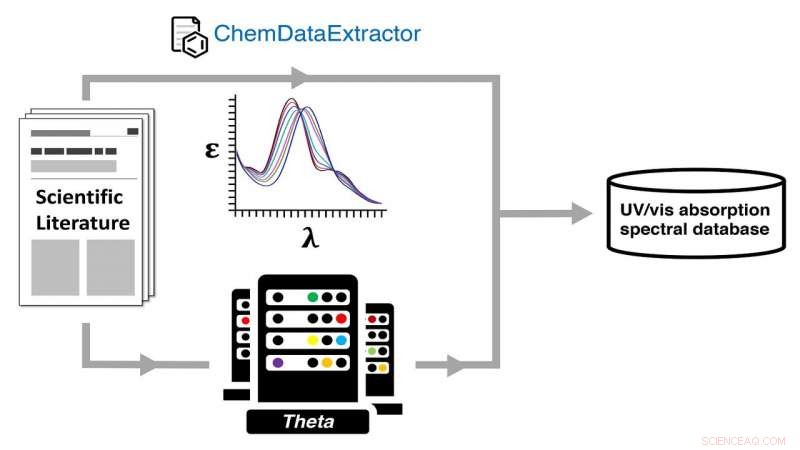
Génération automatique d'une base de données spectrale d'absorption ultraviolet-visible (UV-vis) via une double voie de données chimiques expérimentales et informatiques à l'aide du supercalculateur Theta de l'ALCF. Crédit :Jacqueline Cole et Ulrich Mayer / Université de Cambridge
Une collaboration entre l'Université de Cambridge et Argonne a développé une technique qui génère des bases de données automatiques pour prendre en charge des domaines scientifiques spécifiques à l'aide de l'IA et du calcul haute performance.
Chercher dans des tonnes de littérature scientifique des bits et des octets d'informations pour soutenir une idée ou trouver la clé pour résoudre un problème spécifique a longtemps été une affaire fastidieuse pour les chercheurs, même après l'aube de la découverte basée sur les données.
Jacqueline Cole connaît l'exercice, trop bien. Responsable de l'ingénierie moléculaire à l'Université de Cambridge, Royaume-Uni, elle a passé une grande partie de sa carrière à rechercher des matériaux aux propriétés optiques qui se prêtent à une collecte de lumière plus efficace, comme des molécules de colorant qui pourraient un jour alimenter les fenêtres solaires.
"Je savais qu'une grande partie de l'information était détenue sous une forme très fragmentée dans la littérature, " se souvient-elle. " Mais si vous colliez des milliers et des milliers de documents, alors vous pourriez créer votre propre base de données."
C'est exactement ce que Cole et ses collègues de Cambridge et du laboratoire national d'Argonne du Département de l'énergie des États-Unis (DOE) ont fait, exposer le processus dans le journal Données scientifiques .
Le papier, dit Cole, est une description de la façon de créer une base de données en utilisant le traitement du langage naturel (NLP) et le calcul haute performance, une grande partie de ces derniers a été réalisée à l'Argonne Leadership Computing Facility (ALCF), une installation utilisateur du DOE Office of Science.
Parmi les facteurs qui rendent la base de données unique, il y a l'échelle du projet et le fait qu'elle comprend à la fois des données expérimentales et calculées sur les deux structures matérielles, qui décrit le fondement atomique ou chimique d'une chose, et propriétés des matériaux, la fonctionnalité fournie par ces différentes structures.
"C'est probablement la première compilation d'une base de données à une telle échelle, avec 5, 380 couples identiques de données expérimentales et calculées, " dit Cole. " Et parce que c'est une si grande quantité, il sert de référentiel à part entière et ouvre vraiment la porte à la prédiction de nouveaux matériaux."
Beaucoup de nouveautés, les grandes bases de données sont construites uniquement sur des calculs, dont un inconvénient inhérent est qu'elles ne sont pas validées par des données expérimentales. Le dernier, peut-être le plus important, fournit une image précise des états excités du matériau, qui définissent l'état dynamique des électrons et sont utilisés pour calculer les propriétés fonctionnelles d'un matériau - propriétés optiques, dans ce cas.
Ce catalogue naissant d'états excités peut alors permettre de calculer les propriétés de matériaux encore à concevoir, élargir encore la base de données.
"Imaginez que l'on souhaite découvrir un nouveau type de matériau optique adapté à une application fonctionnelle sur mesure, et notre base de données ne contient pas cette propriété optique particulière, " explique Cole. " Nous calculons la propriété optique d'intérêt à partir des états excités disponibles pour chaque propriété dans notre base de données, et créer un matériau avec des fonctions sur mesure."
L'équipe a effectué des calculs de chimie quantique sur chaque structure pour laquelle ils avaient extrait des données sur les matériaux optiques, en utilisant le supercalculateur Theta de l'ALCF, créant ainsi la base de données des structures expérimentales et calculées appariées et de leurs propriétés optiques.
"L'un des plus grands défis a été d'extraire des candidats chimiques qui pourraient servir de colorants pour les cellules solaires à partir de 400, 000 articles scientifiques, " dit lvaro Vázquez-Mayagoitia, un informaticien dans la division Computational Science d'Argonne. "Nous avons développé un framework distribué pour appliquer des méthodes d'intelligence artificielle, tels que ceux utilisés dans le traitement du langage naturel, sur les supercalculateurs de classe mondiale de l'ALCF."
Pour extraire automatiquement ces informations et les déposer dans la base de données, l'équipe s'est tournée vers la nouvelle application d'exploration de données appelée ChemDataExtractor. Un outil de PNL, il a été conçu pour extraire du texte spécifiquement à partir de la littérature sur la chimie et les matériaux, où, Cole dit, « les informations sont éparpillées sur plusieurs milliers de documents et sont présentes sous des formes très fragmentées et non structurées ».
Pas un pour les recherches d'articles manuelles, Cole décrit la volonté de développer l'application comme une innovation issue de la frustration. Initialement, elle a essayé des packages de PNL plus génériques, mais a noté qu'"ils ne font pas qu'échouer, ils échouent de façon spectaculaire."
Le problème est dans la traduction, pas tellement du point de vue du langage humain, mais du langage de la science, bien qu'il y ait quelques similitudes.
Un écrivain, par exemple, utiliser un programme de reconnaissance vocale, une forme de PNL, pour transcrire des notes ou des entretiens. Le programme s'exerce principalement sur la voix de l'écrivain, ramasser des motifs et des nuances, et commence à transcrire assez fidèlement. Maintenant, lancez une interview avec un sujet avec un accent étranger et les choses commencent à devenir bancales.
Dans le monde de Cole, la langue étrangère est la science, chaque domaine un pays différent. Actuellement, vous devez former le programme sur une seule "langue, " dis la chimie, et même alors, vous devez apprendre les dialectes particuliers de cette science.
Les chimistes inorganiques pourraient poser une formule en utilisant des représentations inconnues des symboles d'éléments chimiques bien connus, alors que les chimistes organiques préfèrent les croquis chimiques numérotés dans une boîte d'illustration. Les informations de l'un ou l'autre s'avèrent généralement trop difficiles à extraire pour la plupart des programmes miniers.
"Et c'est juste dans un peu de chimie, " note Cole. " Parce que la façon dont les gens décrivent les choses est si diverse, la diversité dans la spécificité du domaine est absolument critique."
À cette fin, la base de données de l'équipe est l'un des attributs spectraux d'absorption ultraviolet-visible (UV/vis), qui fournit une ressource ouvertement disponible pour les utilisateurs cherchant à trouver des matériaux avec des couleurs spectrales préférées.
Alors que l'équipe utilise la nouvelle base de données pour découvrir des colorants organiques qui pourraient remplacer les colorants organo-métalliques traditionnels dans les cellules solaires, ils ont déjà ciblé des fronts plus larges pour son utilisation.
Utile comme source de données d'apprentissage pour les méthodes d'apprentissage automatique qui prédisent de nouveaux matériaux optiques, il peut également s'avérer une option simple de récupération de données pour les utilisateurs de spectroscopie d'absorption UV/vis, un outil largement utilisé dans les laboratoires de recherche du monde entier comme technique de base pour caractériser de nouveaux matériaux.
« Les protocoles utilisés dans ce projet sont déjà en cours de déploiement pour des types de projets similaires, " ajoute Vázquez-Mayagoitia. "Par exemple, l'équipe a récemment tiré parti des ressources informatiques ChemDataExtractor et ALCF pour produire de vastes bases de données de produits chimiques potentiels pour les batteries, et des composés magnétiques et supraconducteurs."
La recherche sur la base de données des matériaux optiques apparaît dans l'article "Comparative dataset of experimental and computational attributes of UV/vis absorption spectra" dans Scientific Data. Les autres auteurs incluent Edward J. Beard de l'Université de Cambridge, et Ganesh Sivaraman et Venkatram Vishwanath du Laboratoire national d'Argonne.
Un article détaillant leur travail avec les matériaux magnétiques et supraconducteurs a été publié dans Matériaux de calcul npj . La base de données des matériaux de batterie contenant plus de 290, 000 enregistrements de données ont été publiés dans Données scientifiques .