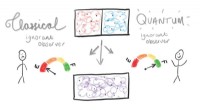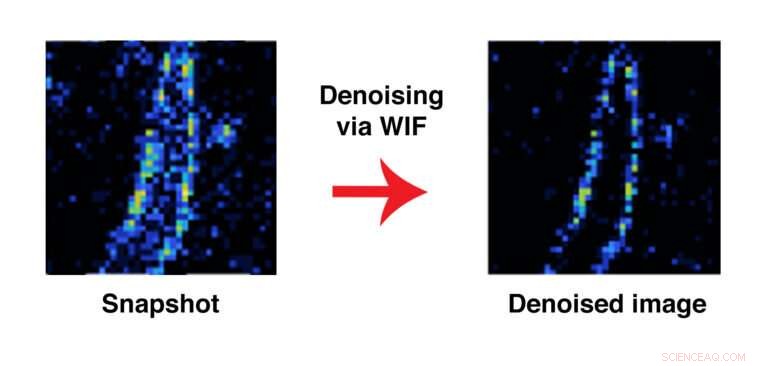
Des chercheurs de la McKelvey School of Engineering ont développé une méthode de calcul qui leur permet de déterminer non pas si une image d'imagerie entière est exacte, mais si un point donné sur l'image est probable, sur la base des hypothèses intégrées dans le modèle. Ici, une image d'une fibrille amyloïde avant et après l'application de la méthode connue sous le nom de WIF. Crédit :Lew Lab
Un agent immobilier envoie à un acheteur potentiel une photo floue d'une maison prise de l'autre côté de la rue. L'acheteur peut la comparer à la réalité :regardez la photo, puis regardez la vraie maison et voyez que la baie vitrée est en fait deux fenêtres rapprochées, les fleurs à l'avant sont en plastique et ce qui ressemblait à une porte est en fait un trou dans le mur.
Que faire si vous ne regardez pas une photo d'une maison, mais quelque chose de très petit, comme une protéine ? Il n'y a aucun moyen de le voir sans un appareil spécialisé, il n'y a donc rien pour juger l'image, pas de "vérité sur le terrain, ' comme on l'appelle. Il n'y a pas grand-chose à faire, à part croire que l'équipement d'imagerie et le modèle informatique utilisé pour créer des images sont précis.
Maintenant, cependant, la recherche du laboratoire de Matthew Lew à la McKelvey School of Engineering de l'Université de Washington à St. Louis a développé une méthode de calcul pour déterminer le degré de confiance qu'un scientifique devrait avoir que ses mesures, à un moment donné, sont exacts, étant donné le modèle utilisé pour les produire.
La recherche a été publiée le 11 décembre dans Communication Nature .
"Fondamentalement, il s'agit d'un outil médico-légal pour vous dire si quelque chose va bien ou non, " dit Lew, professeur adjoint au département Preston M. Green de génie électrique et des systèmes. Ce n'est pas simplement un moyen d'obtenir une image plus nette. « C'est une toute nouvelle façon de valider la fiabilité de chaque détail d'une image scientifique.
"Il ne s'agit pas d'offrir une meilleure résolution, " il a ajouté de la méthode de calcul, appelé flux induit par Wasserstein (WIF). "C'est dire, 'Cette partie de l'image peut être erronée ou déplacée.'"
Le processus utilisé par les scientifiques pour « voir » la très petite microscopie de localisation de molécule unique (SMLM) – repose sur la capture de quantités massives d'informations à partir de l'objet en cours d'imagerie. Ces informations sont ensuite interprétées par un modèle informatique qui supprime finalement la plupart des données, reconstruire une image apparemment précise - une image fidèle d'une structure biologique, comme une protéine amyloïde ou une membrane cellulaire.
Il existe déjà quelques méthodes pour aider à déterminer si une image est, en général, une bonne représentation de la chose imagée. Ces méthodes, cependant, ne peut pas déterminer la probabilité qu'un seul point de données dans une image soit précis.
Hesam Mazidi, un récent diplômé qui était doctorant au laboratoire de Lew pour cette recherche, abordé le problème.
"Nous voulions voir s'il y avait un moyen de faire quelque chose à propos de ce scénario sans vérité sur le terrain, " a-t-il dit. " Si nous pouvions utiliser la modélisation et l'analyse algorithmique pour quantifier si nos mesures sont fidèles, ou assez précis."
Les chercheurs n'avaient pas de vérité sur le terrain - pas de maison à comparer à la photo de l'agent immobilier - mais ils n'avaient pas les mains vides. Ils avaient une mine de données qui sont généralement ignorées. Mazidi a profité de la quantité massive d'informations recueillies par l'appareil d'imagerie qui sont généralement rejetées comme du bruit. La distribution du bruit est quelque chose que les chercheurs peuvent utiliser comme vérité terrain car elle se conforme à des lois spécifiques de la physique.
« Il a pu dire, 'Je sais comment se manifeste le bruit de l'image, c'est une loi physique fondamentale, '", a déclaré Lew à propos de la perspicacité de Mazidi.
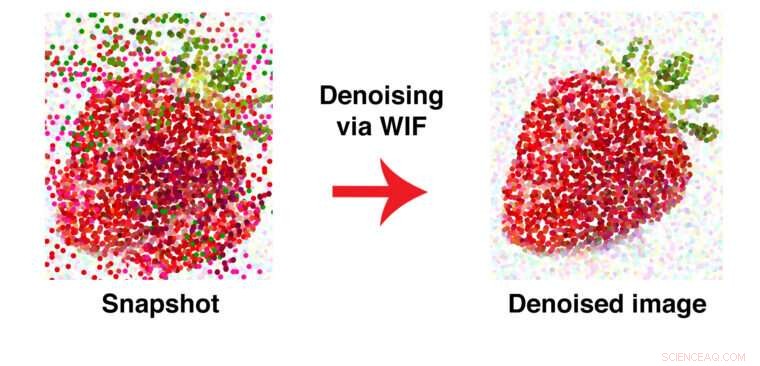
Ce graphique illustre la façon dont WIF supprime les points de données égarés. Après débruitage, des morceaux verts de « feuille » sont retirés du corps rouge du fruit. Crédit :Washington University à St. Louis
"Il est retourné au bruyant, domaine imparfait de la mesure scientifique réelle, " a déclaré Lew. Tous les points de données enregistrés par l'appareil d'imagerie. "Il y a de vraies données là-bas que les gens jettent et ignorent."
Au lieu de l'ignorer, Mazidi a regardé pour voir dans quelle mesure le modèle prédit le bruit, compte tenu de l'image finale et du modèle qui l'a créé.
L'analyse d'autant de points de données revient à exécuter le périphérique d'imagerie encore et encore, effectuer plusieurs tests pour le calibrer.
"Toutes ces mesures nous donnent une confiance statistique, " dit Lew.
WIF leur permet de déterminer non si l'image entière est probable en fonction du modèle, mais, vu l'image, si un point donné sur l'image est probable, sur la base des hypothèses intégrées dans le modèle.
Finalement, Mazidi a développé une méthode qui peut dire avec une forte confiance statistique qu'un point de données donné dans l'image finale doit ou ne doit pas être à un endroit particulier.
C'est comme si l'algorithme analysait l'image de la maison et, sans jamais avoir vu l'endroit, nettoyait l'image, révélant le trou dans le mur.
À la fin, l'analyse donne un nombre unique par point de données, entre -1 et 1. Le plus proche de un, plus un scientifique peut être sûr qu'un point sur une image est, En réalité, représentant fidèlement la chose imagée.
Ce processus peut également aider les scientifiques à améliorer leurs modèles. "Si vous pouvez quantifier les performances, alors vous pouvez également améliorer votre modèle en utilisant le score, " a déclaré Mazidi. Sans accès à la vérité sur le terrain, "il nous permet d'évaluer les performances dans des conditions expérimentales réelles plutôt qu'une simulation."
Les utilisations potentielles du WIF sont de grande envergure. Lew a déclaré que la prochaine étape consiste à l'utiliser pour valider l'apprentissage automatique, où des ensembles de données biaisés peuvent produire des résultats inexacts.
Comment un chercheur saurait-il, dans ce cas, que leurs données étaient biaisées ? "En utilisant ce modèle, vous seriez en mesure de tester sur des données qui n'ont pas de vérité terrain, où vous ne savez pas si le réseau de neurones a été formé avec des données similaires aux données du monde réel.
« Il faut être prudent dans chaque type de mesure que vous prenez, " Lew a déclaré. "Parfois, nous voulons juste appuyer sur le gros bouton rouge et voir ce que nous obtenons, mais nous devons nous souvenir, il se passe beaucoup de choses lorsque vous appuyez sur ce bouton."