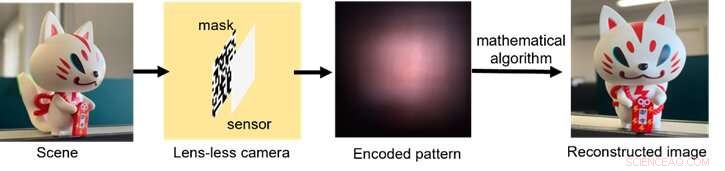
Un schéma du fonctionnement du processus d'imagerie sans lentille, de la collecte de la lumière au codage du signal jusqu'au post-traitement avec des algorithmes informatiques. Crédit :Xiuxi Pan de Tokyo Tech
Une caméra nécessite généralement un système d'objectif pour capturer une image focalisée, et la caméra à objectif est la solution d'imagerie dominante depuis des siècles. Une caméra à objectif nécessite un système d'objectif complexe pour obtenir une imagerie de haute qualité, lumineuse et sans aberration. Les dernières décennies ont vu une augmentation de la demande d'appareils photo plus petits, plus légers et moins chers. Il existe un besoin évident de caméras de nouvelle génération dotées de fonctionnalités élevées, suffisamment compactes pour être installées n'importe où. Cependant, la miniaturisation de la caméra à objectif est limitée par le système d'objectif et la distance de mise au point requise par les lentilles réfractives.
Les progrès récents de la technologie informatique peuvent simplifier le système de lentilles en remplaçant l'informatique par certaines parties du système optique. L'objectif entier peut être abandonné grâce à l'utilisation de l'informatique de reconstruction d'image, permettant une caméra sans objectif, ultra-mince, légère et peu coûteuse. L'appareil photo sans objectif a récemment gagné en popularité. Mais jusqu'à présent, la technique de reconstruction d'image n'a pas été établie, ce qui entraîne une qualité d'image inadéquate et un temps de calcul fastidieux pour la caméra sans objectif.
Récemment, des chercheurs ont développé une nouvelle méthode de reconstruction d'image qui améliore le temps de calcul et fournit des images de haute qualité. Décrivant la motivation initiale derrière la recherche, un membre central de l'équipe de recherche, le professeur Masahiro Yamaguchi de Tokyo Tech, déclare :« Sans les limitations d'un objectif, l'appareil photo sans objectif pourrait être ultra-miniature, ce qui pourrait permettre de nouvelles applications qui sont au-delà de notre imagination." Leurs travaux ont été publiés dans Optics Letters .
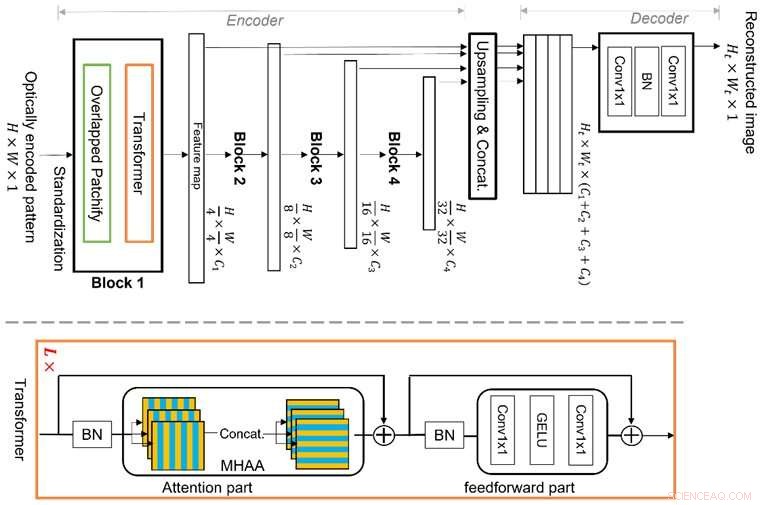
Vision Transformer (ViT) est une technique d'apprentissage automatique de pointe, qui est meilleure pour le raisonnement des caractéristiques globales en raison de sa nouvelle structure de blocs de transformateurs à plusieurs étages avec des modules "patchify" superposés. Cela lui permet d'apprendre efficacement les caractéristiques de l'image dans une représentation hiérarchique, ce qui lui permet de traiter la propriété de multiplexage et d'éviter les limites de l'apprentissage en profondeur conventionnel basé sur CNN, permettant ainsi une meilleure reconstruction d'image. Crédit :Xiuxi Pan de Tokyo Tech
Le matériel optique typique de la caméra sans objectif se compose simplement d'un masque fin et d'un capteur d'image. L'image est ensuite reconstruite à l'aide d'un algorithme mathématique. Le masque et le capteur peuvent être fabriqués ensemble dans des processus de fabrication de semi-conducteurs établis pour une production future. Le masque code optiquement la lumière incidente et projette des motifs sur le capteur. Bien que les motifs moulés soient complètement non interprétables à l'œil humain, ils peuvent être décodés avec une connaissance explicite du système optique.
Cependant, le processus de décodage, basé sur la technologie de reconstruction d'image, reste difficile. Les méthodes traditionnelles de décodage basées sur un modèle se rapprochent du processus physique de l'optique sans lentille et reconstruisent l'image en résolvant un problème d'optimisation "convexe". Cela signifie que le résultat de la reconstruction est sensible aux approximations imparfaites du modèle physique. De plus, le calcul nécessaire à la résolution du problème d'optimisation est chronophage car il nécessite un calcul itératif. L'apprentissage en profondeur pourrait aider à éviter les limites du décodage basé sur un modèle, car il peut apprendre le modèle et décoder l'image par un processus direct non itératif à la place. Cependant, les méthodes d'apprentissage en profondeur existantes pour l'imagerie sans lentille, qui utilisent un réseau neuronal convolutif (CNN), ne peuvent pas produire d'images de haute qualité. Ils sont inefficaces car CNN traite l'image en fonction des relations des pixels "locaux" voisins, alors que les optiques sans lentille transforment les informations locales de la scène en informations "globales" superposées sur tous les pixels du capteur d'image, via une propriété appelée "multiplexage". "

La caméra sans objectif se compose d'un masque et d'un capteur d'image avec une distance de séparation de 2,5 mm. Le masque est fabriqué par dépôt de chrome dans une plaque de silice synthétique de taille d'ouverture 40x40 µm. Crédit :Xiuxi Pan de Tokyo Tech
L'équipe de recherche de Tokyo Tech étudie cette propriété de multiplexage et a maintenant proposé un nouvel algorithme d'apprentissage automatique dédié à la reconstruction d'images. L'algorithme proposé est basé sur une technique d'apprentissage automatique de pointe appelée Vision Transformer (ViT), qui est meilleure pour le raisonnement global des caractéristiques. La nouveauté de l'algorithme réside dans la structure des blocs de transformateurs à plusieurs étages avec des modules "patchify" superposés. Cela lui permet d'apprendre efficacement les caractéristiques de l'image dans une représentation hiérarchique. Par conséquent, la méthode proposée peut bien traiter la propriété de multiplexage et éviter les limitations de l'apprentissage en profondeur conventionnel basé sur CNN, permettant une meilleure reconstruction d'image.
Alors que les méthodes conventionnelles basées sur des modèles nécessitent de longs temps de calcul pour le traitement itératif, la méthode proposée est plus rapide car la reconstruction directe est possible avec un algorithme de traitement sans itération conçu par apprentissage automatique. L'influence des erreurs d'approximation du modèle est également considérablement réduite car le système d'apprentissage automatique apprend le modèle physique. De plus, la méthode basée sur ViT proposée utilise des caractéristiques globales dans l'image et convient au traitement de modèles projetés sur une large zone sur le capteur d'image, tandis que les méthodes de décodage conventionnelles basées sur l'apprentissage automatique apprennent principalement les relations locales par CNN.
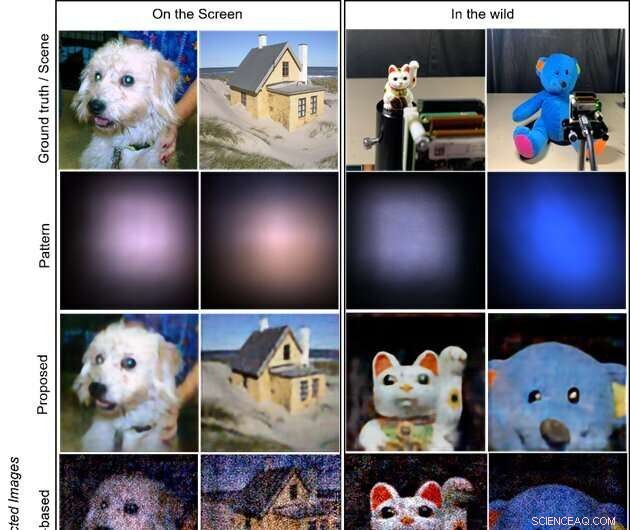
Les cibles sont les images affichées sur un écran LCD (deux colonnes de gauche) et les objets dans la nature (deux colonnes de droite ; chat faisant signe de la poupée et ours en peluche), respectivement. La première rangée montre les images de vérité au sol affichées à l'écran et les scènes de prise de vue pour les objets dans la nature. La deuxième ligne montre les motifs capturés sur le capteur. Les trois dernières rangées illustrent les images reconstruites par les méthodes proposées, basées sur un modèle et basées sur CNN, respectivement. La méthode proposée produit des images de la plus haute qualité et visuellement attrayantes. Crédit :Xiuxi Pan de Tokyo Tech
En résumé, la méthode proposée résout les limites des méthodes conventionnelles telles que le traitement itératif basé sur la reconstruction d'images et l'apprentissage automatique basé sur CNN avec l'architecture ViT, permettant l'acquisition d'images de haute qualité dans un court laps de temps de calcul. L'équipe de recherche a en outre effectué des expériences optiques - comme indiqué dans leur dernière publication en - qui suggèrent que l'appareil photo sans objectif avec la méthode de reconstruction proposée peut produire des images de haute qualité et visuellement attrayantes tandis que la vitesse de calcul de post-traitement est suffisamment élevée pour de vrai- capture du temps.
"Nous réalisons que la miniaturisation ne devrait pas être le seul avantage de la caméra sans objectif. La caméra sans objectif peut être appliquée à l'imagerie en lumière invisible, dans laquelle l'utilisation d'un objectif est peu pratique, voire impossible. De plus, la dimensionnalité sous-jacente des informations optiques capturées par l'appareil photo sans objectif est supérieur à deux, ce qui rend possible l'imagerie 3D en une seule prise et le recentrage post-capture. Nous explorons d'autres fonctionnalités de l'appareil photo sans objectif. L'objectif ultime d'un appareil photo sans objectif est d'être miniature mais puissant. Nous sommes ravis d'être à la tête de cette nouvelle direction pour les solutions d'imagerie et de détection de nouvelle génération », déclare l'auteur principal de l'étude, M. Xiuxi Pan de Tokyo Tech, tout en parlant de leurs travaux futurs. Extension de la microspectroscopie infrarouge avec la méthode de reconstruction computationnelle Lucy-Richardson-Rosen