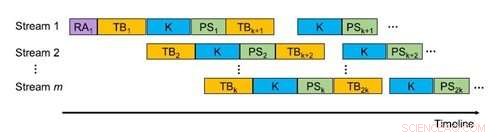
Fig 1. Plusieurs flux GPU asynchrones de GMiner. Crédit :Daegu Gyeongbuk Institute of Science and Technology (DGIST)
Une équipe de recherche de l'Institut coréen des sciences et technologies Daegu Gyeongbuk (DGIST) a réussi à analyser les mégadonnées jusqu'à 1, 000 fois plus rapide que la technologie existante en utilisant la technologie « GMiner » basée sur le GPU. Les résultats de l'analyse des modèles de données volumineuses devraient être utilisés dans diverses industries, notamment les secteurs de la finance et de l'informatique.
Une équipe internationale de chercheurs, dirigé par le professeur Min-Soo Kim du Département d'ingénierie de l'information et de la communication, a développé la technologie « GMiner » qui peut analyser les modèles de données volumineuses à grande vitesse. La technologie GMiner présente des performances jusqu'à 1, 000 fois plus rapide que la meilleure technologie d'extraction de motifs au monde.
La technologie d'exploration de modèles identifie tous les modèles importants qui apparaissent à plusieurs reprises dans les mégadonnées de divers domaines tels que l'achat de marchandises dans les méga-marchés, opérations bancaires, paquets réseau, et réseaux sociaux. Cette technologie est largement utilisée dans diverses industries à des fins telles que la détermination de l'emplacement des produits sur les étagères des méga-marchés ou la recommandation de cartes de crédit qui correspondent aux habitudes d'utilisation des consommateurs d'âges différents.
L'importance croissante de l'exploration de modèles a conduit au développement de milliers de technologies d'exploration de modèles au cours des 20 dernières années; cependant, en raison de la longueur croissante des modèles de données volumineuses, qui a augmenté le nombre de modèles analytiques de façon exponentielle, les technologies minières existantes ont été entravées dans leur analyse de données de plus de dix gigaoctets (Go) car elles n'ont pas réussi à terminer leur analyse en raison d'une mémoire informatique insuffisante ou ont pris trop de temps.
Les technologies traditionnelles d'exploration de motifs ont d'abord trouvé des motifs de longueur moyenne et les ont stockés en mémoire. Lorsque vous recherchez un motif plus long que mi-long, ils ont utilisé une méthode pour trouver des motifs finaux par rapport à un motif de longueur moyenne qui avait été précédemment enregistré.
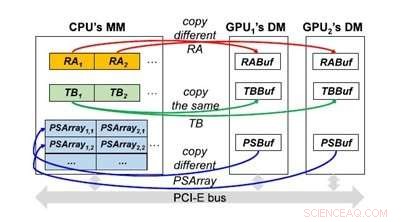
Fig 2. Flux de données de GMiner utilisant plusieurs GPU. Crédit :Daegu Gyeongbuk Institute of Science and Technology (DGIST)
Cependant, La technologie GMiner développée par l'équipe de recherche a réussi à résoudre fondamentalement le problème des technologies existantes en proposant des techniques anti-intuitives qui combinent les motifs de longueur moyenne calculés temporairement en utilisant les milliers de cœurs sur les unités de traitement graphique (GPU) pour calculer la longueur ultime de motifs.
La technologie GMiner a complètement résolu le problème chronique de l'insuffisance de mémoire subie par les technologies conventionnelles en ne stockant pas un nombre exponentiel de motifs de longueur moyenne en mémoire. En outre, il a résolu le problème de vitesse lente en diffusant les données de la mémoire principale vers le GPU tout en recherchant simultanément des modèles en utilisant les performances de calcul élevées du GPU.
La technologie GMiner a montré des performances d'analyse d'au moins 10 fois à un maximum de 1, 000 fois plus rapide que les technologies distribuées et parallèles conventionnelles qui analysaient les données en utilisant jusqu'à des dizaines d'ordinateurs domestiques généraux dotés d'un seul GPU par ordinateur ; Donc, il peut analyser les mégadonnées à plus grande échelle que les technologies existantes. Il a également montré d'excellentes performances d'extension qui améliorent les performances proportionnellement au nombre de GPU.
Le professeur Kim a dit :"Nous avons sécurisé des technologies fondamentales capables d'analyser les modèles de Big Data à grande vitesse sans aucun problème de mémoire pour les Big Data accumulées dans une variété d'industries. En résolvant les problèmes où les technologies d'exploration de modèles n'étaient pas correctement appliquées aux Big Data en raison d'un manque de mémoire et vitesse lente, cette nouvelle technologie peut être utilisée pour aider les entreprises à prendre des décisions efficaces en analysant les modèles de données volumineuses dans divers secteurs, notamment la finance, vendre au détail, CE, et les secteurs bio-connexes.
Ce résultat de recherche a été publié dans le numéro du 9 mai de Information Sciences, la revue internationale la plus reconnue dans le domaine des sciences de l'information.














