Crédit :arXiv:1905.09773 [cs.CV]
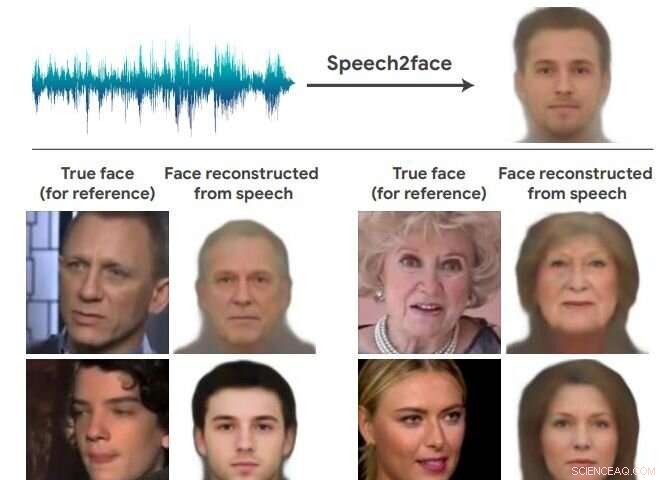
Encore une fois, les équipes d'intelligence artificielle taquinent le royaume de l'impossible et livrent des résultats surprenants. Cette équipe dans les nouvelles a compris à quoi le visage d'une personne peut ressembler simplement en se basant sur la voix. Bienvenue sur Speech2Face. L'équipe de recherche a trouvé un moyen de reconstituer la ressemblance très approximative de certaines personnes à partir de courts clips audio.
L'article décrivant leur travail est sur arXiv, et s'intitule "Speech2Face :Apprendre le visage derrière une voix". Les auteurs sont Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosséri, William Freemany, Michael Rubinstein et Wojciech Matusiky. "Notre objectif dans ce travail est d'étudier dans quelle mesure nous pouvons déduire à quoi ressemble une personne à partir de la façon dont elle parle."
Ils évaluent et quantifient numériquement comment, et de quelle manière, leurs reconstructions Speech2Face à partir de l'audio ressemblent aux images du vrai visage des haut-parleurs.
Les auteurs voulaient apparemment s'assurer que leur intention était claire, pas comme une tentative de lier des voix avec des images de personnes spécifiques qui ont réellement parlé, car « notre objectif n'est pas de prédire une image reconnaissable du visage exact, mais plutôt pour capturer les traits du visage dominants de la personne qui sont corrélés avec le discours d'entrée. »
Les auteurs de GitHub ont déclaré qu'ils pensaient également qu'il était important de discuter dans le document des considérations éthiques "en raison de la sensibilité potentielle des informations faciales".
Ils ont déclaré dans leur article que leur méthode "ne peut pas récupérer la véritable identité d'une personne à partir de sa voix (c'est-à-dire, une image exacte de leur visage). C'est parce que notre modèle est formé pour capturer des caractéristiques visuelles (liées à l'âge, genre, etc.) qui sont communs à de nombreux individus, et uniquement dans les cas où il existe des preuves suffisamment solides pour relier ces caractéristiques visuelles aux attributs vocaux/de parole dans les données. »
Ils ont également déclaré que le modèle produira des visages d'apparence moyenne - uniquement des visages d'apparence moyenne - avec des caractéristiques visuelles caractéristiques en corrélation avec le discours d'entrée.
Jackie Neige, Entreprise rapide , écrit sur leur méthode. Snow a déclaré que l'ensemble de données qu'ils avaient pris était composé de clips de YouTube. Speech2Face a été formé par des scientifiques sur des vidéos d'Internet montrant des personnes en train de parler. Ils ont créé un modèle basé sur un réseau de neurones qui "apprend les attributs vocaux associés aux traits du visage à partir des vidéos".
Neige ajoutée, "Maintenant, lorsque le système entend une nouvelle séquence sonore, l'IA peut utiliser ce qu'elle a appris pour deviner à quoi pourrait ressembler le visage."
Neuroruche ont discuté de leur travail :« D'après les vidéos, ils extraient des paires parole-visage, qui alimentent deux branches de l'architecture. Les images sont codées dans un vecteur latent à l'aide du modèle de reconnaissance faciale pré-entraîné, tandis que la forme d'onde est introduite dans un codeur vocal sous la forme d'un spectrogramme, afin d'utiliser la puissance des architectures convolutives. Le vecteur codé de l'encodeur vocal est introduit dans le décodeur de visage pour obtenir la reconstruction finale du visage."
On peut aussi avoir un rapport précis sur leur méthode et comment ils ont testé avec un article sur Paquet :
"Ils ont dit qu'ils ont évalué et quantifié numériquement comment leur Speech2Face reconstruit, obtient des résultats directement à partir de l'audio, et comment cela ressemble aux images du vrai visage des haut-parleurs. Pour ça, ils ont testé leur modèle à la fois qualitativement et quantitativement sur l'ensemble de données AVSpeech et l'ensemble de données VoxCeleb."
Comment leurs découvertes pourraient-elles aider les applications du monde réel ? Ils ont dit, « nous pensons que la prédiction d'images de visage directement à partir de la voix peut prendre en charge des applications utiles, comme joindre un représentant aux appels téléphoniques/vidéo en fonction de la voix de l'orateur."
Pourquoi leur travail est important :pensez à des modèles. "Des recherches antérieures ont exploré des méthodes pour prédire l'âge et le sexe à partir de la parole, " dit Neige, "mais dans ce cas, les chercheurs affirment qu'ils ont également détecté des corrélations avec certains motifs faciaux."
© 2019 Réseau Science X