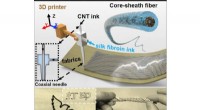
Comparaison des modèles de prédiction de profondeur à un clip vidéo avec des caméras et des personnes en mouvement. Crédit :Google
Qui a dit que l'engouement viral appelé Mannequin Challenge (MC) était terminé et dépoussiéré ? Pas ainsi. Les chercheurs se sont tournés vers le Défi qui a attiré l'attention en 2016 pour servir leur objectif. Ils ont utilisé le MC pour former un réseau de neurones capable de reconstruire les informations de profondeur à partir des vidéos.
"Learning the Depths of Moving People by Watching Frozen People" est le nom de leur article, maintenant sur arXiv, écrit par Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noé Snavely, Ce Liu et William Freeman. Le document a été soumis en avril de cette année.
Le défi du mannequin ? Qui peut oublier ? C'était une tendance YouTube devenue virale. Anthony Alford dans InfoQ ramené les lecteurs en 2016, lorsqu'un mème Internet a fait équiper des personnes en groupes pour se faire passer pour des mannequins. Ils étaient "gelés" mais un vidéaste se déplaçait autour de la scène en prenant une vidéo sous différents angles.
Alford a écrit, car la caméra bouge et le reste de la scène est statique, Les méthodes de parallaxe peuvent facilement reconstruire des cartes de profondeur précises de figures humaines dans une variété de poses.
Comme les auteurs l'ont déclaré, les vidéos impliquaient de geler dans divers, postures naturelles, tandis qu'une caméra à main a fait le tour de la scène.
Pour entraîner le réseau de neurones, l'équipe a converti 2, 000 des vidéos en images 2D avec des données de profondeur haute résolution.
Alford a dit que sur les 2, 000 vidéos YouTube MC, un jeu de données a été produit de 4, 690 séquences avec un total de plus de 170K paires de profondeur d'image valides. La cible du système d'apprentissage était la carte de profondeur connue pour l'image d'entrée, calculé à partir des vidéos MC. Le DNN a appris à prendre l'image d'entrée, carte de profondeur initiale, et masque humain, et produire une carte de profondeur "affinée" où les valeurs de profondeur des humains ont été renseignées.
Christine Fisher, Engagé :"Pour entraîner le réseau de neurones, les chercheurs ont converti les clips en images 2D, estimé la pose de la caméra et créé des cartes de profondeur. L'IA a ensuite été capable de prédire la profondeur des objets en mouvement dans les vidéos avec une plus grande précision qu'auparavant."
Relever le défi a été décrit par deux des co-auteurs de l'article en mai dans un blog Google.
"Parce que toute la scène est immobile (seule la caméra est en mouvement), les méthodes basées sur la triangulation, telles que la stéréo multi-vues (MVS), fonctionnent, et nous pouvons obtenir des cartes de profondeur précises pour toute la scène, y compris les personnes qui s'y trouvent. Nous avons rassemblé environ 2000 vidéos de ce type, couvrant un large éventail de scènes réalistes avec des personnes posant naturellement dans différentes configurations de groupe." Tali Dekel, chercheur scientifique et Forrester Cole, ingénieur logiciel, perception de la machine, a écrit plus sur le défi qu'ils ont relevé.
« Le système visuel humain a une capacité remarquable à donner un sens à notre monde en 3D à partir de sa projection en 2D. Même dans des environnements complexes avec de multiples objets en mouvement, les gens sont capables de maintenir une interprétation réalisable de la géométrie et de l'ordre de profondeur des objets. Le domaine de la vision par ordinateur a longtemps étudié comment atteindre des capacités similaires en reconstruisant informatiquement la géométrie d'une scène à partir de données d'image 2D, mais une reconstruction robuste reste difficile dans de nombreux cas."
Pourquoi c'est important : « Bien qu'il y ait eu une recrudescence récente de l'utilisation de l'apprentissage automatique pour la prédiction de la profondeur, ce travail est le premier à adapter une approche basée sur l'apprentissage au cas de la caméra et du mouvement humain simultanés, " ont-ils déclaré dans le blog de mai. " Dans ce travail, nous nous concentrons spécifiquement sur les humains car ils sont une cible intéressante pour la réalité augmentée et les effets vidéo 3D."
En parlant de résultats, Karen Hao, Examen de la technologie du MIT , ont déclaré que les chercheurs ont converti 2, 000 des vidéos en images 2D avec des données de profondeur haute résolution et les ont utilisées pour former un réseau de neurones. Il était alors capable de prédire la profondeur des objets en mouvement dans une vidéo avec une précision beaucoup plus élevée que ce qui était possible avec les méthodes de pointe précédentes.
© 2019 Réseau Science X