Crédit :IBM
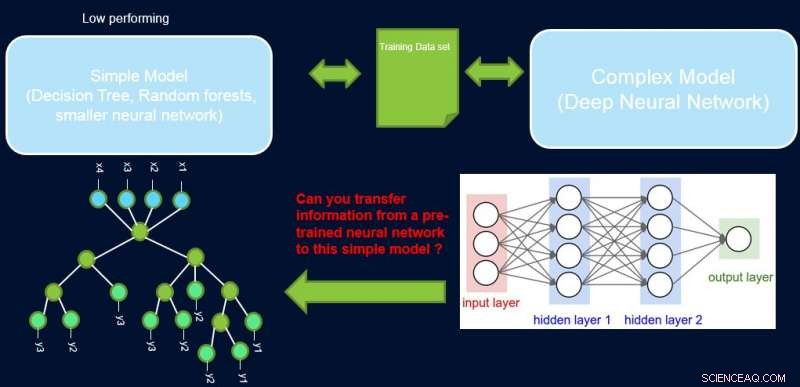
L'interprétabilité et les performances d'un système sont généralement en contradiction les unes avec les autres, car bon nombre des modèles les plus performants (à savoir les réseaux de neurones profonds) sont de nature boîte noire. Dans notre travail, Améliorer les modèles simples avec des profils de confiance, nous essayons de combler cette lacune en proposant une méthode pour transférer des informations d'un réseau de neurones performant vers un autre modèle que l'expert du domaine ou l'application peut exiger. Par exemple, en biologie computationnelle et en économie, les modèles linéaires clairsemés sont souvent préférés, tandis que dans des domaines instrumentés complexes tels que la fabrication de semi-conducteurs, les ingénieurs pourraient préférer utiliser des arbres de décision. Ces modèles interprétables plus simples peuvent renforcer la confiance avec l'expert et fournir des informations utiles menant à la découverte de faits nouveaux et auparavant inconnus. Notre objectif est illustré ci-dessous, pour un cas spécifique dans lequel nous essayons d'améliorer les performances d'un arbre de décision.
L'hypothèse est que notre réseau est un enseignant très performant, et nous pouvons utiliser certaines de ses informations pour enseigner le simple, interprétable, mais modèle étudiant généralement peu performant. La pondération des échantillons en fonction de leur difficulté peut aider le modèle simple à se concentrer sur des échantillons plus faciles qu'il peut modéliser avec succès lors de l'entraînement, et ainsi obtenir de meilleures performances globales. Notre configuration est différente du boost :dans cette approche, des exemples difficiles concernant un ancien apprenant « faible » sont mis en évidence pour une formation ultérieure afin de créer de la diversité. Ici, les exemples difficiles concernent un modèle complexe précis. Cela signifie que ces étiquettes sont presque aléatoires. De plus, si un modèle complexe ne peut pas les résoudre, il y a peu d'espoir pour le modèle simple de complexité fixe. D'où, il est important dans notre configuration de mettre en évidence des exemples faciles que le modèle simple peut résoudre.
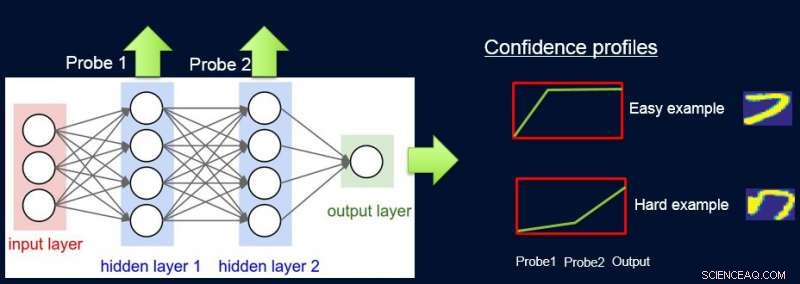
Pour faire ça, nous attribuons des poids aux échantillons en fonction de la difficulté du réseau à les classer, et nous le faisons en introduisant des sondes. Chaque sonde prend son entrée dans l'une des couches cachées. Chaque sonde a une seule couche entièrement connectée avec une couche softmax de la taille de la sortie réseau qui lui est attachée. La sonde de la couche i sert de classificateur qui n'utilise que le préfixe du réseau jusqu'à la couche i. L'hypothèse est que les instances faciles seront classées correctement avec une confiance élevée même avec des sondes de première couche, et donc nous obtenons des niveaux de confiance p
Nous pouvons maintenant utiliser les poids pour recycler le modèle simple sur l'ensemble de données pondéré final. Nous appelons ce pipeline de sondage, obtenir des poids de confiance, et le recyclage de ProfWeight.
Crédit :IBM
Nous présentons deux alternatives quant à la façon dont nous calculons les poids pour les exemples dans l'ensemble de données. Dans l'approche de la CUA mentionnée ci-dessus, nous notons l'erreur/précision de validation du modèle simple lorsqu'il est entraîné sur l'ensemble d'entraînement d'origine. Nous sélectionnons des sondes qui ont une précision d'au moins α (> 0) supérieur au modèle simple. Chaque exemple est pondéré en fonction du score de confiance moyen pour la véritable étiquette qui est calculé à l'aide des prédictions souples individuelles des sondes.
Une deuxième alternative implique l'optimisation à l'aide d'un réseau de neurones. Ici, nous apprenons les poids optimaux pour l'entraînement défini en optimisant l'objectif suivant :
S*=min
où w sont les poids à trouver pour chaque instance, β désigne l'espace des paramètres du modèle simple S, et est sa fonction de perte. Nous devons contraindre les poids, car sinon la solution triviale de tous les poids allant à zéro sera optimale pour l'objectif ci-dessus. Nous montrons dans l'article que notre contrainte de E[w]=1 a un lien avec la recherche de l'échantillonnage d'importance optimale.
Crédit :IBM
Plus généralement, ProfWeight peut être utilisé pour transférer vers des modèles encore plus simples mais opaques tels que des réseaux de neurones plus petits, ce qui peut être utile dans des domaines avec de fortes contraintes de mémoire et de puissance. De telles contraintes sont rencontrées lors du déploiement de modèles sur des appareils périphériques dans des systèmes IoT ou sur des appareils mobiles ou sur des véhicules aériens sans pilote.
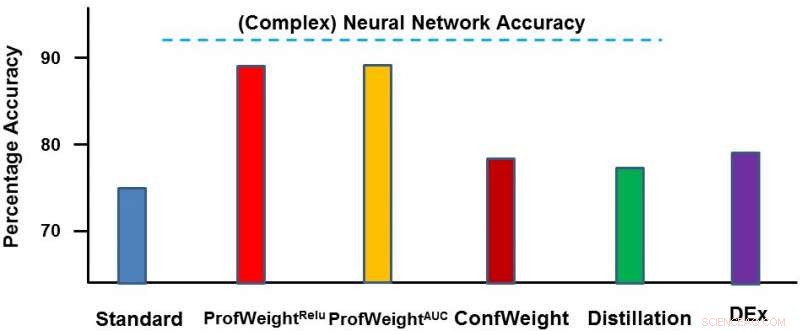
Nous avons testé notre méthode sur deux domaines :un jeu de données d'images publiques CIFAR-10 et un jeu de données de fabrication propriétaire. Sur le premier jeu de données, nos modèles simples étaient des réseaux de neurones plus petits qui se conformeraient à des contraintes strictes de mémoire et de puissance et où nous avons constaté une amélioration de 3 à 4 %. Sur le deuxième jeu de données, notre modèle simple était un arbre de décision et nous l'avons considérablement amélioré d'environ 13 %, qui a conduit à des résultats exploitables par l'ingénieur. Ci-dessous, nous décrivons ProfWeight en comparaison avec les autres méthodes sur cet ensemble de données. Nous observons ici que nous surpassons les autres méthodes de loin.
À l'avenir, nous aimerions trouver les conditions nécessaires/suffisantes lorsque le transfert par notre stratégie aboutirait à l'amélioration de modèles simples. Nous aimerions également développer des méthodes de transfert d'informations plus sophistiquées que ce que nous avons déjà accompli.
Nous présenterons ce travail dans un article intitulé "Améliorer des modèles simples avec des profils de confiance" à la Conférence 2018 sur les systèmes de traitement de l'information neuronale, mercredi, 5 décembre lors de la séance d'affiches en soirée de 17 h à 19 h dans les salles 210 et 230 AB (#90).
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.