Comparaison des classements de concepts pour un rapport de Human Rights Watch. La colonne « Vérité sur le terrain » montre les huit personnes les plus fréquemment mentionnées dans le rapport « Crise humanitaire au Venezuela », tandis que les autres colonnes affichent les valeurs renvoyées par diverses méthodes de découverte. Les valeurs qui font partie des concepts de vérité terrain sont indiquées par des cases sombres . La méthode context renvoie des valeurs qui sont toutes pertinentes (même si elles sont absentes de l'article d'origine), alors que la méthode de cooccurrence renvoie de nombreux concepts populaires mais non pertinents (par exemple, politiciens faisant des déclarations générales sur le sujet). Crédit :IBM
Chez IBM Research AI, nous avons construit une solution basée sur l'IA pour aider les analystes à préparer des rapports. L'article décrivant ce travail a récemment remporté le prix du meilleur article lors du volet « In-Use » de l'Extended Semantic Web Conference (ESWC) de 2018.
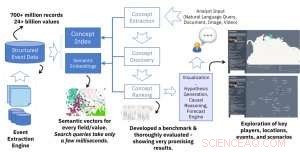
Les analystes sont souvent chargés de préparer des rapports complets et précis sur des sujets donnés ou des questions de haut niveau, qui peuvent être utilisés par les organisations, entreprises, ou des agences gouvernementales pour prendre des décisions éclairées, réduire le risque associé à leurs projets futurs. Pour préparer ces rapports, les analystes doivent identifier des sujets, personnes, organisations, et les événements liés aux questions. Par exemple, afin de préparer un rapport sur les conséquences du Brexit sur les marchés financiers de Londres, un analyste doit être au courant des principaux sujets connexes (par exemple, Marchés financiers, économie, Brexit, loi sur le divorce du Brexit), personnes et organisations (p. L'Union européenne, les décideurs de l'UE et du Royaume-Uni, personnes impliquées dans les négociations sur le Brexit), et événements (par exemple, Réunions de négociation, élections législatives au sein de l'UE, etc.). Une solution assistée par l'IA peut aider les analystes à préparer des rapports complets et également à éviter les biais basés sur l'expérience passée. Par exemple, un analyste peut passer à côté d'une source d'information importante si elle n'a pas été utilisée efficacement dans le passé.
L'équipe d'induction des connaissances d'IBM Research AI a conçu la solution à l'aide d'un apprentissage en profondeur et de données d'événements structurées. L'équipe, dirigé par Alfio Gliozzo, a également remporté le prestigieux prix Semantic Web Challenge l'année dernière.
Incorporations sémantiques à partir de bases de données d'événements
La principale nouveauté technique de ce travail est la création de plongements sémantiques à partir de données d'événements structurées. L'entrée de notre moteur d'intégration sémantique est une grande source de données structurée (par exemple, tables de base de données avec des millions de lignes) et la sortie est une grande collection de vecteurs avec une taille constante (par exemple, 300) où chaque vecteur représente le contexte sémantique d'une valeur dans les données structurées. L'idée de base est similaire à l'idée populaire et largement utilisée des inclusions de mots dans le traitement du langage naturel, mais au lieu de mots, nous représentons des valeurs dans les données structurées. Le résultat est une solution puissante permettant une recherche sémantique rapide et efficace dans différents domaines de la base de données. Une seule requête de recherche ne prend que quelques millisecondes, mais récupère les résultats en fonction de l'exploration de centaines de millions d'enregistrements et de milliards de valeurs.
Alors que nous avons expérimenté divers modèles de réseaux de neurones pour la construction d'intégrations, nous avons obtenu des résultats très prometteurs en utilisant une simple adaptation du modèle word2vec original de skip-gram. Il s'agit d'un modèle de réseau de neurones peu profond efficace basé sur une architecture qui prédit le contexte (mots environnants) donné à un mot dans un document. Dans notre travail, nous n'avons pas affaire à des documents texte mais à des enregistrements de bases de données structurées. Pour ça, nous n'avons plus besoin d'utiliser une fenêtre glissante de taille fixe ou aléatoire pour capturer le contexte. Dans les données structurées, le contexte est défini par toutes les valeurs d'une même ligne quelle que soit la position de la colonne, puisque deux colonnes adjacentes dans une base de données sont aussi liées que deux autres colonnes. L'autre différence dans nos paramètres est la nécessité de capturer différents champs (ou colonnes) dans la base de données. Notre moteur doit permettre à la fois les requêtes sémantiques générales (c'est-à-dire, renvoie toute valeur de base de données liée à la valeur donnée) et des valeurs spécifiques au champ (c'est-à-dire, renvoie les valeurs d'un champ donné liées à la valeur d'entrée). Pour ça, nous attribuons un type aux vecteurs construits à partir de chaque champ et construisons un index qui prend en charge les requêtes spécifiques au type ou génériques.
Crédit :IBM
Pour le travail décrit dans notre article, nous avons utilisé trois bases de données d'événements accessibles au public en entrée :GDELT, ICEWS, et EventRegistry. Globalement, ces bases de données se composent de centaines de millions d'enregistrements (objets JSON ou lignes de base de données) et de milliards de valeurs dans divers champs (attributs). En utilisant notre moteur d'embeddings, chaque valeur se transforme en un vecteur représentant le contexte dans les données.
Une simple requête de récupération
On peut voir à quel point le contexte est capturé par notre moteur à l'aide d'une simple requête de récupération. Par exemple, lors de la recherche de la valeur "Hilary Clinton" (mal orthographié) dans le champ "person" dans GDELT GKG, le premier résultat ou le vecteur le plus similaire est "Hilary Clinton" (mal orthographié) sous le champ "nom" et les prochains vecteurs les plus similaires sont "Hillary Clinton" (orthographe correcte) sous les champs "personne" et "nom". Cela est dû au contexte très similaire de la valeur mal orthographiée et de l'orthographe correcte, ainsi que les valeurs des champs "nom" et "personne". Le reste des résultats pour la requête ci-dessus incluent des politiciens américains, notamment ceux actifs lors des dernières élections présidentielles, ainsi que les organisations connexes, personnes ayant occupé des postes similaires dans le passé, et les membres de la famille.
Recherche de similarité sur des requêtes combinées
Bien sûr, notre solution est capable d'accomplir bien plus qu'une simple requête de récupération. En particulier, on peut combiner ces requêtes pour transformer un ensemble de valeurs extraites d'une requête en langage naturel en un vecteur et effectuer une recherche de similarité. Nous avons évalué les résultats de cette approche à l'aide d'un benchmark construit à partir de rapports rédigés par des experts humains, et examiné la capacité de notre moteur à renvoyer les concepts décrits dans les rapports en utilisant le titre du rapport comme seule entrée. Les résultats ont clairement montré la supériorité de notre approche de découverte de concept basée sur les plongements sémantiques par rapport à une approche de base reposant uniquement sur la co-occurrence des valeurs.
De nouvelles applications dans la découverte de concepts
Un aspect très intéressant de notre cadre est que toute valeur et tout champ se voit attribuer un vecteur représentant son contexte, ce qui permet de nouvelles applications intéressantes. Par exemple, nous avons intégré les coordonnées de latitude et de longitude des événements dans les bases de données dans le même espace sémantique de concepts, et a travaillé avec le Visual AI Lab dirigé par Mauro Martino pour créer un cadre de visualisation qui met en évidence les emplacements connexes sur une carte géographique à partir d'une question en langage naturel. Une autre application intéressante que nous étudions actuellement consiste à utiliser les concepts récupérés et leurs intégrations sémantiques en tant que fonctionnalités pour un modèle d'apprentissage automatique que l'analyste doit construire. Cela peut être utilisé dans un moteur d'apprentissage automatique et de science des données (AutoML), et soutenir les analystes dans un autre aspect important de leur travail. Nous prévoyons d'intégrer cette solution dans Scenario Planning Advisor d'IBM, un système d'aide à la décision pour les analystes des risques.
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.