Crédit :CERN
Le modèle standard de la physique des particules résume nos connaissances actuelles sur les particules élémentaires et leurs interactions. Le modèle standard n'est pas complet; par exemple, il ne décrit pas des observations telles que la gravité, n'a aucune prédiction pour la matière noire, qui constitue la majeure partie de la matière dans l'univers, ou que les neutrinos ont une masse.
Pour corriger les faiblesses du modèle standard, les physiciens proposent des extensions et vérifient les collisions au LHC pour voir si les prédictions de ces modèles de "physique au-delà du modèle standard" apparaîtraient comme de nouvelles particules ou des changements dans le comportement de particules connues. Supersymétrie, ou SUSY pour faire court, est l'une de ces extensions du modèle standard. La supersymétrie prédit que chaque type de particule connu dans le modèle standard a un partenaire supersymétrique. Le nombre de types de particules dans la nature serait alors effectivement doublé, et de nombreuses nouvelles interactions entre les particules régulières et les nouvelles particules SUSY seraient possibles.
Dans une expérience de collisionneur comme CMS, l'espoir est de produire des particules SUSY, puis de rechercher des signes de leur désintégration à l'intérieur du détecteur. L'une des signatures les plus courantes de la supersymétrie serait mesurée par des particules apparemment manquantes qui créent un déséquilibre énergétique substantiel dans le détecteur appelé énergie transversale manquante. Il s'agit d'une signature à l'état final qu'il est difficile de manquer !
De nombreuses recherches ont eu lieu chez CMS pour rechercher ces signatures énergétiques transverses manquantes élevées, mais aucune preuve de cette supersymétrie n'a été trouvée. Mais, peut-être que la supersymétrie est là, et c'est juste "plus furtif" qu'on ne le pensait initialement. Il existe de nombreuses signatures possibles que la supersymétrie pourrait créer, et dans certaines versions modifiées de la supersymétrie, une caractéristique clé est la prédiction que toutes les particules SUSY se désintégreraient en particules de modèle standard, par exemple, quarks, dont chacun apparaîtrait dans le détecteur comme un jet de particules, qui s'appelle un jet. Si cette version de la supersymétrie est réelle, La production de particules SUSY dans une collision proton-proton se traduira par un état final avec de nombreux jets plutôt qu'un avec une énergie manquante considérable. Dans ce cas, il serait logique que ces recherches précédentes n'aient rien trouvé !
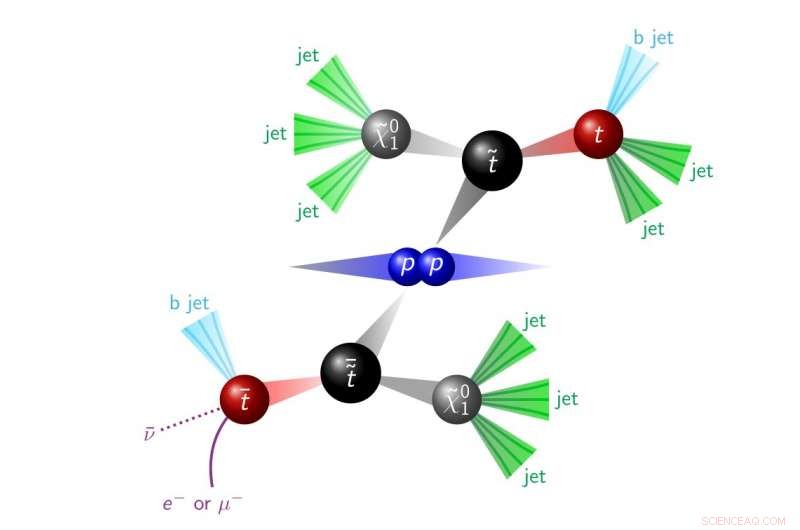
Figure 1. Une dramatisation d'une collision proton-proton produisant des particules SUSY, qui se désintègrent en objets observés dans le détecteur (il s'agit d'une signature pour ce qu'on appelle la parité R violant SUSY). Crédit :CERN
Le but de cette recherche est de savoir si oui ou non la supersymétrie s'y est cachée depuis le début en recherchant spécifiquement la production de deux quarks top supersymétriques (appelés top squarks). Ces top squarks se désintègrent dans le détecteur, créant deux quarks top et de nombreux autres jets, comme le montre la figure 1. Cette signature n'est pas aussi apparente que celle qui inclut de grandes quantités d'énergie manquante car il existe de nombreuses manières différentes pour le modèle standard de produire deux quarks top et de nombreux jets. Cependant, ce signal top squark a tendance à produire plus de jets en moyenne que n'importe lequel des processus d'arrière-plan connus. La modélisation d'événements avec un très grand nombre de jets est également très délicate, et même les meilleurs outils de simulation ne réussissent pas toujours. Par conséquent, les données sont utilisées pour prédire le nombre d'événements avec un certain nombre de jets.
Notre stratégie n'aurait pas été possible sans exploiter la puissance de l'apprentissage automatique et des réseaux de neurones. Une technique d'apprentissage machine cool qui a été utilisée pour identifier les collisions qui pourraient contenir les désintégrations des top squarks s'appelle l'inversion de gradient, qui peut s'expliquer de la manière suivante. Imaginez que vous triez les chocolats en deux catégories :les chocolats au caramel et les chocolats ordinaires. Vous savez que les chocolats au caramel sont plus lourds que les chocolats ordinaires car ils sont fourrés au caramel. Disons aussi que les chocolats ne se présentent que sous deux formes parmi toutes les variétés caramel et régulières :des carrés ou des cercles. Finalement, on vous dit que les chocolats carrés sont, en moyenne, plus lourds que les circulaires.
Une façon de trier les chocolats consiste à trier tous les chocolats carrés en chocolats au caramel et tous les chocolats circulaires en chocolats ordinaires. Après tout, les chocolats carrés et les chocolats au caramel sont en général plus lourds. Cette approche de tri n'est pas correcte car tous les chocolats carrés ne contiennent pas de caramel, il est donc probablement préférable de trier les chocolats indépendamment de leur forme. Ignorer la forme lors du tri équivaut à ce que l'inversion de gradient nous permet de faire dans le contexte de la physique. Au lieu du caramel et des chocolats ordinaires, le tri se fait entre les événements de signal et de fond, et au lieu de la forme, le tri doit être indépendant du nombre de jets.
Cette stratégie est précisément ce qui est nécessaire pour modéliser la distribution du nombre de jets directement à partir des données. Les événements de la catégorie d'arrière-plan sont utilisés pour prédire combien d'événements il devrait y avoir avec un certain nombre de jets dans la catégorie de signal. Étant donné que le modèle de signal a tendance à produire plus de jets que les arrière-plans du modèle standard, tout écart par rapport à la prédiction pourrait signifier qu'il y avait effectivement un certain SUSY qui s'y cachait.
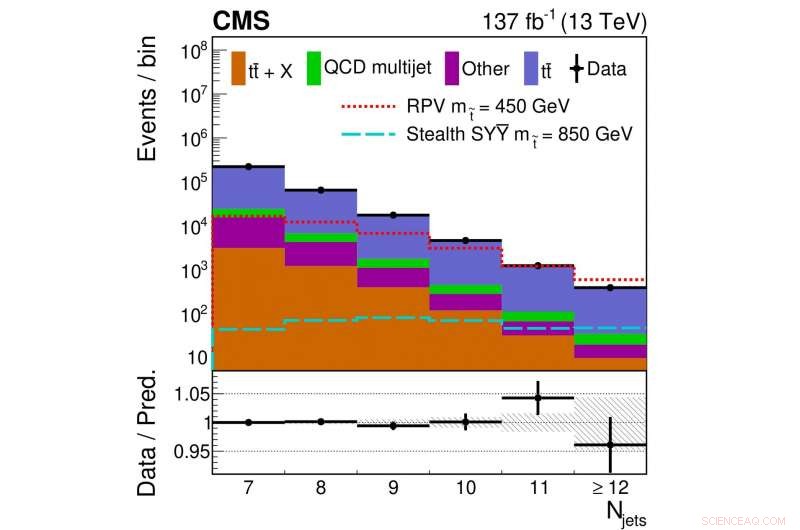
Figure 2. La distribution du nombre d'événements avec un certain nombre de jets est montrée pour les données collectées (points noirs) et les contributions prédites à partir d'arrière-plans de modèles standards connus (blocs colorés). Différentes lignes de couleurs/styles indiquent le nombre de distributions de jets pour différents modèles SUSY avec des masses de squark supérieures spécifiques.
La figure 2 montre une comparaison de la distribution du nombre de jets obtenue à partir des données collectées avec celle de notre prédiction de fond finale. Dans ce cas, la prédiction suppose qu'il n'y a aucune contribution de nos modèles de signaux hypothétiques. Ici, l'accord entre les données et notre prédiction à partir de quatre catégories de processus de modèle standard est raisonnablement bon.
Lorsque les données sont réparties en plus de catégories que celles illustrées à la figure 2, un petit écart par rapport à notre prédiction est trouvé. Cependant, l'écart n'est pas assez grand pour affirmer clairement si cela indique ou non que la supersymétrie pourrait être correcte. Il est fort probable qu'il y ait eu juste une fluctuation statistique dans les données, ou peut-être qu'il y a un problème de modélisation inconnu.
En physique des particules, le «gold standard» consiste à déclarer une découverte de nouvelle physique lorsqu'un résultat a une signification de 5 écarts-types ou plus. Cela signifie qu'il n'y a qu'une chance sur 3,5 millions que le résultat soit simplement dû à une fluctuation aléatoire des données. Preuve, ou prétendre que quelque chose est suffisamment intéressant pour envisager la possibilité qu'il soit nouveau, ne se fait qu'avec une significativité de 3 écarts types, représentant une chance sur 740 que le résultat soit une fluctuation. Cette norme est très stricte par rapport à la plupart des autres disciplines scientifiques. Le LHC produit une énorme quantité de données, il peut donc en effet arriver qu'un écart par rapport à la prédiction du modèle standard soit obtenu par hasard. En physique des particules, il n'est certainement pas justifié de revendiquer un quelconque écart sans examiner sérieusement sa validité statistique.
La signification du plus grand écart observé dans cette analyse, sans correction pour l'effet regard ailleurs, est de 2,8 écarts types. Cela signifie que même s'il n'y a pas de supersymétrie, on s'attend à voir un tel résultat une fois toutes les 368 fois, bien en deçà du seuil de 5 écarts-types. Étant donné que CMS a publié plus de 1000 articles, beaucoup cherchent dans des dizaines ou des centaines d'endroits, vous pouvez voir qu'une fluctuation occasionnelle d'un résultat n'est pas du tout surprenante. Les résultats peuvent également être interprétés comme une limite aux scénarios de supersymétrie furtive autorisés qui sont toujours cohérents avec les données. Selon les détails du modèle, les masses de squark supérieures inférieures à ~700 GeV peuvent être exclues.
Cette recherche est la première du genre au LHC, mettre en lumière une signature jusque-là inexplorée. Le léger écart constaté est alléchant et incite des études de suivi à rechercher si son origine est une simple fluctuation statistique, si cela est dû à notre compréhension du modèle standard, ce qui serait intéressant en soi, ou si cela pourrait être le premier signe d'une nouvelle physique. Aussi, à partir de 2022, la prochaine période de prise de données du LHC commencera. Cela aidera CMS à tirer des conclusions encore plus solides sur la possibilité d'une nouvelle physique. Si la supersymétrie furtive existe vraiment, alors ces données supplémentaires permettraient un résultat plus significatif, potentiellement pousser vers l'étalon-or pour la découverte.