Un million de processus sont mappés sur les pixels d'un croquis en noir et blanc de 1000 × 1000 pixels d'Alan Turing. Les pixels s'allument et s'éteignent en fonction des valeurs binaires instantanées des processus. Crédit :Nature Communications
« In-memory computing » ou « computational memory » est un concept émergent qui utilise les propriétés physiques des dispositifs de mémoire à la fois pour stocker et traiter des informations. Ceci est contraire aux systèmes et dispositifs actuels de von Neumann, tels que les ordinateurs de bureau standard, ordinateurs portables et même téléphones portables, qui font la navette des données entre la mémoire et l'unité de calcul, les rendant ainsi plus lents et moins économes en énergie.
Aujourd'hui, IBM Research annonce que ses scientifiques ont démontré qu'un algorithme d'apprentissage automatique non supervisé, fonctionnant sur un million de dispositifs de mémoire à changement de phase (PCM), trouvé avec succès des corrélations temporelles dans des flux de données inconnus. Par rapport aux ordinateurs classiques de pointe, cette technologie prototype devrait produire des améliorations 200 fois en termes de vitesse et d'efficacité énergétique, ce qui le rend très approprié pour permettre l'ultra-densité, batterie faible, et des systèmes informatiques massivement parallèles pour des applications en IA.
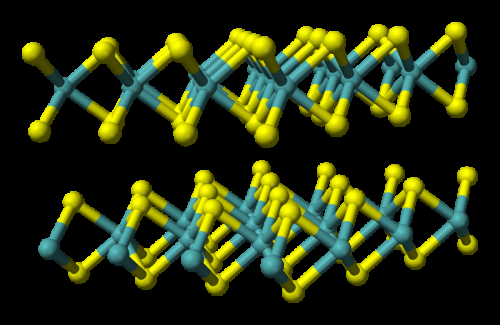
Les chercheurs ont utilisé des dispositifs PCM fabriqués à partir d'un alliage de germanium et de tellurure d'antimoine, qui est empilé et pris en sandwich entre deux électrodes. Lorsque les scientifiques appliquent un petit courant électrique au matériau, ils le chauffent, qui modifie son état d'amorphe (avec un arrangement atomique désordonné) à cristallin (avec une configuration atomique ordonnée). Les chercheurs d'IBM ont utilisé la dynamique de cristallisation pour effectuer des calculs sur place.
"C'est une étape importante dans nos recherches sur la physique de l'IA, qui explore de nouveaux matériaux matériels, appareils et architectures, " dit le Dr Evangelos Eleftheriou, un IBM Fellow et co-auteur de l'article. « Alors que les lois de mise à l'échelle CMOS s'effondrent en raison des limites technologiques, un départ radical de la dichotomie processeur-mémoire est nécessaire pour contourner les limitations des ordinateurs d'aujourd'hui. Compte tenu de la simplicité, haut débit et basse énergie de notre approche informatique en mémoire, il est remarquable que nos résultats soient si similaires à notre approche classique de référence exécutée sur un ordinateur von Neumann. »
Les détails sont expliqués dans leur article paru aujourd'hui dans la revue à comité de lecture Communication Nature . Pour démontrer la technologie, les auteurs ont choisi deux exemples basés sur le temps et comparé leurs résultats avec des méthodes traditionnelles d'apprentissage automatique telles que le clustering k-means :
"La mémoire a jusqu'à présent été considérée comme un endroit où nous stockons simplement des informations. Mais dans ce travail, nous montrons de manière concluante comment nous pouvons exploiter la physique de ces dispositifs de mémoire pour effectuer également une primitive de calcul de haut niveau. Le résultat du calcul est également stocké dans les dispositifs de mémoire, et en ce sens, le concept est vaguement inspiré par la façon dont le cerveau calcule. " a déclaré le Dr Abu Sebastian, scientifique en mémoire exploratoire et technologies cognitives, IBM Research et auteur principal de l'article.
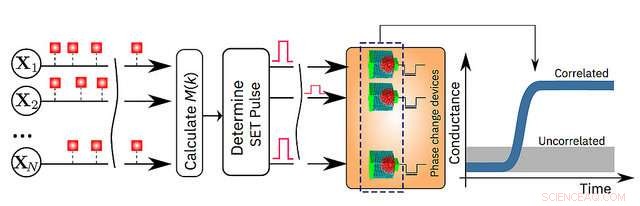
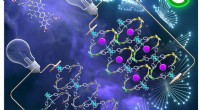
Une illustration schématique de l'algorithme de calcul en mémoire. Crédit :Recherche IBM