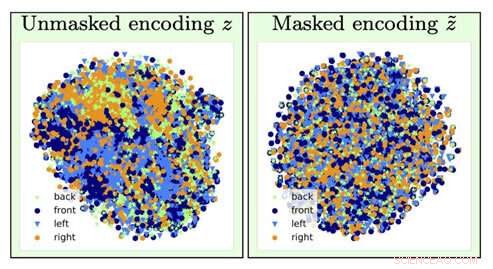
Pour identifier le type d'une image de chaise, l'information sur l'orientation de la chaise (facteur de nuisance) est perdue par l'opération d'oubli (passage de la visualisation gauche vers la droite). Crédit :Université de Californie du Sud
Imaginez si la prochaine fois que vous faites une demande de prêt, un algorithme informatique détermine que vous devez payer un taux plus élevé en fonction principalement de votre race, sexe ou code postal.
Maintenant, imaginez qu'il était possible de former un modèle d'apprentissage profond d'IA pour analyser ces données sous-jacentes en induisant une amnésie :il oublie certaines données et se concentre uniquement sur d'autres.
Si vous pensez que cela ressemble à la version de l'informaticien de "The Eternal Sunshine of the Spotless Mind, " vous seriez plutôt sur. Et grâce aux chercheurs en IA de l'Institut des sciences de l'information (ISI) de l'USC, ce concept, appelé oubli contradictoire, est désormais un véritable mécanisme.
L'importance d'aborder et d'éliminer les biais dans l'IA devient de plus en plus importante à mesure que l'IA devient de plus en plus répandue dans notre vie quotidienne, a noté Ayush Jaiswal, l'auteur principal de l'article et Ph.D. candidat à l'USC Viterbi School of Engineering.
« IA et, plus précisement, les modèles d'apprentissage automatique héritent des biais présents dans les données sur lesquelles ils sont formés et sont même susceptibles d'amplifier ces biais, " a-t-il expliqué. " L'IA est utilisée pour prendre plusieurs décisions de la vie réelle qui nous affectent tous, [tels que] la détermination des limites de crédit, approuver les prêts, notation des candidatures, etc. Si, par exemple, les modèles pour prendre ces décisions sont entraînés à l'aveugle sur des données historiques sans contrôler les biais, ils apprendraient à traiter injustement les individus qui appartiennent à des couches historiquement défavorisées de la population, comme les femmes et les personnes de couleur."
La recherche a été dirigée par Wael AbdAlmageed, chef d'équipe de recherche à l'ISI et professeur agrégé de recherche au département de génie électrique et informatique de l'USC Viterbi, Ming Hsieh, et professeur agrégé de recherche Greg Ver Steeg, ainsi que Premkumar Natarajan, enseignant-chercheur en informatique et directeur exécutif de l'ISI (en congé). Sous leur direction, Jaiswal et co-auteur Daniel Moyer, Doctorat., développé l'approche accusatoire de l'oubli, qui enseigne aux modèles d'apprentissage en profondeur de ne pas tenir compte des spécificités, facteurs de données indésirables afin que les résultats qu'ils produisent soient impartiaux et plus précis.
Le document de recherche, intitulé « Représentations invariantes par l'oubli contradictoire, " a été présenté à la conférence de l'Association for the Advancement for Artificial Intelligence à New York le 10 février, 2020.
Nuisances et réseaux de neurones
L'apprentissage en profondeur est un composant essentiel de l'IA et peut apprendre aux ordinateurs à trouver des corrélations et à faire des prédictions avec des données, aider à identifier des personnes ou des objets, par exemple. Les modèles recherchent essentiellement des associations entre différentes caractéristiques au sein des données et la cible qu'elles sont censées prédire. Si un modèle a été chargé de trouver une personne spécifique d'un groupe, il analyserait les traits du visage pour distinguer tout le monde et ensuite identifier la personne ciblée. Simple, droit?
Malheureusement, les choses ne se passent pas toujours aussi bien, car le modèle peut finir par apprendre des choses qui peuvent sembler contre-intuitives. Il pourrait associer votre identité à un arrière-plan ou à une configuration d'éclairage particulier et être incapable de vous identifier si l'éclairage ou l'arrière-plan a été modifié ; il pourrait associer votre écriture à un certain mot, et soyez confus si le même mot a été écrit de la main de quelqu'un d'autre. Ces facteurs de nuisance bien nommés ne sont pas liés à la tâche que vous essayez d'effectuer, et les associer à tort à la cible de prédiction peut en fait s'avérer dangereux.
Les modèles peuvent également apprendre des biais dans les données qui sont corrélés avec la cible de prédiction mais qui ne sont pas souhaités. Par exemple, dans les tâches réalisées par des modèles impliquant des données socio-économiques collectées historiquement, comme la détermination des cotes de crédit, lignes de crédit, et l'éligibilité au prêt, le modèle peut faire de fausses prédictions et montrer des biais en établissant des liens entre les biais et la cible de prédiction. Il peut sauter à la conclusion que puisqu'il analyse les données d'une femme, elle doit avoir un faible pointage de crédit ; puisqu'il analyse les données d'une personne de couleur, ils ne doivent pas être éligibles à un prêt. Il ne manque pas d'histoires de banques critiquées pour les décisions biaisées de leurs algorithmes quant au montant qu'elles facturent aux personnes qui ont contracté des prêts en fonction de leur race, genre, et l'éducation, même s'ils ont exactement le même profil de crédit que quelqu'un d'un segment de population socialement plus privilégié.
Comme Jaiswal l'a expliqué, le mécanisme d'oubli contradictoire "répare" les réseaux de neurones, qui sont de puissants modèles d'apprentissage en profondeur qui apprennent à prédire des cibles à partir de données. La limite de crédit que vous avez sur cette nouvelle carte de crédit que vous avez souscrite ? Un réseau de neurones a probablement analysé vos données financières pour obtenir ce nombre.
L'équipe de recherche a développé le mécanisme d'oubli contradictoire afin qu'il puisse d'abord entraîner le réseau neuronal à représenter tous les aspects sous-jacents des données qu'il analyse, puis oublier les biais spécifiés. Dans l'exemple de la limite de carte de crédit, cela voudrait dire que le mécanisme pourrait apprendre à l'algorithme de la banque à prédire la limite en oubliant, ou étant invariant à, les données particulières relatives au sexe ou à la race. "[Le mécanisme] peut être utilisé pour entraîner les réseaux de neurones à être invariants aux biais connus dans les ensembles de données d'entraînement, " dit Jaiswal. " Ceci, à son tour, aboutirait à des modèles entraînés qui ne seraient pas biaisés lors de la prise de décisions. »
Les algorithmes d'apprentissage en profondeur sont parfaits pour apprendre des choses, mais il est plus difficile de s'assurer que les algorithmes n'apprennent pas certaines choses. Le développement d'algorithmes est un processus très axé sur les données, et les données ont tendance à contenir des biais.
Mais ne pouvons-nous pas simplement retirer toutes les données sur la race, genre, et l'éducation pour éliminer les préjugés ?
Pas entièrement. Il existe de nombreux autres facteurs de données qui sont corrélés à ces facteurs sensibles qui sont importants pour les algorithmes à analyser. La clé, comme l'ont découvert les chercheurs de l'ISI AI, ajoute des contraintes dans le processus d'apprentissage du modèle pour forcer le modèle à faire des prédictions tout en étant invariant par rapport à des facteurs spécifiques de données, essentiellement, oubli sélectif.
Combattre les préjugés
L'invariance fait référence à la capacité d'identifier un objet spécifique même si son apparence (c'est-à-dire, données) est modifiée d'une manière ou d'une autre, et Jaiswal et ses collègues ont commencé à réfléchir à la manière dont ce concept pourrait être appliqué pour améliorer les algorithmes. « Mon co-auteur, Dan [Moyer], et j'ai en fait eu cette idée assez naturellement sur la base de nos expériences précédentes dans le domaine de l'apprentissage des représentations invariantes, ", a-t-il fait remarquer. Mais étoffer le concept n'était pas une tâche simple. développer] une analyse théorique du processus d'oubli, " il a dit.
Le mécanisme d'oubli contradictoire peut également être utilisé pour aider à améliorer la génération de contenu dans une variété de domaines. "Le domaine naissant de l'apprentissage machine équitable examine les moyens de réduire les biais dans la prise de décision algorithmique basée sur les données des consommateurs, " a déclaré Ver Steeg. " Un domaine plus spéculatif implique des recherches sur l'utilisation de l'IA pour générer du contenu, y compris des tentatives de livres, musique, de l'art, Jeux, et même des recettes. Pour que la génération de contenu réussisse, nous avons besoin de nouvelles façons de contrôler et de manipuler les représentations des réseaux neuronaux et le mécanisme d'oubli pourrait être un moyen de le faire."
Alors, comment les biais apparaissent-ils même dans le modèle en premier lieu ?
La plupart des modèles utilisent des données historiques, lequel, Malheureusement, peut être largement biaisé envers les communautés traditionnellement marginalisées comme les femmes, minorités, même certains codes postaux. La collecte de données est coûteuse et lourde, les scientifiques ont donc tendance à recourir à des données qui existent déjà et à former des modèles sur cette base, c'est ainsi que les préjugés entrent en scène.
La bonne nouvelle est que ces biais sont reconnus, et bien que le problème soit loin d'être résolu, des progrès sont faits pour comprendre et résoudre ces problèmes. " n la communauté des chercheurs, les gens sont certainement de plus en plus conscients des biais des ensembles de données, et concevoir et analyser des protocoles de collecte pour contrôler les biais connus, " a déclaré Jaiswal. " L'étude des biais et de l'équité dans l'apprentissage automatique s'est rapidement développée en tant que domaine de recherche au cours des dernières années. "
La détermination des facteurs à considérer comme non pertinents ou biaisés est effectuée par des experts du domaine et basée sur une analyse statistique. "Jusque là, l'invariance a principalement été utilisée pour éliminer les facteurs qui sont largement considérés comme indésirables/non pertinents au sein de la communauté des chercheurs sur la base de preuves statistiques, " a déclaré Jaiswal.
Cependant, puisque les chercheurs déterminent ce qui n'est pas pertinent ou biaisé, il peut y avoir un potentiel pour que ces déterminations se transforment elles-mêmes en biais. C'est un facteur sur lequel les chercheurs travaillent également. « Déterminer les facteurs à oublier est un problème critique qui peut facilement entraîner des conséquences imprévues, " a noté Ver Steeg. " Un article récent de Nature sur l'apprentissage équitable souligne que nous devons comprendre les mécanismes derrière la discrimination si nous espérons spécifier correctement des solutions algorithmiques. "
Le traitement de l'information humaine est extrêmement complexe, et le mécanisme d'oubli contradictoire nous aide à faire un pas de plus vers le développement d'une IA capable de penser comme nous. Comme l'a fait remarquer Ver Steeg, les humains ont tendance à séparer différentes formes d'informations sur le monde qui les entoure par des algorithmes instinctifs qui font de même, tel est le défi à relever.
"Si quelqu'un marche devant votre voiture, vous claquez sur les pauses et le slogan sur leur chemise ne vous vient même pas à l'esprit, " a déclaré Ver Steeg. " Mais si vous avez rencontré cette personne dans un contexte social, ces informations peuvent être pertinentes et vous aider à engager une conversation. Pour l'IA, différents types d'informations sont tous mélangés. Si nous pouvons apprendre aux réseaux de neurones à séparer les concepts utiles pour différentes tâches, nous espérons que cela conduira l'IA à une compréhension plus humaine du monde."
Le traitement de l'information humaine est extrêmement complexe, et le mécanisme d'oubli contradictoire nous aide à faire un pas de plus vers le développement d'une IA capable de penser comme nous. Comme l'a fait remarquer Ver Steeg, les humains ont tendance à séparer instinctivement différentes formes d'informations sur le monde qui les entoure - faire en sorte que les algorithmes fassent de même est le défi à relever.
"Si quelqu'un marche devant votre voiture, vous claquez sur les pauses et le slogan sur leur chemise ne vous vient même pas à l'esprit, " a déclaré Ver Steeg. " Mais si vous avez rencontré cette personne dans un contexte social, ces informations peuvent être pertinentes et vous aider à engager une conversation. Pour l'IA, différents types d'informations sont tous mélangés. Si nous pouvons apprendre aux réseaux de neurones à séparer les concepts utiles pour différentes tâches, nous espérons que cela conduira l'IA à une compréhension plus humaine du monde."