Planificateur de mouvement de conduite autonome basé sur les données sur la plate-forme Apollo. Crédit :Fan et al.
Des chercheurs de la multinationale chinoise de technologie Baidu ont récemment développé un cadre de réglage automatique basé sur les données pour les véhicules autonomes basé sur la plate-forme de conduite autonome Apollo. Le cadre, présenté dans un article pré-publié sur arXiv, se compose d'un nouvel algorithme d'apprentissage par renforcement et d'une stratégie d'entraînement hors ligne, ainsi qu'une méthode automatique de collecte et d'étiquetage des données.
Un planificateur de mouvement pour la conduite autonome est un système conçu pour générer une trajectoire sûre et confortable pour atteindre une destination souhaitée. Concevoir et régler ces systèmes pour s'assurer qu'ils fonctionnent bien dans différentes conditions de conduite est une tâche difficile à laquelle plusieurs entreprises et chercheurs du monde entier tentent actuellement de s'attaquer.
« La planification de mouvement pour les voitures autonomes pose de nombreux problèmes, " Fan Haoyang, l'un des chercheurs qui a mené l'étude, a déclaré Tech Xplore. "L'un des principaux défis est qu'il doit faire face à des milliers de scénarios différents. En règle générale, nous définissons un réglage fonctionnel récompense/coût qui peut adapter ces différences dans les scénarios. Cependant, nous trouvons que c'est une tâche difficile."
Typiquement, l'optimisation fonctionnelle du coût-récompense nécessite un travail approfondi de la part des chercheurs, ainsi que les ressources et le temps consacrés à la fois aux simulations et aux essais sur route. En outre, l'environnement peut changer considérablement au fil du temps et à mesure que les conditions de conduite deviennent plus compliquées, régler les performances du planificateur de mouvement devient de plus en plus difficile.

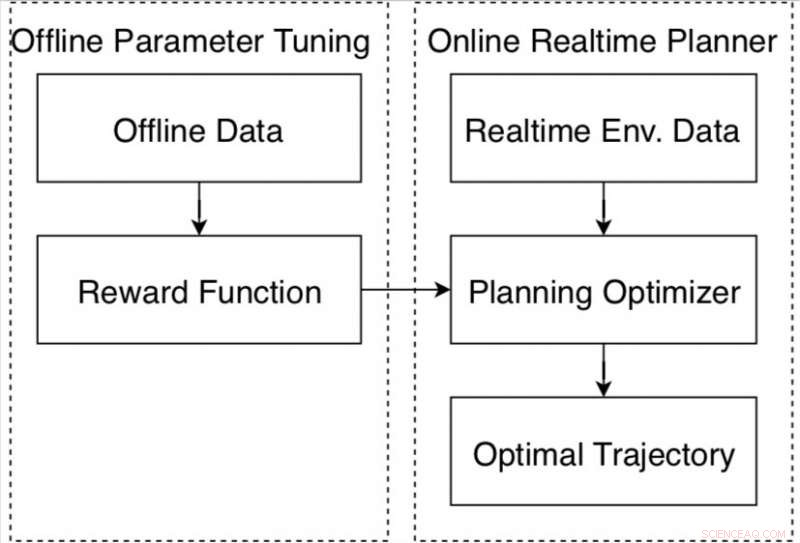
Boucle de réglage d'algorithme pour le planificateur de mouvement dans la plate-forme de conduite autonome Apollo. Crédit :Fan et al.
"Pour résoudre systématiquement ce problème, nous avons développé un cadre de réglage automatique basé sur les données basé sur le cadre de conduite autonome Apollo, " a déclaré Fan. " L'idée du réglage automatique est d'apprendre des paramètres à partir de données de conduite démontrées par l'homme. Par exemple, nous aimerions comprendre à partir des données comment les conducteurs humains équilibrent la vitesse et le confort de conduite avec les distances d'obstacles. Mais dans des scénarios plus compliqués, par exemple, une ville surpeuplée, que pouvons-nous apprendre des conducteurs humains ? »
Le cadre d'autoréglage développé chez Baidu comprend un nouvel algorithme d'apprentissage par renforcement, qui peut apprendre des données et améliorer ses performances au fil du temps. Par rapport à la plupart des algorithmes d'apprentissage par renforcement inverse, il peut être appliqué efficacement à différents scénarios de conduite.
Le cadre comprend également une stratégie de formation hors ligne, offrant aux chercheurs un moyen sûr d'ajuster les paramètres avant qu'un véhicule autonome ne soit testé sur la voie publique. Il collecte également des données auprès de conducteurs experts et des informations sur l'environnement, les étiquetant automatiquement afin qu'ils puissent être analysés par l'algorithme d'apprentissage par renforcement.
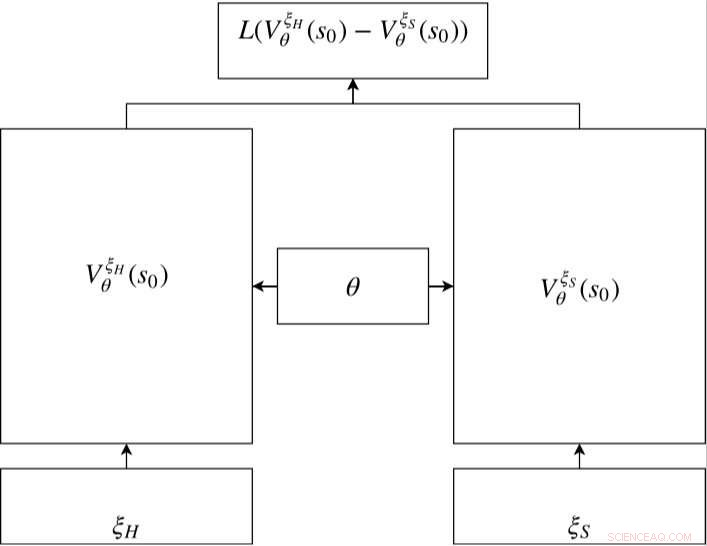
Réseau siamois en RC-IRL. Les réseaux de valeurs des trajectoires humaines et échantillonnées partagent les mêmes paramètres de réseau. La fonction de perte évalue la différence entre les données échantillonnées et la trajectoire générée via les sorties du réseau de valeurs. Crédit :Fan et al.
"Je pense que nous avons développé un pipeline sûr pour créer un système évolutif d'apprentissage automatique en utilisant des données de démonstration humaine, " Fan a déclaré. "Les données de démonstration humaine en boucle ouverte sont collectées et ne nécessitent pas d'étiquetage supplémentaire. Étant donné que le processus de formation est également hors ligne, notre méthode est adaptée à la planification de mouvement de conduite autonome, maintenir la sécurité des essais sur route publique."
Les chercheurs ont évalué un planificateur de mouvement réglé à l'aide de leur cadre à la fois sur des simulations et des tests sur la voie publique. Par rapport aux approches existantes, leur méthode data-driven s'est mieux adaptée aux différents scénarios de conduite, performant de manière constante dans diverses conditions.
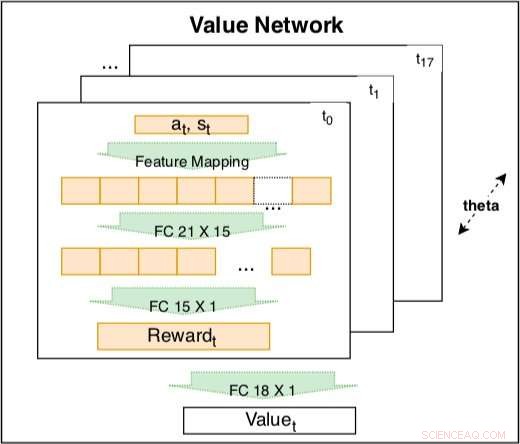
Le réseau de valeur à l'intérieur du modèle siamois est utilisé pour capturer le comportement de conduite sur la base de caractéristiques codées. Le réseau est une combinaison linéaire entraînable de récompenses codées à différents instants t =t0, ..., t17. Le poids de la récompense encodée est un facteur de décroissance du temps pouvant être appris. La récompense codée comprend une couche d'entrée avec 21 caractéristiques brutes et une couche cachée avec 15 nœuds pour couvrir les interactions possibles. Les paramètres de la récompense à différents moments partagent le même pour maintenir la cohérence. Crédit :Fan et al.
"Notre recherche est basée sur la plate-forme de conduite autonome Baidu Apollo Open Source, " a déclaré Fan. "Nous espérons que de plus en plus de personnes du monde universitaire et de l'industrie pourront contribuer à l'écosystème de conduite autonome via Apollo. Dans le futur, nous prévoyons d'améliorer le cadre actuel de Baidu Apollo en un système évolutif d'apprentissage automatique qui peut systématiquement améliorer la couverture des scénarios des voitures à conduite autonome."
© 2018 Tech Xplore