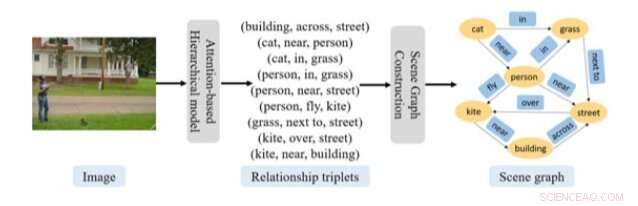
Procédure globale de prédiction de graphe de scène proposée dans l'article récent. Crédit :Gao et al.
Des chercheurs de l'Université de Shanghai ont récemment développé une nouvelle approche basée sur les réseaux de neurones récurrents (RNN) pour prédire les graphes de scène à partir d'images. Leur approche comprend un modèle composé de deux RNN basés sur l'attention, ainsi qu'un composant de localisation d'entité.
Au cours de la dernière décennie, les chercheurs dans le domaine de l'intelligence artificielle (IA) ont développé une variété d'outils automatiques pour gérer, analyser et récupérer des images numériques. Pour représenter le contenu des images, les approches traditionnelles utilisent généralement des mots-clés ou des fonctionnalités multi-vues. Cependant, s'appuyer sur des caractéristiques ou des mots-clés conduit souvent à une compréhension limitée des images, omettant de fournir des connaissances complètes à leur sujet.
Pour combler ces lacunes, il y a quelques années, une équipe de chercheurs de l'Université de Stanford, Institut Max Planck d'informatique, Yahoo Labs et Snapchat ont proposé l'utilisation d'un 'graphe de scène, ' un type de structure de données pour décrire des concepts visuels dans une image. Les graphes de scène peuvent stocker la description d'une scène représentée dans des images sous la forme d'un graphe structuré dans lequel les nœuds représentent des informations sur l'objet et les bords fournissent des prédictions entre deux nœuds.
Ces représentations structurées peuvent aider les utilisateurs à gérer les images numériques. Cependant, prédire un graphe de scène est souvent difficile, car il nécessite des outils efficaces pour reconnaître les objets, ainsi que leurs attributs et interactions entre eux.
Bien qu'il existe plusieurs approches existantes pour prédire les graphes de scène, la plupart d'entre eux ont des limitations substantielles. Dans leur étude, les chercheurs de l'université de Shangai ont entrepris de développer un modèle basé sur un réseau de neurones pour prédire les graphiques de scène d'un point de vue visuel orienté vers l'attention.
"Un graphe de scène fournit une puissante structure de connaissances intermédiaires pour diverses tâches visuelles, y compris la récupération d'images sémantiques, sous-titrage des images, et réponse visuelle aux questions, " les chercheurs ont écrit dans leur article, qui a été publié sur Wiley Online Library. "Dans ce document, la tâche de prédire un graphe de scène pour une image est formulée comme deux problèmes connexes, c'est-à-dire reconnaître les triplés relationnels, structuré comme , et la construction du graphe de scène à partir des triplets de relations reconnus."
L'approche conçue par cette équipe de chercheurs comporte deux volets clés, l'un visait à reconnaître ce qu'ils appellent des « triplets relationnels » et l'autre à construire un graphe de scène. Reconnaître les triplés relationnels, les chercheurs ont utilisé un modèle composé de deux RNN basés sur l'attention dans une organisation hiérarchique.
"Le premier réseau génère un vecteur thématique pour chaque triplet de relations, alors que le deuxième réseau prédit chaque mot dans ce triplet de relation étant donné le vecteur de sujet, " les chercheurs ont expliqué dans leur article. " Cette approche capture avec succès la structure compositionnelle et la dépendance contextuelle d'une image et les triplets relationnels décrivant sa scène. "
Une fois que ce modèle basé sur RNN a extrait les informations pertinentes d'une image, le deuxième volet de leur approche utilise ces données pour construire des graphes de scène. Pour cette étape, les chercheurs ont utilisé une approche de localisation d'entités, qui peut déterminer la structure du graphique en utilisant les informations d'attention disponibles. En plus de ces deux composants, les chercheurs ont utilisé un algorithme pour clarifier le processus par lequel leur approche convertit les informations de triplet de relations générées en un graphe de scène.
Leur approche a été évaluée à l'aide de l'ensemble de données populaire du génome visuel (VG) et de l'ensemble de données sur les relations visuelles (VRD). Aux fins de leur étude, les chercheurs ont annoté les images de ces ensembles de données avec un ensemble de triplets, étiqueter chaque paire sujet/objet avec des informations de localisation.
"Les résultats d'expériences sur deux ensembles de données populaires démontrent que l'approche récurrente hiérarchique du point de vue visuel-orienté attention à l'intérieur de notre modèle a une nette amélioration des résultats par rapport aux modèles de base, " les chercheurs ont écrit. " Dans les travaux futurs, nous prévoyons d'enrichir le graphe de scène avec une sémantique de haut niveau et des attributs plus diversifiés."
© 2019 Réseau Science X