TbD-net résout le problème du raisonnement visuel en le décomposant en une chaîne de sous-tâches. La réponse à chaque sous-tâche est indiquée dans des cartes thermiques mettant en évidence les objets d'intérêt, permettant aux analystes de voir le processus de réflexion du réseau. Crédit : Groupe des technologies de l'intelligence et de la décision 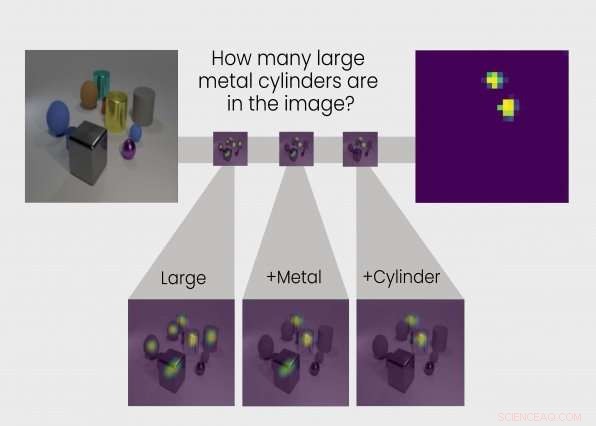
Nous apprenons par la raison à interpréter le monde. Donc, trop, faire des réseaux de neurones. Aujourd'hui, une équipe de chercheurs du groupe Intelligence and Decision Technologies Group du MIT Lincoln Laboratory a développé un réseau de neurones qui effectue des étapes de raisonnement de type humain pour répondre aux questions sur le contenu des images. Nommé Transparency by Design Network (TbD-net), le modèle rend visuellement son processus de réflexion au fur et à mesure qu'il résout des problèmes, permettant aux analystes humains d'interpréter son processus de prise de décision. Le modèle fonctionne mieux que les meilleurs réseaux de neurones à raisonnement visuel d'aujourd'hui.
Comprendre comment un réseau de neurones prend ses décisions est un défi de longue date pour les chercheurs en intelligence artificielle (IA). Comme le suggère la partie neuronale de leur nom, Les réseaux de neurones sont des systèmes d'IA inspirés par le cerveau destinés à reproduire la façon dont les humains apprennent. Ils sont constitués de couches d'entrée et de sortie, et des couches intermédiaires qui transforment l'entrée en sortie correcte. Certains réseaux de neurones profonds sont devenus si complexes qu'il est pratiquement impossible de suivre ce processus de transformation. C'est pourquoi ils sont appelés systèmes de « boîte noire », avec leurs événements exacts à l'intérieur, même opaques pour les ingénieurs qui les construisent.
Avec TbD-net, les développeurs visent à rendre ces rouages internes transparents. La transparence est importante car elle permet aux humains d'interpréter les résultats d'une IA.
Il est important de savoir, par exemple, qu'est-ce qu'un réseau de neurones utilisé dans les voitures autonomes pense exactement comme la différence entre un piéton et un panneau d'arrêt, et à quel point le long de sa chaîne de raisonnement voit-il cette différence. Ces informations permettent aux chercheurs d'apprendre au réseau de neurones à corriger toute hypothèse incorrecte. Mais les développeurs de TbD-net disent que les meilleurs réseaux de neurones manquent aujourd'hui d'un mécanisme efficace pour permettre aux humains de comprendre leur processus de raisonnement.
"Les progrès dans l'amélioration des performances du raisonnement visuel se sont fait au détriment de l'interprétabilité, " dit Ryan Soklaski, qui a construit TbD-net avec ses collègues chercheurs Arjun Majumdar, David Mascharka, et Philippe Tran.
Le groupe Lincoln Laboratory a réussi à combler l'écart entre la performance et l'interprétabilité avec TbD-net. L'une des clés de leur système est une collection de « modules, " de petits réseaux de neurones spécialisés pour effectuer des sous-tâches spécifiques. Lorsqu'on pose à TbD-net une question de raisonnement visuel sur une image, il décompose la question en sous-tâches et attribue le module approprié pour remplir sa part. Comme des ouvriers sur une chaîne de montage, chaque module s'appuie sur ce que le module avant d'avoir compris pour finalement produire le final, bonne réponse. Dans son ensemble, TbD-net utilise une technique d'IA qui interprète les questions du langage humain et divise ces phrases en sous-tâches, suivi de plusieurs techniques d'IA de vision par ordinateur qui interprètent l'imagerie.
Majumdar dit :« Briser une chaîne complexe de raisonnements en une série de sous-problèmes plus petits, dont chacun peut être résolu indépendamment et composé, est un moyen puissant et intuitif de raisonnement."
La sortie de chaque module est représentée visuellement dans ce que le groupe appelle un "masque d'attention". Le masque d'attention affiche des gouttes de carte thermique sur les objets de l'image que le module identifie comme sa réponse. Ces visualisations permettent à l'analyste humain de voir comment un module interprète l'image.
Prendre, par exemple, la question suivante posée à TbD-net :« Dans cette image, de quelle couleur est le grand cube de métal ?" Pour répondre à la question, le premier module ne localise que les gros objets, produire un masque d'attention avec ces gros objets mis en évidence. Le module suivant prend cette sortie et trouve lesquels de ces objets identifiés comme grands par le module précédent sont également en métal. La sortie de ce module est envoyée au module suivant, qui identifie lequel de ces grands, objets métalliques est aussi un cube. Enfin, cette sortie est envoyée à un module qui peut déterminer la couleur des objets. La sortie finale de TbD-net est "rouge, " la bonne réponse à la question.
Une fois testé, TbD-net a obtenu des résultats qui surpassent les modèles de raisonnement visuel les plus performants. Les chercheurs ont évalué le modèle à l'aide d'un ensemble de données visuelles de questions-réponses composé de 70, 000 images d'entraînement et 700, 000 questions, ainsi que des ensembles de test et de validation de 15, 000 images et 150, 000 questions. Le modèle initial a atteint une précision de test de 98,7 % sur l'ensemble de données, lequel, selon les chercheurs, surpasse de loin les autres approches basées sur le réseau de modules neuronaux.
Surtout, les chercheurs ont ensuite pu améliorer ces résultats grâce à l'avantage clé de leur modèle :la transparence. En regardant les masques d'attention produits par les modules, ils pouvaient voir où les choses n'allaient pas et affiner le modèle. Le résultat final a été une performance de pointe d'une précision de 99,1 %.
"Notre modèle fournit des des sorties interprétables à chaque étape du processus de raisonnement visuel, " dit Mascharka.
L'interprétabilité est particulièrement précieuse si des algorithmes d'apprentissage en profondeur doivent être déployés aux côtés des humains pour aider à s'attaquer à des tâches complexes du monde réel. Pour établir la confiance dans ces systèmes, les utilisateurs devront avoir la possibilité d'inspecter le processus de raisonnement afin de comprendre pourquoi et comment un modèle peut faire des prédictions erronées.
Paul Metzger, leader du Groupe Intelligence et Technologies de la Décision, déclare que la recherche "fait partie du travail du Lincoln Laboratory pour devenir un leader mondial de la recherche appliquée en apprentissage automatique et de l'intelligence artificielle qui favorise la collaboration homme-machine".
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.