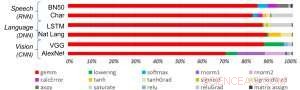
Figure 1. Les algorithmes d'apprentissage en profondeur sont composés d'un éventail d'opérations. Bien que la multiplication matricielle soit dominante, optimiser l'efficacité des performances tout en maintenant la précision nécessite que l'architecture de base prenne en charge efficacement toutes les fonctions auxiliaires. Crédit :IBM
Les progrès récents de l'apprentissage en profondeur et la croissance exponentielle de l'utilisation de l'apprentissage automatique dans les domaines d'application ont rendu l'accélération de l'IA extrêmement importante. IBM Research a construit un pipeline d'accélérateurs matériels d'IA pour répondre à ce besoin. Au Symposium Circuits VLSI 2018, nous avons présenté un bloc de construction d'accélérateur multi-TeraOPS qui peut être mis à l'échelle sur une large gamme de systèmes matériels d'IA. Ce noyau d'IA numérique présente une architecture parallèle qui garantit une utilisation très élevée et des moteurs de calcul efficaces qui exploitent soigneusement une précision réduite.
L'informatique approximative est un principe central de notre approche pour exploiter "la physique de l'IA", dans laquelle des gains de calcul à haute efficacité énergétique sont réalisés par des architectures dédiées, utilisant initialement des calculs numériques et plus tard, y compris l'informatique analogique et en mémoire.
Historiquement, le calcul s'est appuyé sur une arithmétique à virgule flottante 64 et 32 bits de haute précision. Cette approche fournit des calculs précis à la nième décimale, un niveau de précision critique pour les tâches de calcul scientifique comme la simulation du cœur humain ou le calcul des trajectoires des navettes spatiales. Mais avons-nous besoin de ce niveau de précision pour les tâches courantes d'apprentissage en profondeur ? Notre cerveau a-t-il besoin d'une image haute résolution pour reconnaître un membre de la famille, ou un chat ? Lorsque nous entrons dans un fil de texte pour la recherche, avons-nous besoin de précision dans le classement relatif des 50, 002e réponse la plus utile vs le 50, 003 ? La réponse est que de nombreuses tâches, y compris ces exemples, peuvent être accomplies avec un calcul approximatif.
Étant donné que la précision totale est rarement requise pour les charges de travail courantes d'apprentissage en profondeur, la précision réduite est une direction naturelle. Les blocs de construction informatiques avec des moteurs de précision de 16 bits sont 4 fois plus petits que des blocs comparables avec une précision de 32 bits; ce gain d'efficacité de zone devient une augmentation des performances et de l'efficacité énergétique pour les charges de travail de formation et d'inférence de l'IA. Simplement déclaré, en calcul approximatif, nous pouvons échanger la précision numérique contre l'efficacité de calcul, à condition que nous développions également des améliorations algorithmiques pour conserver la précision du modèle. Cette approche complète également d'autres techniques de calcul approximatives, y compris des travaux récents qui décrivent de nouvelles approches de compression d'entraînement pour réduire les frais généraux de communication, conduisant à une accélération de 40 à 200x par rapport aux méthodes existantes.
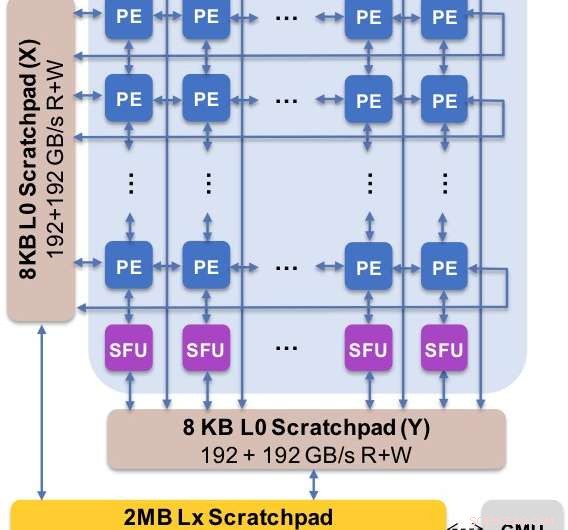
Figure 2. L'architecture principale capture le flux de données personnalisé avec la hiérarchie du bloc-notes. L'élément de traitement (PE) exploite une précision réduite pour les opérations de multiplication matricielle et certaines fonctions d'activation, tandis que les unités de fonction spéciale (SFU) conservent une précision à virgule flottante de 32 bits pour les opérations vectorielles restantes. Crédit :IBM
Nous avons présenté les résultats expérimentaux de notre noyau d'IA numérique au Symposium 2018 sur les circuits VLSI. La conception de notre nouveau noyau a été régie par quatre objectifs :
Notre nouvelle architecture a été optimisée non seulement pour la multiplication matricielle et les noyaux convolutifs, qui ont tendance à dominer les calculs d'apprentissage en profondeur, mais aussi un éventail de fonctions d'activation qui font partie de la charge de travail de calcul de l'apprentissage en profondeur. Par ailleurs, notre architecture prend en charge les opérations convolutives natives, permettant aux tâches d'apprentissage en profondeur et d'inférence sur les images et les données vocales de s'exécuter avec une efficacité exceptionnelle sur le cœur.
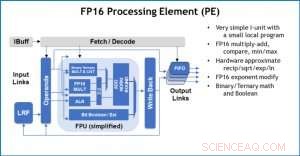
Figure 3. Élément de traitement (PE) avec des capacités de virgule flottante 16 bits (FP16) pour les opérations de multiplication matricielle, mathématiques binaires et ternaires, fonctions d'activation et opérations booléennes. Crédit :IBM
Pour illustrer comment l'architecture de base a été optimisée pour une variété de fonctions d'apprentissage en profondeur, La figure 1 montre la répartition des types d'opérations au sein des algorithmes d'apprentissage en profondeur dans un éventail de domaines d'application. Les composants de multiplication matriciels dominants sont calculés dans l'architecture de base en utilisant une organisation de flux de données personnalisée des éléments de traitement illustrés dans les figures 2 et 3, où des calculs de précision réduite peuvent être exploités efficacement, tandis que les fonctions vectorielles restantes (toutes les barres non rouges de la figure 1) sont exécutées soit dans les éléments de traitement, soit dans les unités de fonction spéciales illustrées dans les figures 3 ou 4, en fonction des besoins de précision de la fonction spécifique.
Au Symposium, nous avons montré des résultats matériels confirmant que cette approche d'architecture unique est capable à la fois d'apprentissage et d'inférence et prend en charge des modèles dans plusieurs domaines (par exemple, discours, vision, traitement du langage naturel). Alors que d'autres groupes soulignent les "performances de pointe" de leurs puces d'IA spécialisées, mais ont des niveaux de performance soutenus à une petite fraction du pic, nous nous sommes concentrés sur la maximisation des performances et de l'utilisation durables, puisque des performances soutenues se traduisent directement par une expérience utilisateur et des temps de réponse.
Notre puce de test est illustrée à la figure 5. À l'aide de cette puce de test, construit en technologie 14LPP, nous avons réussi à démontrer à la fois la formation et l'inférence, à travers une vaste bibliothèque d'apprentissage en profondeur, exercer toutes les opérations couramment utilisées dans les tâches de deep learning, y compris les multiplications matricielles, convolutions et diverses fonctions d'activation non linéaires.
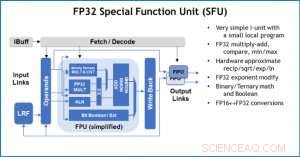
Figure 4. Unité de fonction spéciale (SFU) avec virgule flottante 32 bits (FP32) pour certains calculs vectoriels. Crédit :IBM
Nous avons souligné la flexibilité et la capacité polyvalente du noyau d'IA numérique et la prise en charge native de plusieurs flux de données dans le document VLSI, mais cette approche est entièrement modulaire. Ce cœur d'IA peut être intégré dans des SoC, processeurs, ou des microcontrôleurs et utilisés pour la formation, inférence, ou les deux. Les puces utilisant le cœur peuvent être déployées dans le centre de données ou à la périphérie.
Poussé par une compréhension fondamentale des algorithmes d'apprentissage en profondeur chez IBM Research, nous nous attendons à ce que les exigences de précision pour la formation et l'inférence continuent à évoluer, ce qui entraînera des améliorations de l'efficacité quantique dans les architectures matérielles nécessaires à l'IA. Restez à l'écoute pour plus de recherches de notre équipe.
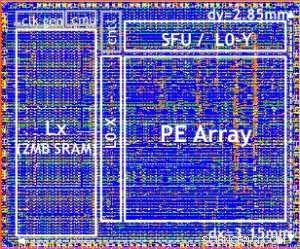
Figure 5. Digital AI Core testchip, based on 14LPP technology, including 5.75M gates, 1.00 flip-flops, 16KB L0 and 16KB of PE local registers. This chip was used to demonstrate both training and inferencing, across a wide range of AI workloads. Crédit :IBM