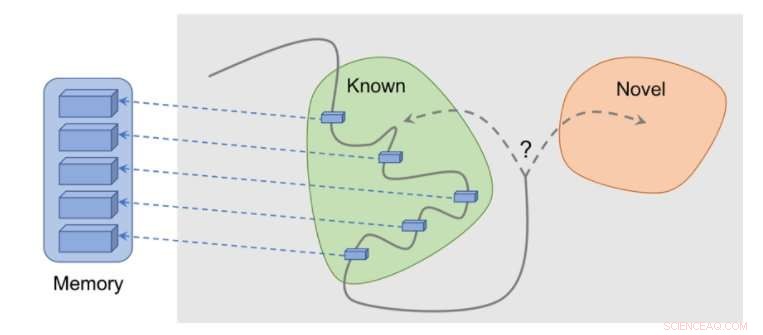
Fonctionnement de la méthode :les observations sont ajoutées à la mémoire, la récompense est calculée en fonction de la distance entre notre observation actuelle et l'observation la plus similaire en mémoire. L'agent reçoit plus de récompense pour avoir vu des observations qui ne sont pas encore représentées en mémoire. Crédit :Savinov et al.
Plusieurs tâches du monde réel ont des récompenses éparses et cela pose des défis pour le développement d'algorithmes d'apprentissage par renforcement (RL). Une solution à ce problème est de permettre à un agent de se créer de manière autonome une récompense, rendre les récompenses plus denses et plus adaptées à l'apprentissage.
Par exemple, inspiré par le comportement curieux avec lequel les animaux explorent leur environnement, l'observation d'un algorithme RL de quelque chose de nouveau pourrait être récompensée par un bonus. Cette prime, résumé par la vraie récompense de la tâche, permettrait alors aux algorithmes RL d'apprendre d'une récompense combinée.
Les chercheurs de DeepMind, Google Brain et l'ETH Zurich ont récemment mis au point une nouvelle méthode de curiosité qui utilise la mémoire épisodique pour former ce bonus de nouveauté. Ce bonus est déterminé en comparant les observations actuelles et les observations stockées en mémoire.
« L'objectif principal de notre travail était d'étudier de nouvelles façons, basées sur la mémoire, d'imprégner les agents d'apprentissage par renforcement (RL) de « curiosité, ' par lequel nous entendons une volonté d'explorer l'environnement même en l'absence totale de récompenses, " Tim Lillicrap de DeepMind et Nikolay Savinov de Google Brain ont déclaré à TechXplore dans un e-mail. " La curiosité a été abordée de diverses manières par la communauté des chercheurs, mais nous avons estimé que plusieurs idées pourraient bénéficier d'une exploration plus approfondie."
Les idées clés explorées dans cet article récent sont basées sur une étude précédente réalisée par Savinov, qui proposait une nouvelle architecture de mémoire inspirée de la navigation des mammifères. Cette architecture permet aux agents de répéter un itinéraire à travers un environnement en utilisant uniquement une procédure visuelle. La nouvelle méthode développée par les chercheurs va encore plus loin, essayer de réaliser une bonne exploration motivée par la curiosité.
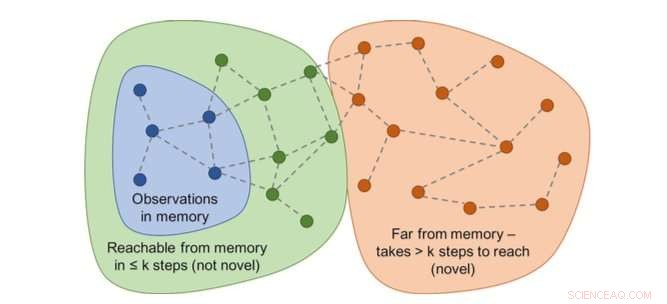
Le graphique des accessibilités déterminerait la nouveauté. En pratique, ce graphique n'est pas disponible - un approximateur de réseau de neurones est donc formé pour estimer un certain nombre d'étapes entre les observations. Crédit :Savinov et al.
"En agissant, l'agent stocke des instances de représentations d'observation dans sa mémoire épisodique, " Lillicrap et Savinov ont déclaré. "Pour déterminer si l'observation actuelle est nouvelle ou non, il est comparé à ceux en mémoire. Si rien de similaire n'est trouvé, l'observation en cours est réputée nouvelle et l'agent est récompensé, sinon, il obtient une récompense négative. Cela encourage l'agent à explorer un territoire inconnu, s'apparente à de la curiosité."
Les chercheurs ont découvert que comparer des paires d'observations pouvait être délicat, car la vérification d'une correspondance exacte n'a finalement aucun sens dans des environnements réalistes. C'est parce que dans des situations réelles, un agent observe rarement deux fois la même chose.
"Au lieu, nous avons entraîné un réseau de neurones pour prédire si l'agent peut atteindre l'observation actuelle à partir de celles en mémoire en effectuant moins d'actions qu'un seuil fixe ; dire, cinq actions, " Lillicrap et Savinov ont expliqué. " Les observations au sein de ces cinq actions sont considérées comme similaires, tandis que ceux qui nécessitent plus d'actions pour effectuer une transition sont considérés comme dissemblables."
Lillicrap, Savinov et leurs collègues ont testé leur approche dans VizDoom et DMLab, deux environnements 3D visuellement riches. Dans VizDoom, l'agent a appris à naviguer avec succès vers un objectif éloigné au moins deux fois plus rapidement que la méthode de curiosité de pointe ICM. Dans DMLab, l'algorithme s'est bien généralisé à nouveau, niveaux de jeu générés de manière procédurale, atteindre son objectif souhaité au moins deux fois plus fréquemment que l'ICM sur des labyrinthes de test avec des récompenses très rares.

La méthode basée sur la surprise (ICM) consiste à marquer les murs de manière persistante avec un gadget de science-fiction de type laser au lieu d'explorer le labyrinthe. Ce comportement est similaire au changement de canal décrit précédemment :même si le résultat du marquage est théoriquement prévisible, ce n'est pas facile et nécessite apparemment une connaissance approfondie de la physique qui n'est pas simple à acquérir pour un agent général. Crédit :Savinov et al.
"Nous avons remarqué un inconvénient intéressant dans l'une des méthodes les plus populaires pour imprégner les agents de curiosité, " Lillicrap et Savinov ont déclaré. "Nous avons constaté que cette méthode, sur la base de la surprise calculée par un modèle à évolution lente qui essaie de prédire ce qui va se passer ensuite, peut entraîner une réponse de gratification instantanée de la part de l'agent :au lieu de résoudre la tâche à accomplir, il exploitera des actions qui conduisent à des conséquences imprévisibles afin d'obtenir une récompense immédiate."
Cet événement particulier, également connus sous le nom de problèmes de « canapé-patate », implique qu'un agent trouve des moyens de se satisfaire instantanément en exploitant des actions qui conduisent à des conséquences imprévisibles. Par exemple, lorsqu'on lui donne une télécommande de télévision, l'agent peut ne rien faire d'autre que changer de canal, même si sa tâche initiale était entièrement différente, comme la recherche d'un but dans un labyrinthe.
"Cette lacune peut être atténuée en utilisant la mémoire épisodique avec une mesure raisonnable de similitude d'observation, qui est notre contribution, " Lillicrap et Savinov ont déclaré. "Cela ouvre la voie à une exploration plus intelligente."

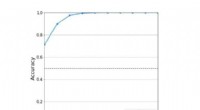
Notre méthode montre une exploration raisonnable. Crédit :Savinov et al.
La nouvelle méthode de curiosité imaginée par Lillicrap, Savinov, et leurs collègues pourraient aider à reproduire des compétences de type curiosité dans les algorithmes RL, leur permettant de créer de manière autonome des récompenses pour eux-mêmes. À l'avenir, les chercheurs aimeraient utiliser la mémoire épisodique non seulement pour accorder des récompenses, mais aussi pour planifier des actions.
"Par exemple, le contenu récupéré de la mémoire peut-il être utilisé pour réfléchir à la prochaine étape ?", ont déclaré Lillicrap et Savinov. "C'est actuellement un grand défi scientifique :s'il est résolu, les agents seraient capables d'adapter rapidement les stratégies d'exploration à de nouveaux environnements, permettant d'apprendre à un rythme beaucoup plus rapide."
© 2018 Tech Xplore