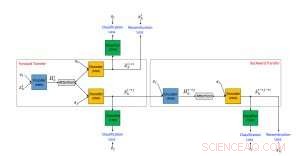
Cadre proposé d'un algorithme de transfert de style de texte neuronal utilisant des données non parallèles. Crédit :IBM
Les médias sociaux en ligne sont devenus l'un des moyens les plus importants de communiquer et d'échanger des idées. Malheureusement, le discours est souvent paralysé par un langage abusif qui peut avoir des effets néfastes sur les utilisateurs des médias sociaux. Par exemple, un récent sondage de YouGov.uk a découvert que, parmi les informations que les employeurs peuvent trouver en ligne sur les candidats, le langage agressif ou offensant est l'activité de médias sociaux la plus dommageable sur le plan professionnel. Les réseaux de médias sociaux en ligne traitent normalement le problème du langage offensant en filtrant simplement un message lorsqu'il est signalé comme offensant.
Dans l'article "Combattre le langage offensant sur les médias sociaux avec un transfert de style de texte non supervisé, " qui a été présenté lors de la 56e réunion annuelle de l'Association for Computational Linguistics (ACL 2018), nous introduisons une approche complètement nouvelle pour résoudre ce problème. Notre approche utilise un transfert de style de texte non supervisé pour traduire les phrases offensantes en formes correspondantes non offensantes. Au meilleur de notre connaissance, tous les travaux antérieurs abordant le problème du langage offensant sur les médias sociaux se sont concentrés uniquement sur la classification des textes. Ces méthodes peuvent ainsi être utilisées principalement pour signaler et filtrer le contenu offensant, mais notre approche proposée va un pas en avant et produit une version alternative non offensante du contenu. Cela présente deux avantages potentiels pour les utilisateurs de médias sociaux. Pour les utilisateurs qui envisagent de publier un message offensant, recevoir une alerte que le contenu est offensant et sera bloqué, ainsi qu'une version plus polie du message qui peut être publiée, pourrait les encourager à changer d'avis et à éviter le blasphème. En outre, pour les utilisateurs consommant du contenu en ligne, cela leur permet de toujours voir et comprendre le message, mais sur un ton non offensant et poli.
Une architecture pour remplacer le langage offensant
Notre méthode est basée sur l'architecture de réseau de neurones encodeur-décodeur désormais populaire, qui est l'approche de pointe pour la traduction automatique. En traduction automatique, la formation du réseau de neurones encodeur-décodeur suppose l'existence d'une "Pierre de Rosette" où le même texte est écrit à la fois dans les langues source et cible. Ces données appariées permettent aux développeurs de déterminer facilement si un système se traduit correctement et donc d'entraîner un système encodeur-décodeur à bien fonctionner. Malheureusement, contrairement à la traduction automatique, pour autant que nous sachions, il n'existe aucun ensemble de données appariées disponibles pour le cas des peines offensantes à non offensantes. De plus, le texte transféré doit utiliser un vocabulaire commun à un domaine d'application particulier. Par conséquent, des méthodes non supervisées qui n'utilisent pas de données appariées sont nécessaires pour effectuer cette tâche.

Nous avons proposé une approche de transfert de style de texte non supervisé composée de trois composants principaux, chacun s'est vu confier une tâche distincte pendant la formation. L'un (un encodeur RNN) analyse une phrase offensante et compresse les informations les plus pertinentes dans un vecteur de valeur réelle. Celui-ci est lu par un autre composant (un décodeur RNN), qui génère une nouvelle phrase qui est la version traduite de l'originale. La phrase traduite est ensuite évaluée par le troisième composant (un classificateur CNN) pour identifier si la sortie a été correctement traduite du style offensant en un style non offensant. En outre, la phrase générée est également « rétrotraduite » de non offensante à offensante et comparée à la phrase originale pour vérifier si le contenu a été préservé. Si les résultats de l'une des évaluations ci-dessus contiennent des erreurs, le système est ajusté en conséquence. L'encodeur et le décodeur sont également, en parallèle, entraînés à l'aide d'un dispositif d'auto-encodage dont l'objectif consiste à reconstruire la phrase d'entrée. Nous utilisons également le mécanisme d'attention qui aide à assurer la préservation du contenu. Notre principal apport en termes d'architecture est l'utilisation combinée d'un classifieur collaboratif, attention, et rétro-transfert.
Traduire un langage offensant
Nous avons testé notre méthode proposée en utilisant les données de deux réseaux sociaux populaires :Twitter et Reddit. Nous avons créé des ensembles de données de textes offensants et non offensants en classant environ 10 millions de messages à l'aide d'un classificateur de langage offensant proposé par Davidson et al. (2017). Le tableau suivant montre des exemples de phrases originales offensantes et les traductions non offensantes générées par une méthode de transfert de style de texte proposée par Shen et al. (2017) et par notre approche. Notre système a démontré de meilleures performances pour traduire les phrases offensantes en phrases non offensantes tout en préservant le contenu global, mais produit parfois des phrases étranges.
Ce travail est un premier pas vers une nouvelle approche prometteuse pour lutter contre les publications abusives sur les réseaux sociaux. Le transfert de style de texte non supervisé est un domaine de recherche qui vient de commencer à voir des résultats prometteurs. Notre travail est une bonne preuve de concept que les méthodes actuelles de transfert de style de texte non supervisé peuvent être appliquées à des tâches utiles. Cependant, il est important de noter que les approches actuelles de transfert de style de texte non supervisé ne peuvent bien gérer que les cas où le problème de langage offensant est lexical (comme les exemples présentés dans le tableau) et peut être résolu en modifiant ou en supprimant quelques mots. Les modèles que nous avons utilisés ne seront pas efficaces dans les cas de biais implicite où des mots normalement inoffensifs sont utilisés de manière offensante.
Nous pensons que des versions améliorées de la méthode proposée, avec l'utilisation de volumes beaucoup plus importants de données d'entraînement, sera capable de faire face à d'autres messages abusifs tels que les messages contenant des propos haineux, racisme, et le sexisme. Nous imaginons que notre méthode pourrait être utilisée pour améliorer l'IA conversationnelle, en veillant à ce que les chatbots qui apprennent en interagissant avec les utilisateurs en ligne ne reproduisent pas plus tard un langage offensant et des discours haineux. Le contrôle parental est une autre utilisation potentielle du système proposé.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research.