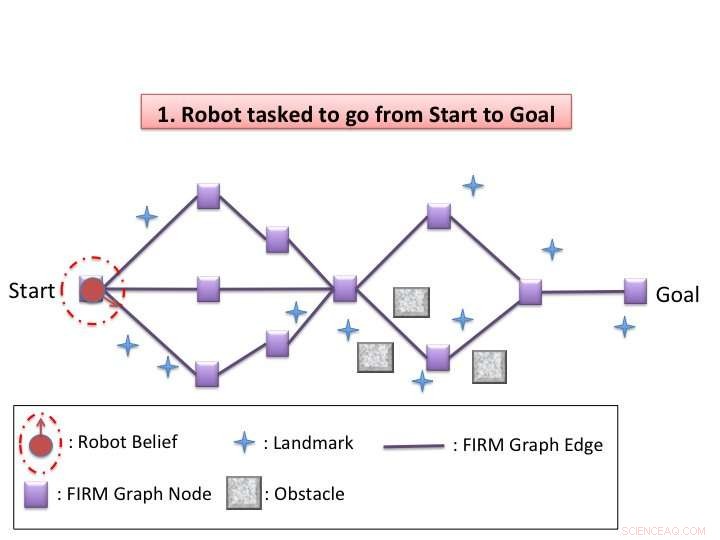
Illustration de l'algorithme. Crédit :Agha-mohammadi et al.
Des chercheurs du Jet Propulsion Laboratory (JPL) de la NASA, Université A&M du Texas, et l'Université Carnegie Mellon ont récemment mené un projet de recherche visant à activer les capacités de localisation et de planification simultanées (SLAP) dans les robots autonomes. Leur papier, Publié dans Transactions IEEE sur la robotique , présente un schéma de replanification dynamique dans l'espace de croyance, ce qui pourrait être particulièrement utile pour les robots fonctionnant dans l'incertitude, comme dans des environnements changeants.
"Les robots opérant dans le monde réel doivent faire face à l'incertitude, " Chanté Kyun Kim, l'un des chercheurs qui a mené l'étude a déclaré à TechXplore. "Par exemple, un rover martien doit naviguer vers des emplacements cibles scientifiques, mais il doit également éviter les collisions avec les obstacles. Ainsi, une localisation précise et une planification de chemin rentable sont des capacités essentielles."
SLAP est une capacité clé pour les robots autonomes qui fonctionnent dans l'incertitude, leur permettant de naviguer efficacement dans les espaces, éviter les obstacles, et planifier leur chemin vers les emplacements cibles. Le processus de prise de décision séquentiel d'un robot sous incertitude peut être formulé comme un POMDP (processus de décision de Markov partiellement observable), qui doit être continuellement résolu en ligne. Cependant, s'assurer que les robots résolvent efficacement et avec précision les POMDP peut être considérablement difficile.
"Nous avons proposé deux idées principales pour résoudre les problèmes SLAP, " Kim a expliqué. " L'une consiste à utiliser des contrôleurs de rétroaction pour rendre un état de croyance accessible. Cela peut effectivement briser la "malédiction de l'histoire, ' qui nous aide à résoudre des problèmes plus importants. L'autre est de replanifier et d'améliorer dynamiquement la décision au moment de l'exécution, améliorer la qualité et la robustesse de la solution. La replanification dynamique est particulièrement bénéfique lorsqu'il y a des erreurs de modélisation du système, changements d'environnement dynamiques, ou des pannes intermittentes de capteur/actionneur."

Exemple de rover de Mars. Crédit :NASA/JPL-Caltech.
Kim et ses collègues ont conçu un schéma de replanification dynamique dans l'espace de croyances qui permet aux robots de naviguer efficacement dans l'espace qui les entoure dans des situations d'incertitude, comme dans des environnements changeants ou face à des obstacles inattendus. Leur algorithme comporte deux phases, hors ligne et en ligne.
"Dans la phase hors ligne, notre algorithme construit un graphe clairsemé dans l'espace de croyance avec un contrôleur de rétroaction pour chaque nœud, puis résout la politique globale grossière (décidant quelle action entreprendre à l'état de croyance actuel) sur le graphe, " Kim a déclaré. "Dans la phase en ligne, une replanification dynamique est effectuée chaque fois que l'état de croyance est mis à jour. L'algorithme évalue localement chaque action de déplacement vers un nœud voisin sur le graphe et sélectionne celui avec le coût minimum. Après avoir exécuté l'action sélectionnée et mis à jour la croyance actuelle, il répète le processus de replanification."
Le schéma conçu par Kim et ses collègues exploite le comportement des contrôleurs de rétroaction dans l'espace de croyance. En d'autres termes, les contrôleurs de rétroaction agissent comme un entonnoir dans l'espace de croyance, avec un état de croyance proche convergeant potentiellement avec l'état de croyance cible de contrôle. Cela s'attaque efficacement à un problème clé dans la résolution des POMPD :la complexité exponentielle dans l'horizon de planification.
En réalité, une fois que la croyance actuelle de l'algorithme converge avec une croyance connue, il n'est pas nécessaire de considérer les actions et les observations menant à la croyance actuelle. Cela conduit finalement à une meilleure évolutivité, permettant aux robots de résoudre des problèmes de navigation plus complexes.
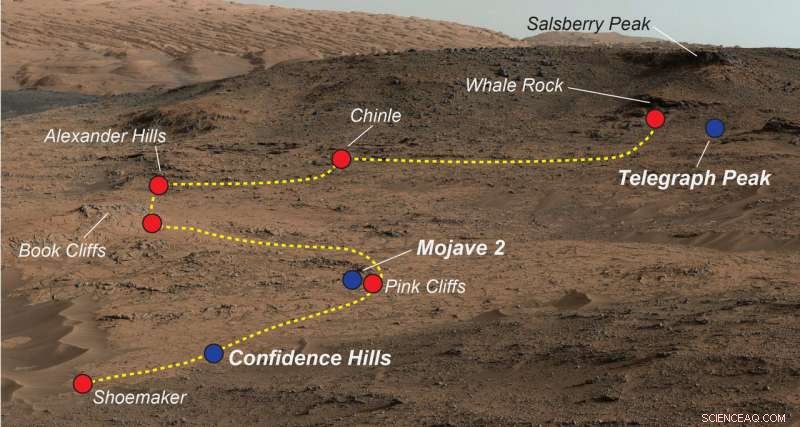
Exemple de rover de Mars. Crédit :NASA/JPL-Caltech/MSSS.
« Lors de la replanification dynamique, la méthode proposée amorce l'optimisation locale avec la politique globale (grossière), " Kim a déclaré. "Cela signifie qu'il peut prendre une décision non myope, contrairement à d'autres planificateurs en ligne avec un horizon fuyant fini. En bref, cette méthode peut s'adapter aux changements dynamiques de l'environnement et fonctionner de manière robuste malgré une perturbation ou des erreurs non modélisées, tout en faisant des plans rentables au sens global."
En éliminant les étapes de stabilisation inutiles, la méthode conçue par Kim et ses collègues a surpassé la feuille de route d'information basée sur la rétroaction (FIRM), une technique de pointe pour résoudre les POMDP. Dans le futur, ce schéma de replanification dynamique dans l'espace de croyances pourrait permettre de meilleures capacités SLAP dans les robots fonctionnant sous divers degrés d'incertitude.
"Nous prévoyons maintenant d'appliquer notre méthode à des problèmes du monde réel, ", a déclaré Kim. "Une application possible est un prototype de navigation et de coordination d'un hélicoptère-rover sur Mars pour l'exploration planétaire, un projet dirigé par le Dr Ali-akbar Agha-mohammadi au JPL. Un hélicoptère survolant le terrain pourrait fournir une carte approximative afin qu'une politique globale grossière puisse être obtenue dans la phase hors ligne. Ensuite, un rover se replanifierait dynamiquement dans la phase en ligne, pour accomplir des missions de navigation sûres et rentables."
© 2018 Tech Xplore