Crédit :Bıyık et al.
Dans les années récentes, les chercheurs ont essayé de développer des méthodes permettant aux robots d'acquérir de nouvelles compétences. Une option est qu'un robot apprenne ces nouvelles compétences des humains, poser des questions chaque fois qu'il n'est pas sûr de la façon de se comporter, et apprendre des réponses de l'utilisateur humain.
Une équipe de recherche de l'Université de Stanford a récemment développé une approche conviviale de l'apprentissage actif par récompense qui peut être utilisée pour entraîner des robots en demandant aux utilisateurs humains de répondre à leurs questions. Cette nouvelle approche, présenté dans un article prépublié sur arXiv, entraîne les robots à poser des questions auxquelles il sera facile pour un utilisateur humain de répondre et qui ne sont pas redondantes ou inutiles.
"Notre groupe s'intéresse à la façon dont les robots peuvent apprendre ce que les humains veulent, " les chercheurs ont dit TechXplore par e-mail. " Une façon intuitive d'apprendre est de poser des questions. Par exemple, préférez-vous une voiture autonome à conduire prudemment ou agressivement ? Cette voiture autonome devrait-elle fusionner devant ou derrière une voiture à conduite humaine ? »
L'hypothèse principale qui sous-tend l'étude récente est qu'idéalement, les robots doivent poser des questions informatives qui obtiennent autant d'informations que possible de la part des utilisateurs humains. En d'autres termes, un robot doit être capable de comprendre ce dont un humain a besoin ou veut qu'il fasse en posant le moins de questions possible.
En réalité, cependant, la plupart des approches de formation existantes basées sur la réponse aux questions ne considèrent pas à quel point il sera facile pour les utilisateurs humains de répondre à des questions spécifiques formulées par le robot. Cela a souvent pour résultat que les utilisateurs perdent leur temps à répondre à des tas de questions inutiles ou sont incapables de répondre avec certitude.
"Nous avons constaté que la plupart des algorithmes de pointe montrent les alternatives humaines qui sont (presque) indiscernables, empêcher la personne de répondre correctement aux questions du robot, " les chercheurs ont dit. " Revenant à notre exemple, ces approches pourraient demander :« Préférez-vous fusionner devant la voiture à conduite humaine à une vitesse de 29 mph ? ou une vitesse de 31 mph ?" Cela peut être informatif pour le robot pour décider si l'humain veut aller plus vite que 30 mph ou non, mais les options sont si proches que les humains ne peuvent pas répondre de manière fiable. »
Pour surmonter les limites des méthodes d'apprentissage actif existantes, les chercheurs ont développé un algorithme qui peut sélectionner des questions plus efficaces à poser aux utilisateurs humains. L'algorithme identifie les questions qui réduisent le plus l'incertitude du robot sur les préférences d'un utilisateur humain (c'est-à-dire, qui maximisent le gain d'information), tout en considérant également à quel point il sera facile pour un utilisateur humain d'y répondre.

Crédit :Bıyık et al.
« Inspiré par les lacunes des travaux antérieurs, lorsque nous avons développé cet algorithme, nous nous sommes concentrés sur la capacité de l'humain à répondre réellement aux questions posées par le robot, ", ont déclaré les chercheurs. "Ceci est basé sur l'idée que seuls les robots qui tiennent compte de la capacité de l'homme à répondre peuvent apprendre avec précision et efficacité ce que les humains veulent."
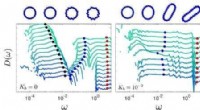
Les chercheurs ont calculé le gain d'informations en mesurant la diminution de l'entropie (c'est-à-dire, une mesure d'incertitude) sur les préférences de l'utilisateur humain en fonction de la question posée par le robot. En d'autres termes, une question qui maximise le gain d'informations réduira le plus l'incertitude du robot quant aux préférences de l'utilisateur humain. Cela donne aux robots un objectif formel qu'ils peuvent utiliser pour sélectionner les questions les plus informatives.
"Une caractéristique intéressante du gain d'informations est qu'il maximise intrinsèquement l'incertitude du robot (afin que le robot apprenne beaucoup de la question) tout en minimisant l'incertitude de l'humain (afin que la question soit facile à répondre pour l'humain), " les chercheurs ont expliqué. " Générer les questions en utilisant le gain d'information améliore ainsi l'apprentissage actif, non seulement parce que les questions sont au maximum informatives, mais aussi parce que l'humain donne moins de réponses erronées."
L'approche imaginée par les chercheurs sélectionne avec gourmandise la question qui maximise le gain d'information à chaque pas de temps. Essentiellement, le robot maintient une croyance (c'est-à-dire, une distribution de probabilité) sur les préférences de l'utilisateur avec lequel il interagit et des échantillons à la fois de cette croyance et de l'espace des questions possibles.
Finalement, le robot choisit la question qui fournit le plus d'informations sur la distribution actuelle des préférences humaines possibles. Ensuite, il met à jour ses croyances sur ce que veut l'utilisateur en fonction de la réponse qu'il reçoit. Ce processus est répété en continu, permettant au robot d'améliorer progressivement ses performances en apprenant les préférences de l'utilisateur.
"Nous avons formulé une méthode calculable qui nous permet de découvrir rapidement les préférences humaines sur de vraies tâches robotiques, surpassant les méthodes précédentes, " les chercheurs ont dit. " Dans notre étude, les utilisateurs ont préféré notre méthode à d'autres techniques de pointe."
Dans leur étude, l'équipe basée à Stanford a montré que former un robot à poser des questions qui maximisent le gain d'informations a la même complexité de calcul que les méthodes de pointe. En d'autres termes, il n'est pas plus difficile pour le robot de trouver ces questions informatives, par rapport à celles générées par d'autres approches.
"Nous soulignons également que notre approche a plusieurs propriétés mathématiques souhaitables, comme la sous-modularité, ce qui nous permet de reprendre les extensions et les bornes théoriques qui ont été développées pour les approches antérieures et de les utiliser également avec notre méthode, " les chercheurs ont dit. "Par exemple, nous pouvons utiliser des travaux antérieurs pour trouver plusieurs questions informatives à la fois, au lieu de chercher une question à la fois."
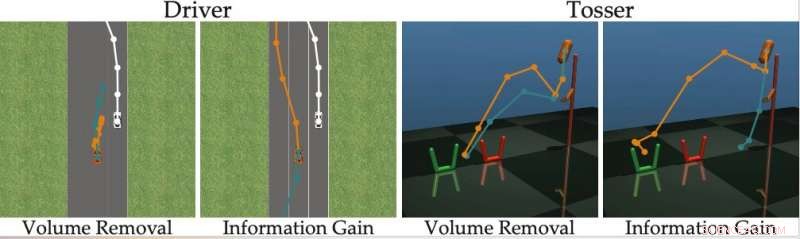
L'équipe a évalué son approche active d'apprentissage par récompense dans une série de simulations et a découvert qu'elle permet aux robots de saisir les préférences humaines plus rapidement et avec plus de précision que d'autres méthodes de pointe. Cela s'est également avéré vrai dans des situations dans lesquelles les humains peuvent répondre correctement à des questions difficiles ou lorsque leur réponse est "Je ne sais pas".
Les chercheurs ont également mené une étude sur les utilisateurs dans laquelle ils ont demandé à des participants humains de répondre à des questions générées par leur méthode et à d'autres générées à l'aide d'autres approches de pointe. Les commentaires qu'ils ont recueillis suggèrent que les gens trouvent beaucoup plus facile de répondre aux questions générées par leur approche. En outre, les utilisateurs ont souvent estimé que les robots utilisant la nouvelle méthode avaient acquis une représentation plus précise de leurs préférences qu'ils ne l'avaient fait avec les approches proposées précédemment.
"Considering all of our contributions together, we took a step toward enabling robots to determine human preferences, " the researchers said. "We showed that the true objective that we originally wanted the robot to maximize—-asking questions to gain as much information as possible—-can actually be solved with the same computational complexity as existing methods."
À l'avenir, the active reward-learning technique developed by this team of researchers could help to train robots more effectively, making them more attuned to user preferences. En outre, it could be used to teach robots to ask questions that humans can easily understand and answer. In their future studies, the researchers would also like to investigate methods for training robots to give useful explanations for their actions.
"We are excited about robots that not only ask good questions, but can also explain why they are asking those questions, " the researchers said. "We imagine a scenario where a self-driving car visualizes two different merging options for the human, and then clarifies that it is asking about these options because it is rush hour, and it wants to determine whether it should behave more or less aggressively."
© 2019 Réseau Science X