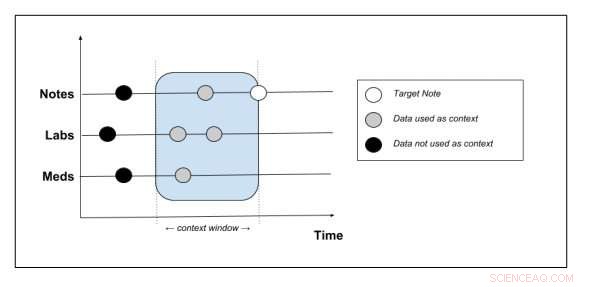
Schéma montrant quelles données contextuelles sont extraites du dossier patient. Crédit :Peter Liu
Les médecins passent actuellement beaucoup de temps à rédiger des notes sur les patients et à les insérer dans les systèmes de dossiers de santé électroniques (DSE). Selon une étude de 2016, les médecins consacrent environ deux heures au travail administratif pour chaque heure passée avec un patient. Grâce à des outils d'intelligence artificielle de pointe, ce processus de rédaction de notes pourrait bientôt devenir automatisé, aider les médecins à mieux gérer leurs quarts de travail et les soulager de cette tâche fastidieuse.
Peter Liu, un chercheur chez Google Brain, a récemment développé une nouvelle tâche de modélisation linguistique qui peut prédire le contenu de nouvelles notes en analysant les dossiers médicaux des patients, qui incluent des données telles que la démographie, mesures en laboratoire, médicaments et notes antérieures. Dans son étude, prépublié sur arXiv, il a formé des modèles génératifs à l'aide de l'ensemble de données EHR MIMIC-III (Medical Information Mart for Intensive Care), puis comparé les notes générées par les modèles avec de vraies notes de l'ensemble de données.
Les méthodes couramment adoptées pour réduire le temps que les cliniciens consacrent à la prise de notes comprennent l'utilisation de services de dictée et l'emploi d'assistants qui peuvent rédiger des notes pour eux. Des outils d'intelligence artificielle pourraient aider à résoudre ce problème, réduire les dépenses consacrées au personnel et aux ressources supplémentaires.
« Fonctionnalités d'aide à l'écriture pour les notes, comme la saisie semi-automatique ou la vérification d'erreurs, bénéficier de modèles de langage, " Liu écrit dans son journal. " Plus le modèle est fort, plus ces caractéristiques seraient probablement efficaces. Ainsi, L'objectif de cet article est de créer des modèles de langage pour les notes cliniques. »
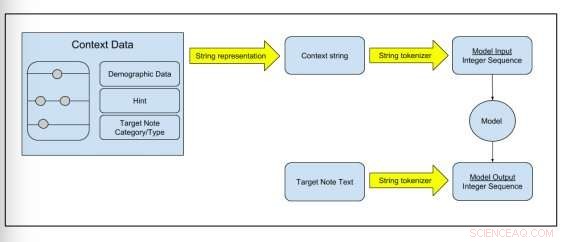
Figure 2 : Schéma montrant comment les données brutes sont transformées en données d'entraînement du modèle. Crédit :Peter Liu
Liu a utilisé deux modèles de langage :le premier est appelé architecture de transformateur, et a été introduit dans une étude publiée l'année dernière dans le Avancées dans les systèmes de traitement de l'information neuronale journal. Comme ce modèle fonctionne mieux avec des textes plus courts, telles que des phrases individuelles, il a également testé un modèle à base de transformateur récemment introduit, appelé transformateur à mémoire compressée attention (T-DMCA), qui s'est avéré plus efficace pour des séquences plus longues.
Il a entraîné ces modèles sur le jeu de données MIMIC-III, contenant un DSE anonymisé de 39, 597 patients de l'unité de soins intensifs d'un hôpital de soins tertiaires. Il s'agit actuellement de l'ensemble de données DSE le plus complet accessible au public et facilement accessible en ligne.
« Nous avons introduit une nouvelle tâche de modélisation du langage pour les notes cliniques basées sur les données HER et avons montré comment représenter le contexte des données multimodales dans le modèle, " Liu a expliqué dans son article. " Nous avons proposé des métriques d'évaluation pour la tâche et présenté des résultats encourageants montrant le pouvoir prédictif de tels modèles. "
Les modèles étaient effectivement capables de prédire une grande partie du contenu des notes des médecins. Dans le futur, ils pourraient aider au développement de fonctions de vérification orthographique et de saisie semi-automatique plus sophistiquées. Ces fonctionnalités pourraient ensuite être intégrées dans des outils qui aident les cliniciens à effectuer le travail administratif. Bien que les résultats de cette étude soient prometteurs, certains défis doivent encore être surmontés avant que les modèles puissent être utilisés à plus grande échelle.
"Dans de nombreux cas, le contexte maximal fourni par le DSE est insuffisant pour prédire pleinement la note, " Liu explique dans son article. " Le cas le plus évident est le manque de données d'imagerie dans MIMIC-III pour les rapports de radiologie. Pour les notes sans imagerie, nous manquons également d'informations sur les dernières interactions patient-prestataire. Les travaux futurs pourraient tenter d'augmenter le contexte de la note avec des données au-delà du DSE, par exemple. données d'imagerie, ou des transcriptions d'interactions patient-médecin. Bien que nous ayons discuté de la correction des erreurs et des fonctionnalités de saisie semi-automatique dans le logiciel de DSE, leurs effets sur la productivité des utilisateurs n'ont pas été mesurés dans le contexte clinique, que nous laissons comme travail futur."
© 2018 Tech Xplore