Crédit :Gerlach et al.
Chercheurs de l'Université Northwestern, l'Université de Bath, et l'Université de Sydney ont développé une nouvelle approche en réseau des modèles thématiques, des stratégies d'apprentissage automatique qui peuvent découvrir des sujets abstraits et des structures sémantiques dans des documents texte.
"L'un des principaux défis informatiques et scientifiques de l'ère moderne est d'extraire des informations utiles à partir de textes non structurés, ", ont expliqué les chercheurs dans leur étude. "Les modèles thématiques sont une approche d'apprentissage automatique populaire qui déduit la structure thématique latente d'une collection de documents."
Des modèles thématiques sont actuellement utilisés pour identifier des textes liés sémantiquement et classer les documents dans un certain nombre de domaines, dont la sociologie, l'histoire, linguistique, et la psychologie. La méthode la plus couramment utilisée, allocation de Dirichlet latente (LDA), est également utilisé pour la bibliométrie, analyse psychologique et politique, ainsi que pour le traitement d'images.
Malgré son succès généralisé, LDA présente plusieurs défauts dans la façon dont il représente le texte, comme un manque de méthode pour choisir le nombre de sujets, des divergences avec les propriétés statistiques des textes réels et un manque de justification du prior bayésien, qui, dans l'inférence statistique bayésienne, est la distribution de probabilité exprimée avant la présentation des preuves.
Crédit :Gerlach et al.
Une grande partie des recherches récentes sur les modèles thématiques se sont concentrées sur la création de versions plus sophistiquées de LDA qui fonctionnent mieux ou peuvent analyser efficacement des aspects particuliers des documents.
L'approche développée par cette équipe de chercheurs est issue de la théorie des réseaux, une théorie utilisée en physique et dans d'autres domaines scientifiques qui fournit des techniques d'analyse de graphiques, ainsi que des structures dans des systèmes avec différents agents en interaction. Leur nouveau cadre de modélisation thématique est basé sur l'approche utilisée pour trouver des communautés dans des réseaux complexes, lequel, dans le cadre de la théorie des réseaux, est un graphique avec des caractéristiques qui se produisent dans la modélisation de systèmes réels.
"Je travaillais sur le langage naturel et la modélisation thématique du point de vue des systèmes complexes et des réseaux complexes, " Martin Gerlach, un boursier postdoctoral à l'Université Northwestern a déclaré à TechXplore. "Les problèmes semblaient très similaires, pourtant, les communautés de l'informatique (modélisation thématique) et des réseaux complexes semblaient fonctionner en grande partie de manière indépendante. Être formé en tant que physicien, nous voulions montrer que deux problèmes apparemment différents pouvaient être réduits aux mêmes mathématiques sous-jacentes."
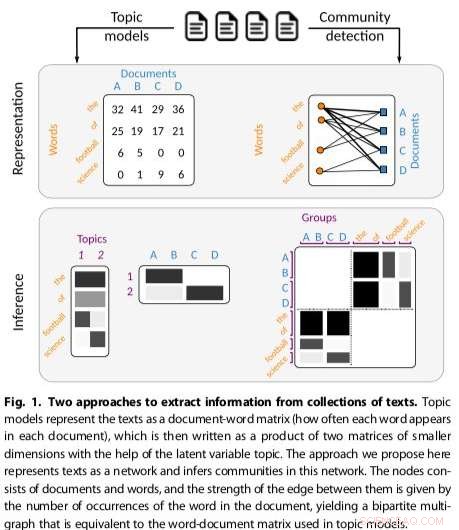
Gerlach et ses collègues ont conçu une nouvelle approche pour identifier les structures thématiques liées au problème de trouver des communautés dans des réseaux complexes. Leur technique représente les corpus textuels comme des réseaux bipartites, une classe de réseaux complexes qui divisent les nœuds en ensembles X et Y, autorisant uniquement les connexions entre les nœuds de différents ensembles.
Crédit :Gerlach et al.
"Nous avons mappé le problème de la modélisation thématique au problème de la détection de communauté dans un réseau constitué de mots et de documents montrant qu'ils sont mathématiquement équivalents, " expliqua Gerlach.
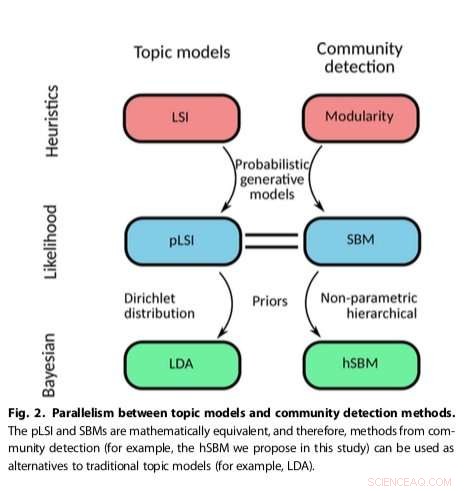
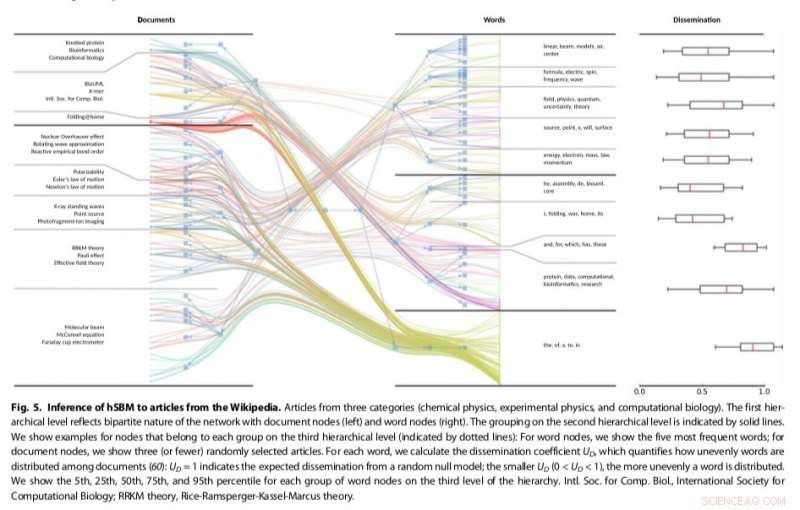
L'approche des chercheurs, qui adapte les méthodes de détection communautaire existantes, s'est avéré plus polyvalent et fondé sur des principes que les autres modèles thématiques existants, par exemple détecter le nombre de sujets présents dans les textes et regrouper hiérarchiquement à la fois les mots et les documents. Leur méthode a utilisé un modèle de bloc stochastique (SBM), un modèle génératif de graphes qui cartographie généralement les communautés, sous-ensembles d'éléments connectés les uns aux autres.
"Nous résolvons certains des problèmes intrinsèques et connus des algorithmes de modélisation de sujets populaires tels que LDA (par exemple, comment déterminer le nombre de sujets), " dit Gerlach. " De plus, notre travail montre comment relier formellement les méthodes de détection de communauté et de modélisation thématique, ouvrant la possibilité d'une fertilisation croisée entre ces deux domaines."
L'approche SBM développée par Gerlach et ses collègues pourrait avoir des applications intéressantes dans d'autres domaines où l'apprentissage automatique est utilisé, comme l'analyse de codes génétiques ou d'images. Dans le futur, les chercheurs prévoient de continuer à explorer le potentiel des réseaux complexes à la fois dans le contexte de l'analyse de texte et au-delà.
"L'équivalence entre modélisation thématique et détection de communauté permet d'utiliser les connaissances acquises dans chacune des communautés et de les appliquer à l'autre domaine, " a déclaré Gerlach. " J'espère utiliser ces informations pour mieux comprendre ces algorithmes d'apprentissage automatique; pourquoi ils travaillent, et plus important, dans quelles conditions ils ne fonctionnent pas.
© 2018 Tech Xplore














