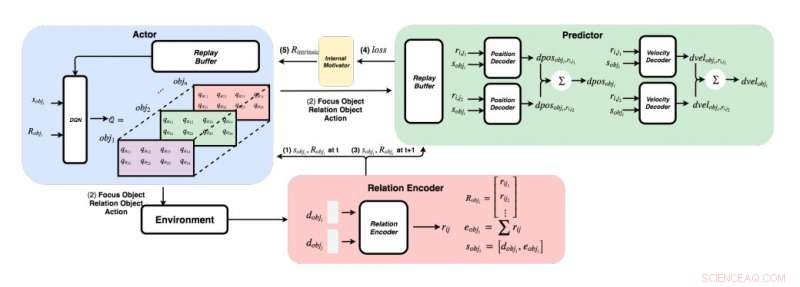
Un schéma détaillé de l'approche développée par les chercheurs. (En bas à droite) Pour chaque paire d'objets, les chercheurs introduisent leurs caractéristiques dans un encodeur de relation pour obtenir la relation rij et l'état sobji de l'objet i. (En haut à gauche) En utilisant la méthode gourmande, pour chaque objet, ils trouvent la valeur Q maximale pour obtenir notre objet focus, objet relationnel, et action. (En haut à droite) Une fois qu'ils ont rassemblé leur objet de focus et leur objet de relation, ils alimentent leurs états et toutes leurs relations à leurs décodeurs pour prédire le changement de position et le changement de vitesse. Crédit :Choi &Yoon.
Dès leurs premières années de vie, les êtres humains ont la capacité innée d'apprendre en continu et de construire des modèles mentaux du monde, simplement en observant et en interagissant avec des choses ou des personnes dans leur environnement. Des études de psychologie cognitive suggèrent que les humains font un usage intensif de ces connaissances précédemment acquises, en particulier lorsqu'ils sont confrontés à de nouvelles situations ou lorsqu'ils prennent des décisions.
Malgré les avancées récentes significatives dans le domaine de l'intelligence artificielle (IA), la plupart des agents virtuels nécessitent encore des centaines d'heures de formation pour atteindre des performances de niveau humain dans plusieurs tâches, tandis que les humains peuvent apprendre à accomplir ces tâches en quelques heures ou moins. Des études récentes ont mis en évidence deux facteurs clés de la capacité des humains à acquérir des connaissances si rapidement, à savoir, physique intuitive et psychologie intuitive.
Ces modèles d'intuition, qui ont été observés chez l'homme dès les premiers stades de développement, pourraient être les principaux facilitateurs de l'apprentissage futur. Sur la base de cette idée, Des chercheurs du Korea Advanced Institute of Science and Technology (KAIST) ont récemment développé une méthode de normalisation de la récompense intrinsèque qui permet aux agents d'IA de sélectionner les actions qui améliorent le plus leurs modèles d'intuition. Dans leur papier, prépublié sur arXiv, les chercheurs ont spécifiquement proposé un réseau de physique graphique intégré à un apprentissage par renforcement profond inspiré du comportement d'apprentissage observé chez les nourrissons humains.
« Imaginez des nourrissons humains dans une pièce avec des jouets qui traînent à une distance accessible, " expliquent les chercheurs dans leur article. " Ils s'emparent constamment, lancer et exécuter des actions sur des objets; parfois, ils observent les conséquences de leurs actes, mais parfois, ils se désintéressent et passent à un autre objet. Le point de vue de « l'enfant en tant que scientifique » suggère que les nourrissons humains sont intrinsèquement motivés pour mener leurs propres expériences, découvrez plus d'informations, et finalement apprendre à distinguer différents objets et à en créer des représentations internes plus riches."
Des études en psychologie suggèrent que dans leurs premières années de vie, les humains expérimentent continuellement avec leur environnement, et cela leur permet de former une compréhension clé du monde. De plus, lorsque les enfants observent des résultats qui ne répondent pas à leurs attentes antérieures, ce qui est connu sous le nom de violation des attentes, ils sont souvent encouragés à expérimenter davantage pour mieux comprendre la situation dans laquelle ils se trouvent.
L'équipe de chercheurs du KAIST a tenté de reproduire ces comportements chez les agents d'IA en utilisant une approche d'apprentissage par renforcement. Dans leur étude, ils ont d'abord introduit un réseau de physique graphique qui peut extraire les relations physiques entre les objets et prédire leurs comportements ultérieurs dans un environnement 3D. Ensuite, ils ont intégré ce réseau à un modèle d'apprentissage par renforcement profond, introduire une technique de normalisation de récompense intrinsèque qui encourage un agent d'IA à explorer et à identifier des actions qui amélioreront continuellement son modèle d'intuition.
A l'aide d'un moteur physique 3D, les chercheurs ont démontré que leur réseau de physique graphique peut efficacement déduire les positions et les vitesses de différents objets. Ils ont également découvert que leur approche permettait au réseau d'apprentissage par renforcement profond d'améliorer continuellement son modèle d'intuition, l'encourageant à interagir avec des objets uniquement sur la base d'une motivation intrinsèque.
Dans une série d'évaluations, la nouvelle technique mise au point par cette équipe de chercheurs atteint une précision remarquable, avec l'agent d'IA effectuant un plus grand nombre d'actions exploratoires différentes. À l'avenir, cela pourrait éclairer le développement d'outils d'apprentissage automatique qui peuvent apprendre de leurs expériences passées plus rapidement et plus efficacement.
"Nous avons testé notre réseau sur des problèmes stationnaires et non stationnaires dans diverses scènes avec des objets sphériques avec des masses et des rayons variables, ", expliquent les chercheurs dans leur article. "Notre espoir est que ces modèles d'intuition pré-entraînés seront plus tard utilisés comme connaissances préalables pour d'autres tâches orientées vers un objectif telles que les jeux ATARI ou la prédiction vidéo."
© 2019 Réseau Science X