plus grande échelle. Cela permet à un scientifique des données de déterminer s'il vaut la peine de continuer à consacrer plus de ressources à la formation continue du système.
"Notre approche nous dit des choses comme la quantité de données nécessaires à une architecture pour fournir une performance cible spécifique, ou le compromis le plus efficace en termes de calcul entre les données et la taille du modèle, " dit le professeur du MIT Nir Shavit, qui a co-écrit le nouveau papier avec Rosenfeld, ancien étudiant au doctorat Yonatan Belinkov et Amir Rosenfeld de l'Université York. "Nous considérons ces résultats comme ayant des implications de grande envergure dans le domaine en permettant aux chercheurs du monde universitaire et de l'industrie de mieux comprendre les relations entre les différents facteurs qui doivent être pris en compte lors du développement de modèles d'apprentissage en profondeur, et de le faire avec les ressources informatiques limitées dont disposent les universitaires. »
Le cadre a permis aux chercheurs de prédire avec précision les performances à grande échelle de modèles et de données en utilisant cinquante fois moins de puissance de calcul.
L'aspect des performances d'apprentissage en profondeur sur lequel l'équipe s'est concentrée est ce qu'on appelle "l'erreur de généralisation, " qui fait référence à l'erreur générée lorsqu'un algorithme est testé sur des données du monde réel. L'équipe a utilisé le concept de mise à l'échelle du modèle, ce qui implique de modifier la forme du modèle de manière spécifique pour voir son effet sur l'erreur.
Comme prochaine étape, l'équipe prévoit d'explorer les théories sous-jacentes de ce qui fait que les performances d'un algorithme spécifique réussissent ou échouent. Cela comprend l'expérimentation d'autres facteurs qui peuvent avoir un impact sur la formation de modèles d'apprentissage en profondeur.