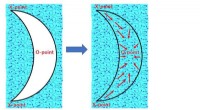
La compréhension du LLNL de la physique de l'implosion par fusion par confinement inertiel est basée sur une combinaison de ensembles de simulation de faible fidélité; clairsemé, expériences difficiles à diagnostiquer; et les meilleures simulations physiques qui repoussent les limites de la technologie de calcul haute performance. Créer et synthétiser ces données dans une meilleure compréhension de la physique nécessitera de multiples techniques complémentaires de la science des données, quantification de l'incertitude et intelligence artificielle. Crédit :Damien Jemison/LLNL
En appliquant des méthodes modernes d'apprentissage automatique et de science des données à la physique des plasmas « extrêmes », les chercheurs peuvent mieux comprendre notre univers et trouver des indices sur la création d'une quantité illimitée d'énergie.
Dans une perspective récente publiée dans La nature , Les scientifiques et les collaborateurs internationaux du Lawrence Livermore National Laboratory (LLNL) décrivent les principaux défis et les orientations futures de l'utilisation de l'apprentissage automatique (ML) et d'autres techniques basées sur les données pour mieux comprendre ces conditions extrêmes qui ouvrent potentiellement la voie à la fusion nucléaire en tant que source d'énergie industrielle, ainsi que d'aider à améliorer notre compréhension de l'univers.
Le plasma extrême est décrit comme la physique de la matière à des densités extrêmes, des températures et des pressions semblables à celles que l'on trouve à l'intérieur des étoiles et des planètes.
"Les expériences de physique des plasmas extrêmes avaient historiquement un débit de données très faible, mais les futures installations laser prévues auront un taux de tir très élevé, avec le potentiel de produire d'énormes quantités de données, " a déclaré Gemma Anderson, physicienne du LLNL, l'un des principaux auteurs de l'article. "Cela fera à son tour passer le domaine dans le régime des mégadonnées et créera un besoin correspondant d'exploiter beaucoup plus les méthodes modernes de science des données."
La dernière génération d'installations de physique extrême peut effectuer des expériences plusieurs fois par seconde (plutôt que presque quotidiennement) – passant d'un contrôle basé sur l'homme à un contrôle automatique. Pour tirer le meilleur parti des opportunités émergentes, l'équipe a proposé un playbook pour l'utilisation de l'apprentissage automatique dans la science à haute densité d'énergie grâce à la conception de la recherche, entraînement, les meilleures pratiques et le support pour les diagnostics synthétiques et l'analyse des données.
L'étude de la physique des plasmas sous températures extrêmes, les densités et l'intensité du champ électromagnétique sont importantes pour comprendre l'astrophysique, fusion nucléaire et physique fondamentale. Ces systèmes sont fortement non linéaires et sont très difficiles à comprendre théoriquement ou à démontrer expérimentalement.
Anderson et ses collègues ont suggéré que les modèles d'apprentissage automatique et les méthodes basées sur les données pourraient être la réponse en remodelant l'exploration de ces systèmes extrêmes qui se sont avérés beaucoup trop complexes pour que les chercheurs humains le fassent seuls. Interpréter les données des expérimentations de ces systèmes, comme le National Ignition Facility, nécessite la compréhension simultanée de grandes quantités de données multimodales complexes provenant de plusieurs sources différentes. L'image ci-dessus montre un flux de travail potentiel qui intègre pleinement des méthodes basées sur les données et l'apprentissage automatique pour atteindre cet objectif. L'optimisation des systèmes de physique extrême nécessite un réglage fin sur un grand nombre de paramètres (souvent fortement corrélés). Les méthodes d'intelligence artificielle se sont avérées très efficaces pour démêler les corrélations dans de grands ensembles de données et peuvent être cruciales pour comprendre et optimiser des systèmes qui jusqu'à présent étaient difficiles à comprendre.
Le document était le résultat d'un atelier organisé par Anderson, son collègue LLNL Jim Gaffney et Peter Hatfield de l'Université d'Oxford, tenue au Centre Lorentz aux Pays-Bas en janvier 2020. Un objectif clé de la réunion était de rédiger un livre blanc détaillant les conclusions de la réunion :quelles normes la communauté devrait adopter, ce que l'apprentissage automatique peut faire pour le terrain et ce que l'avenir peut nous réserver.
Anderson a déclaré que le document serait distribué aux principaux organismes de financement et décideurs des conseils de recherche et des laboratoires nationaux.