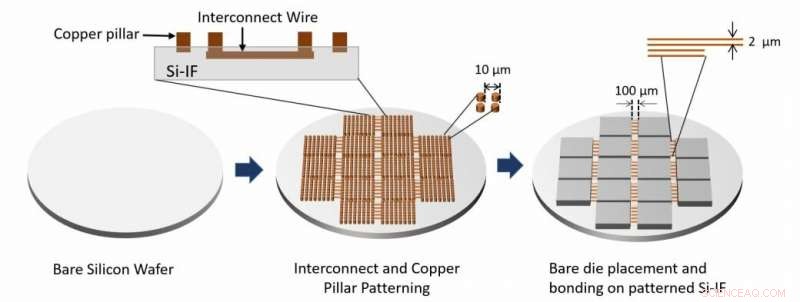
Le flux de processus d'assemblage du système est affiché. Les couches d'interconnexion et les piliers de cuivre sont fabriqués en traitant la plaquette de silicium nue. Les matrices nues sont ensuite collées sur la plaquette à l'aide de TCB. Crédit :Architecting Waferscale Processors - A GPU Case Study, HPCA 19.
Des chercheurs de l'Université de l'Illinois à Urbana-Champaign et de l'Université de Californie, Los Angeles, sont à l'origine du récent développement d'un ordinateur à l'échelle d'une plaquette qui vise à être plus rapide, plus économe en énergie, que leurs homologues contemporains.
Les ingénieurs visent à utiliser quelque chose appelé « tissu d'interconnexion en silicium » pour construire un ordinateur avec 40 GPU sur une seule plaquette de silicium. TechSpot et d'autres sites ont rendu compte de leur travail et de leur papier, à présenter ce mois-ci.
Quelques informations sur Si-IF :« Au cours des deux dernières décennies, les puces de silicium ont diminué de taille de 1000x, alors que les emballages sur les circuits imprimés n'ont rétréci que de 4x, ", a déclaré UCLA Technology Development Group. Une solution est "le tissu d'interconnexion en silicium (Si-IF)".
Samuel Moore à Spectre IEEE a un article très cité sur le sujet où il a noté des résultats :« Les simulations de ce monstre multiprocesseur ont accéléré les calculs de près de 19 fois et ont réduit la combinaison de la consommation d'énergie et du retard du signal de plus de 140 fois.
À savoir, l'effort de recherche est parmi les membres du département de génie électrique et informatique, Université de Californie, Los Angeles, et département de génie électrique et informatique, Université de l'Illinois à Urbana-Champaign. Leur article s'intitule "Architecting Waferscale Processors—A GPU Case Study".
Le professeur agrégé d'ingénierie informatique lllinois Rakesh Kumar et ses collègues ont déjà commencé à travailler pour construire un prototype de système de processeur prototype à l'échelle d'une plaquette. Le groupe l'explorera plus avant pour avoir un aperçu des problèmes qui pourraient survenir. Ils pensaient que le moment était venu de revisiter les architectures à l'échelle des plaquettes.
Mark Tyson dans Hexus :"Les ingénieurs de l'Université de l'Illinois à Urbana-Champaign et de l'Université de Californie à Los Angeles pensent qu'il est temps d'essayer à nouveau de créer un ordinateur à l'échelle d'une plaquette."
L'accent peut être mis sur le mot revisiter . L'équipe a écrit dans son article, « Sans surprise, les processeurs waferscale ont été largement étudiés dans les années 80. Il y a également eu plusieurs tentatives commerciales de construction de processeurs à l'échelle des plaquettes. Malheureusement, malgré la promesse, ces processeurs n'ont pas pu réussir dans le grand public en raison de problèmes de rendement."
Ils ont dit "plus la taille du processeur est grande, plus le rendement était faible, le rendement à l'échelle des plaquettes à l'époque était débilitant. Nous soutenons que des progrès considérables dans la technologie de fabrication et d'emballage ont été réalisés depuis lors et qu'il est peut-être temps de revoir la faisabilité des processeurs à l'échelle des plaquettes. »
Le professeur agrégé d'ingénierie informatique de l'Illinois, Rakesh Kumar, et ses collaborateurs sont sur le point de plaider en faveur d'un ordinateur à l'échelle d'une plaquette comprenant jusqu'à 40 GPU. Le meilleur titre pour nous rappeler pourquoi c'est intéressant peut être trouvé à Spectre IEEE . "Quoi de mieux que 40 serveurs GPU ? Un serveur avec 40 GPU."
Ce qui est spécial :ils ont des puces GPU standard qui ont passé avec succès les tests de qualité. Ils créent une technologie qu'ils appellent le tissu d'interconnexion en silicium (SiIF) pour mieux les connecter.
Shawn Knight dans TechSpot écrit à ce sujet. "Avec une intégration aussi étroite, " dit Chevalier, "du point de vue du programmeur, cela ressemblerait à un GPU géant plutôt qu'à 40 GPU individuels."
SiIF remplace le circuit imprimé par du silicium; il n'y a pas besoin d'un paquet de puces, dit Moore. Il a rapporté que dans une conception, ils étaient capables d'insérer 41 GPU. « Ils ont testé une simulation de cette conception et ont découvert qu'elle accélérait à la fois le calcul et le mouvement des données tout en consommant moins d'énergie que 40 serveurs GPU standard auraient.
Tyson a écrit que « comme de nombreux lecteurs d'HEXUS le savent, généralement les superordinateurs répartissent les applications sur des centaines de GPU sur des PCB séparés, communiquer sur des liaisons longue distance. De telles liaisons sont lentes et peu énergivores par rapport aux interconnexions au sein de l'architecture de la puce. » Il a noté que Kumar parlait du transfert de données d'un GPU à un autre comme créant une quantité incroyable de frais généraux.
Spectre IEEE 's Moore a expliqué leur travail plus en détail.
"La plaquette SiIF est conçue avec une ou plusieurs couches d'interconnexions en cuivre de 2 micromètres de large espacées de 4 micromètres seulement. C'est comparable au niveau supérieur d'interconnexions sur une puce. Aux endroits où les GPU sont censés se brancher , la plaquette de silicium est modelée avec de courts piliers de cuivre espacés d'environ 5 micromètres. Le GPU est aligné au-dessus de ceux-ci, appuyé, et chauffé. Ce processus bien établi, appelé collage par compression thermique, provoque la fusion des piliers en cuivre avec les interconnexions en cuivre du GPU. "
Leur travail a suscité des commentaires favorables. Tyson a qualifié cela de décision courageuse mais peut-être opportune pour l'industrie.
Et après? L'équipe présentera ses conclusions au Symposium international de l'IEEE sur l'architecture informatique à hautes performances. L'événement aura lieu du 16 au 20 février à Washington DC.
© 2019 Réseau Science X